訓練不了人工智慧?你可以訓練你自己
核心的概念在於不訓練模型參數的前提下,透過優化輸入(Prompt)來強化語言模型的能力。
模型的角色定位:新人助理
- 一般能力:大型語言模型具備一般人的基本知識與理解能力。
- 「新」的含義:它對使用者一無所知(如身分證字號、背景等),反應不符預期往往是因為資訊不足。
- 溝通方式:不需特定格式,只要能講到讓「人」看得懂,模型就有機會看懂。

強化方法一:神奇咒語 (Magic Spells)
這些咒語能激發模型潛力,但效果視模型版本而定。
思維鏈 (Chain of Thought, CoT)
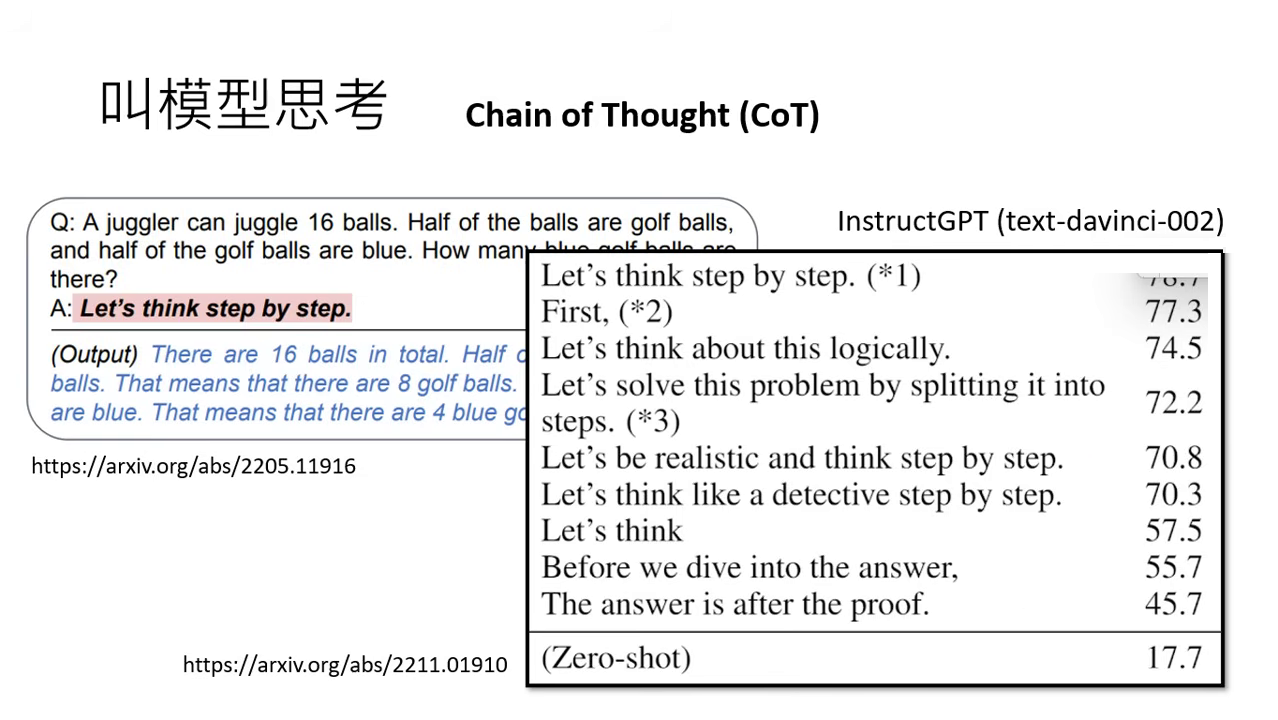
- 核心指令:叫模型思考,例如加入 「Let's think step by step」。
- 成效:在舊版模型(如 Text DaVinci 002)解數學題時,正確率可從 17.7% 提升至 78%。
- 現狀:新版模型(如 GPT-3.5)即便不加咒語也具備基礎思考能力,咒語帶來的進步幅度已縮小。
要求解釋答案
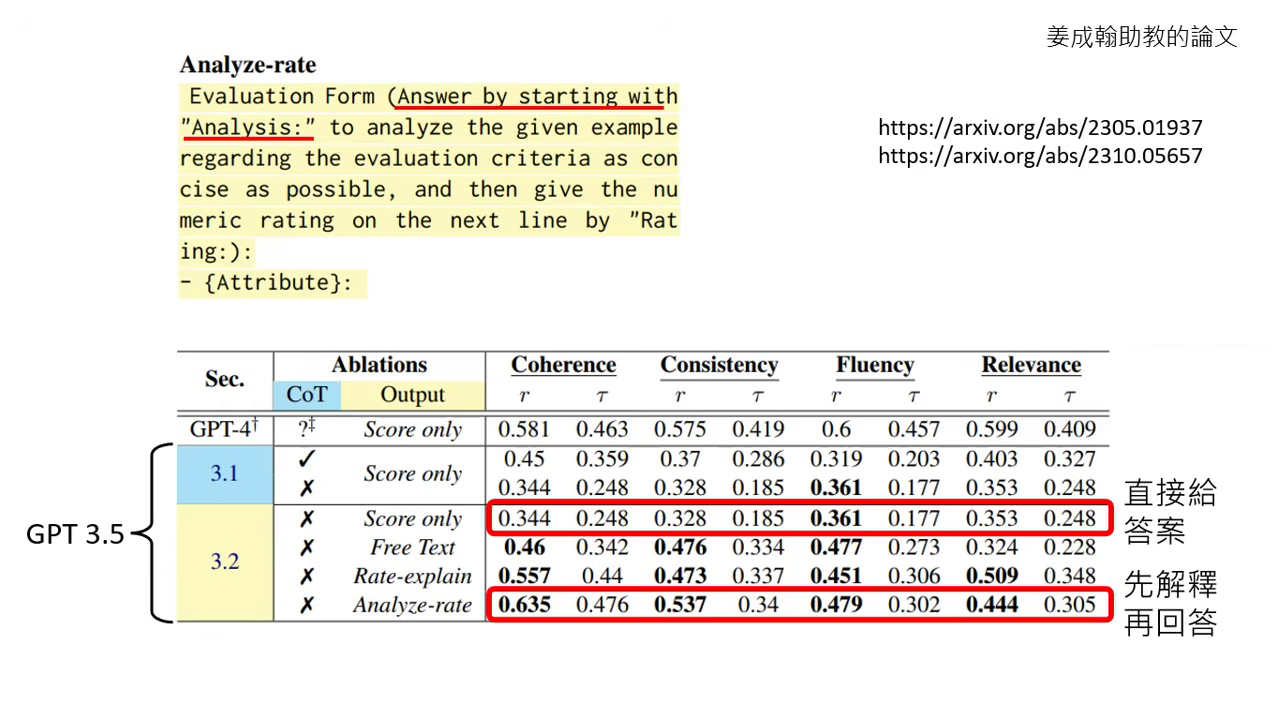
- 指令:請模型先解釋原因再給答案。
- 優點:在批改文章等任務中,先解釋能讓評分結果與人類老師更接近,提升準確度。
情緒勒索 (Emotional Stimuli)
- 指令:告訴模型 「這對我的生涯非常重要」。
- 實驗結果:在多個模型測試中,正確率皆有顯著提升。

其他神奇咒語的測試結果
- 有禮貌無用:說「請」或「謝謝」不會讓答案更正確,直說要求即可。
- 正面指令:明確告知「要做什麼」,而非「不要做什麼」。
- 獎懲機制:承諾給予「小費」或告知不正確會受罰是有影響力的。

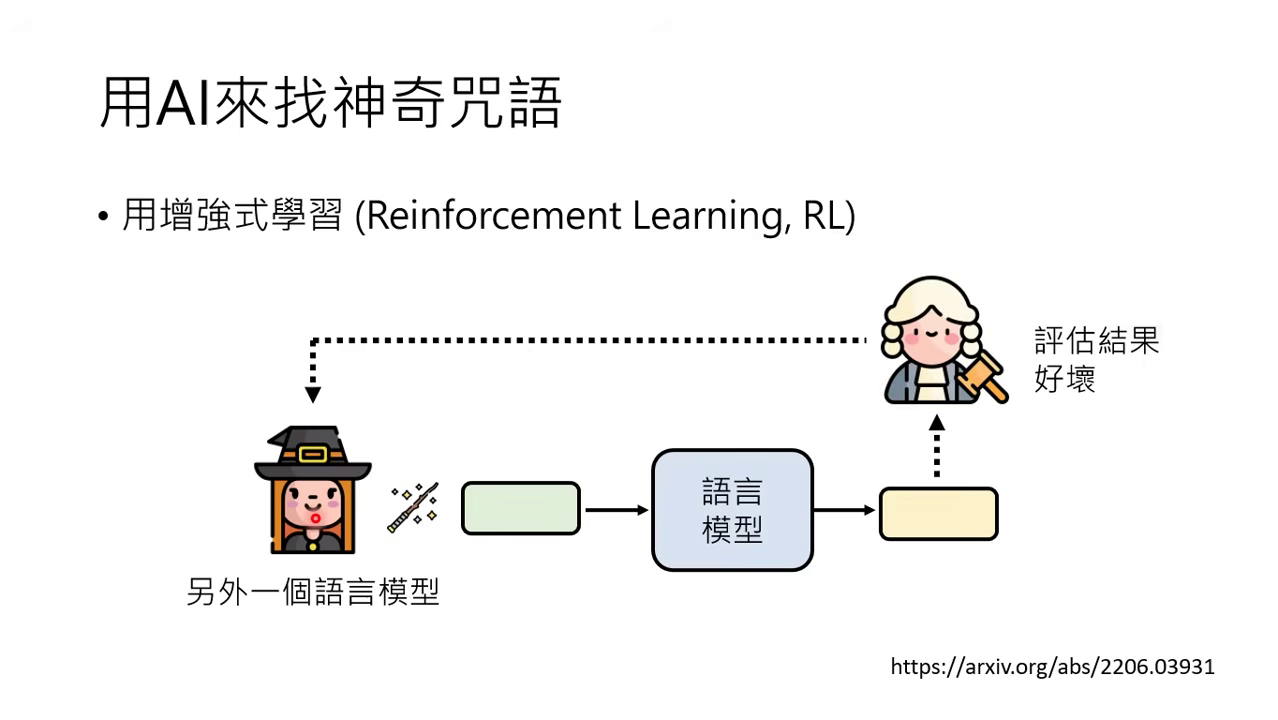
如何找咒語
- AI 找咒語:利用增強式學習 (RL) 讓模型自動尋找最有效的控制指令(如讓 GPT-3 變話嘮的咒語是「喂喂喂」)。
- 直接問模型:詢問模型「有什麼咒語可以強化你的能力」,它會提供如「take a deep breath」等建議。
強化方法二:提供更多資訊 (Providing More Information)
當模型表現不佳,往往是因為前提不清或缺乏相關知識。
釐清前提 (釐清歧義)
- 範例:詢問「NTU」時,告知模型「你是台灣人」或「你是新加坡人」,模型能正確區分台大與南洋理工大學。

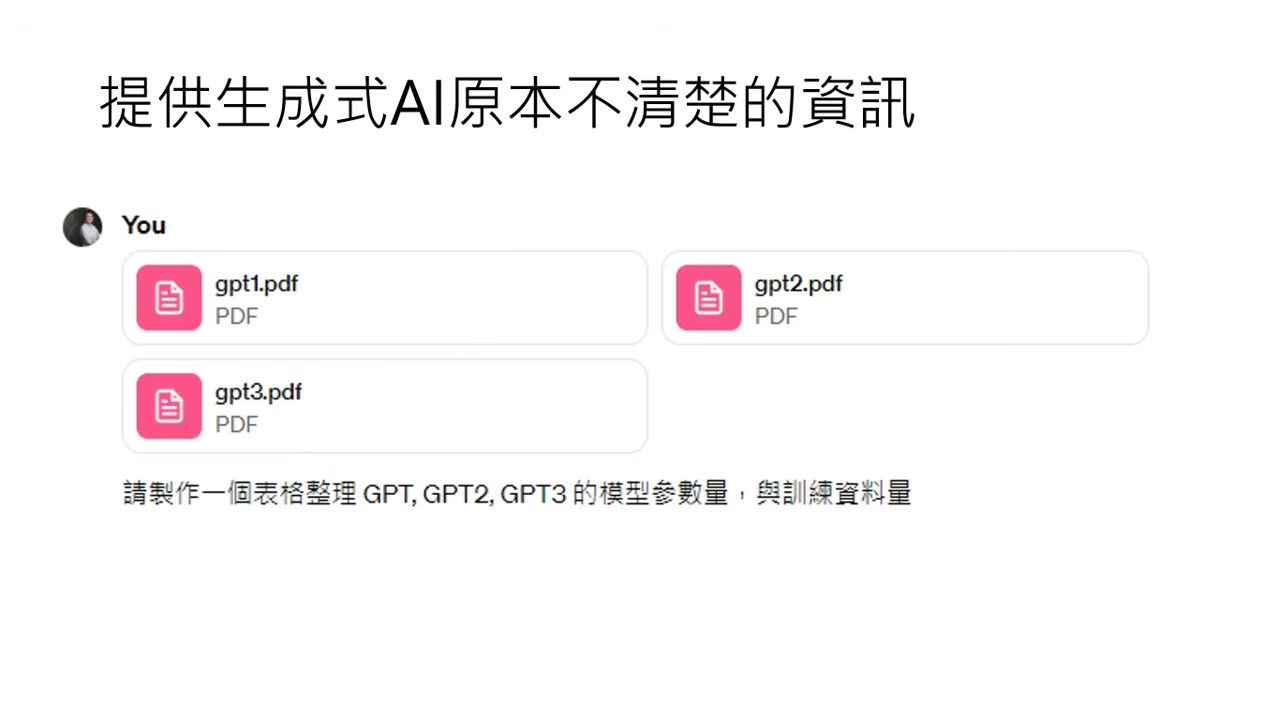
餵食資料 (知識補充)
- 操作:直接將模型不知道的資料(如最新論文 PDF)貼給模型讀,它能精確畫出原本無法提供的數據表格。
提供範例:上下文學習 (In-context Learning)**:
- 定義:在輸入中提供範例,讓模型模仿格式與邏輯。
- 強大模型的理解力:
- 早期觀點認為模型只是看懂格式,而非邏輯。
- 2023 年後的強大模型(如 PALM 540B、GPT-4)能真正讀懂範例,甚至能因應怪異的指令(如將政治新聞分類為財經)進行處理。
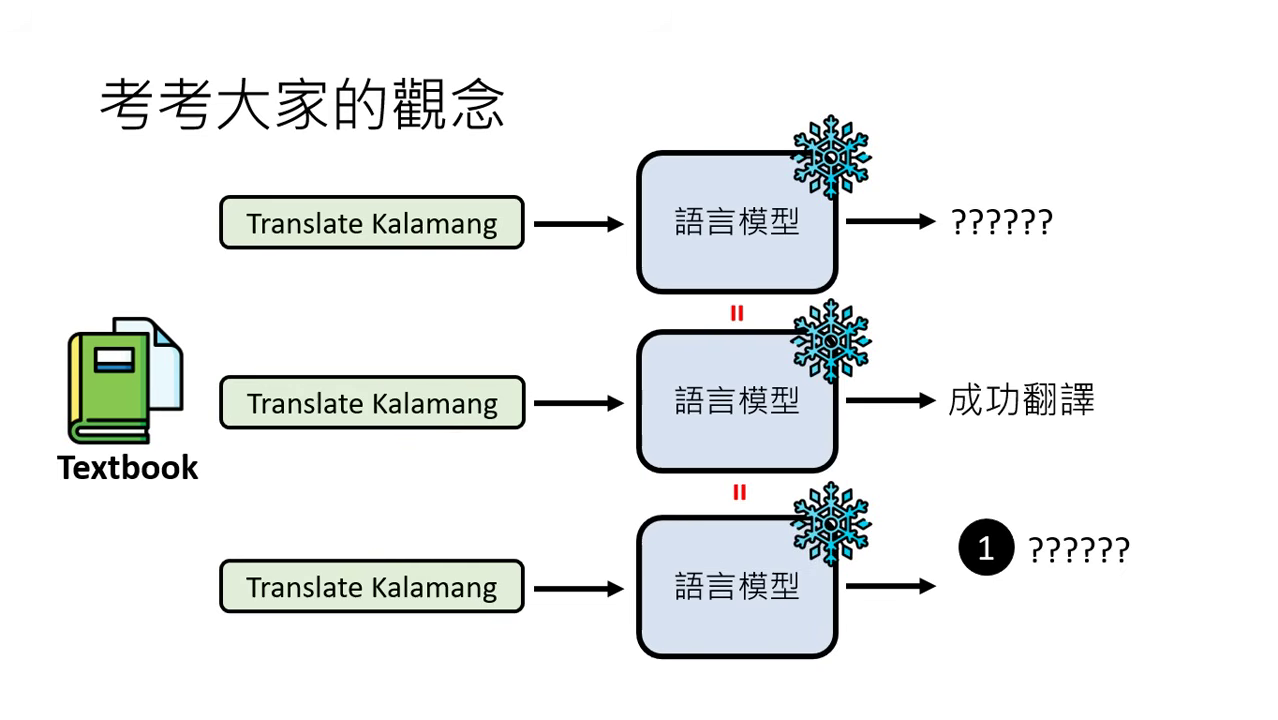
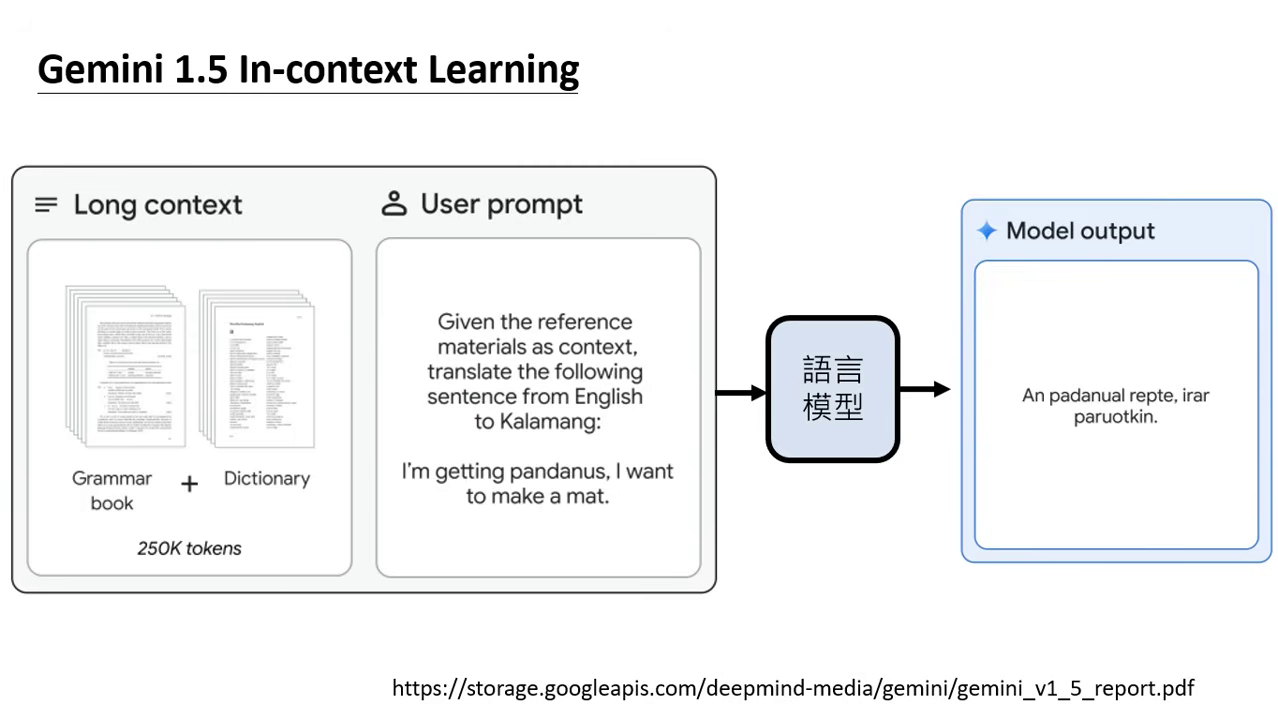
- Gemini 1.5 實測:提供卡拉蒙�語的教科書(25 萬字),模型在完全未學過該語言的情況下,能讀完後學會翻譯。
強化方法三:拆解問題 (Breaking Down Tasks)
當任務過於複雜時,語言模型往往難以一次到位地給出正確答案。將大任務拆解成小步驟,能讓模型對每一個步驟「各個擊破」。

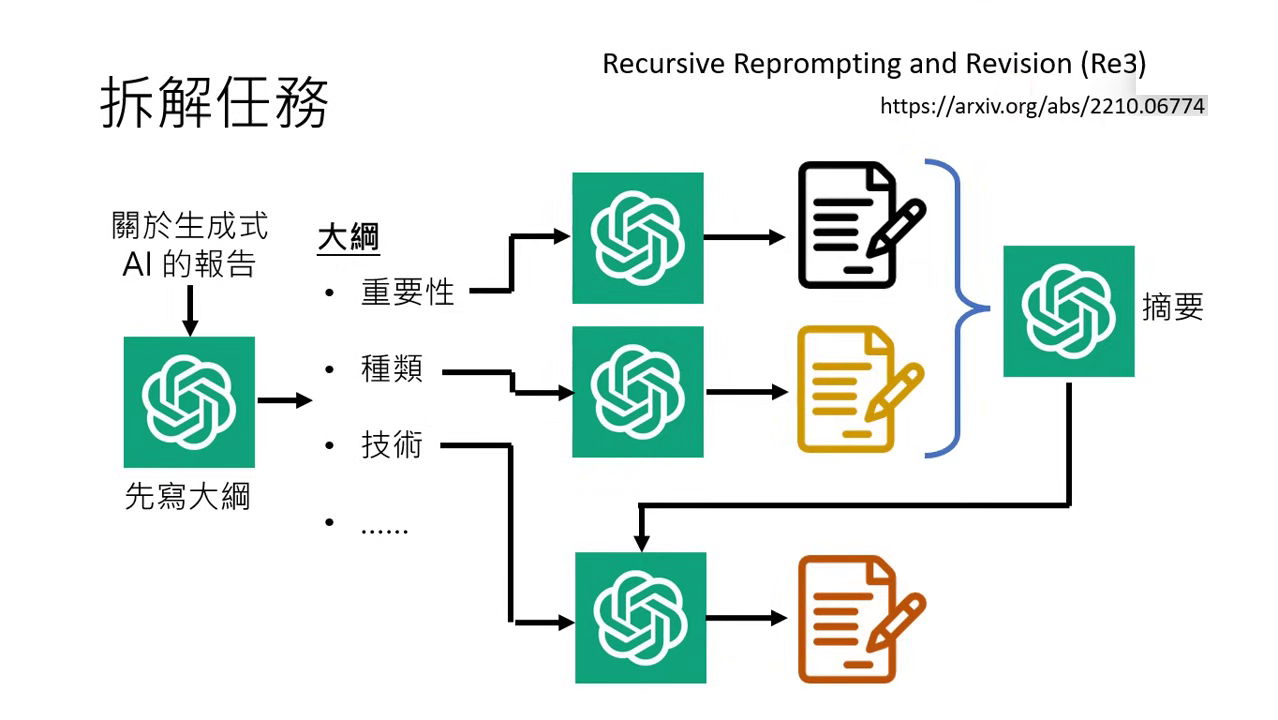
拆解任務 (Task Decomposition)
- 分階段執行:以撰寫長篇報告為例,應先請模型列出大綱(如:重要性、種類、技術剖析),再針對各章節分開撰寫。
- 摘要銜接:分段撰寫時,模型可能遺忘前文,此時可將已完成的部分進行摘要,作為撰寫新段落的參考,以確保內容前後連貫(Recursive Reprompting and Revision)。
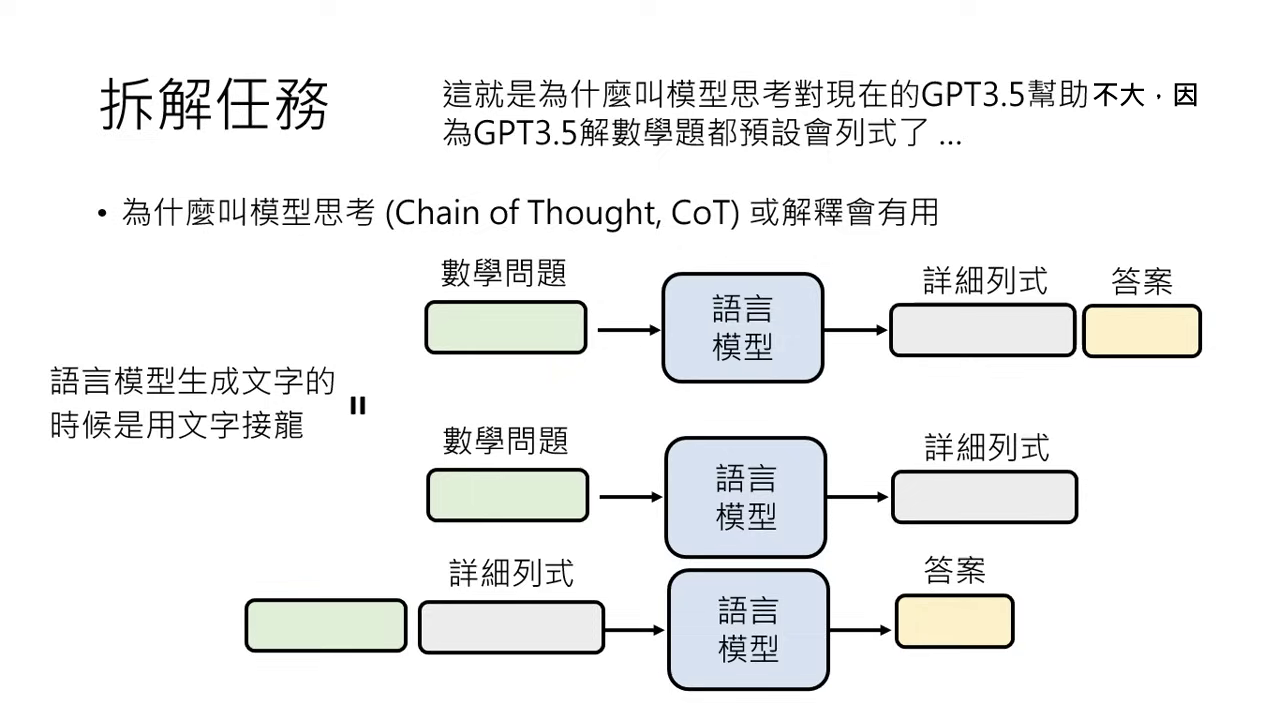
思維鏈 (Chain of Thought, CoT)
- 核心機制:要求模型「一步步思考」(Think step by step),本質上是將解題拆成「列出詳細計算過程」與「產出答案」兩個步驟。
- 文字接龍的作用:當模型先產出詳細的算式或邏輯,後續產出的答案便是基於這些已出現的正確式子進行「文字接龍」,精確度大幅提升。
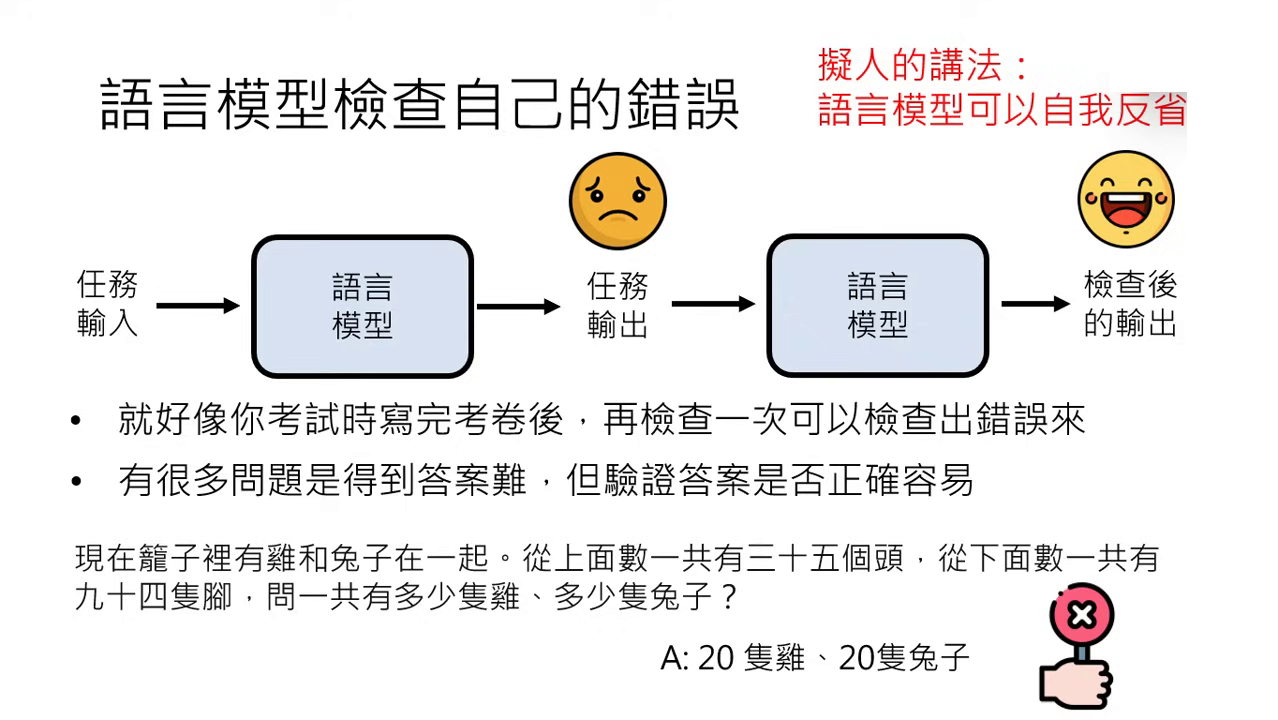
自我反省與檢查 (Self-Reflection)
- 驗證易於求解:計算答案可能很難,但驗證答案是否正確相對容易。
- 實例與對比:
- GPT-4:具備強大的自我修正能力。例如叫它介紹「台大玫瑰花節」(事實上不存在),它會先瞎掰,但被要求檢查時會察覺錯誤並修正。
- GPT-3.5:較容易出現「口是心非」的道歉,雖然道歉但更正後的資訊可能與原本一模一樣,並未真正發現錯誤。
- 憲法 AI (Constitutional AI):透過自我批判來確保輸出符合道德規範。模型會先產生直覺答案(如如何駭入 Wi-Fi),再進��行自我審查(是否違法),最後產出反省後符合規範的回答。
 |  |
|---|---|
| 自我反省與檢查 | Constitutional AI |
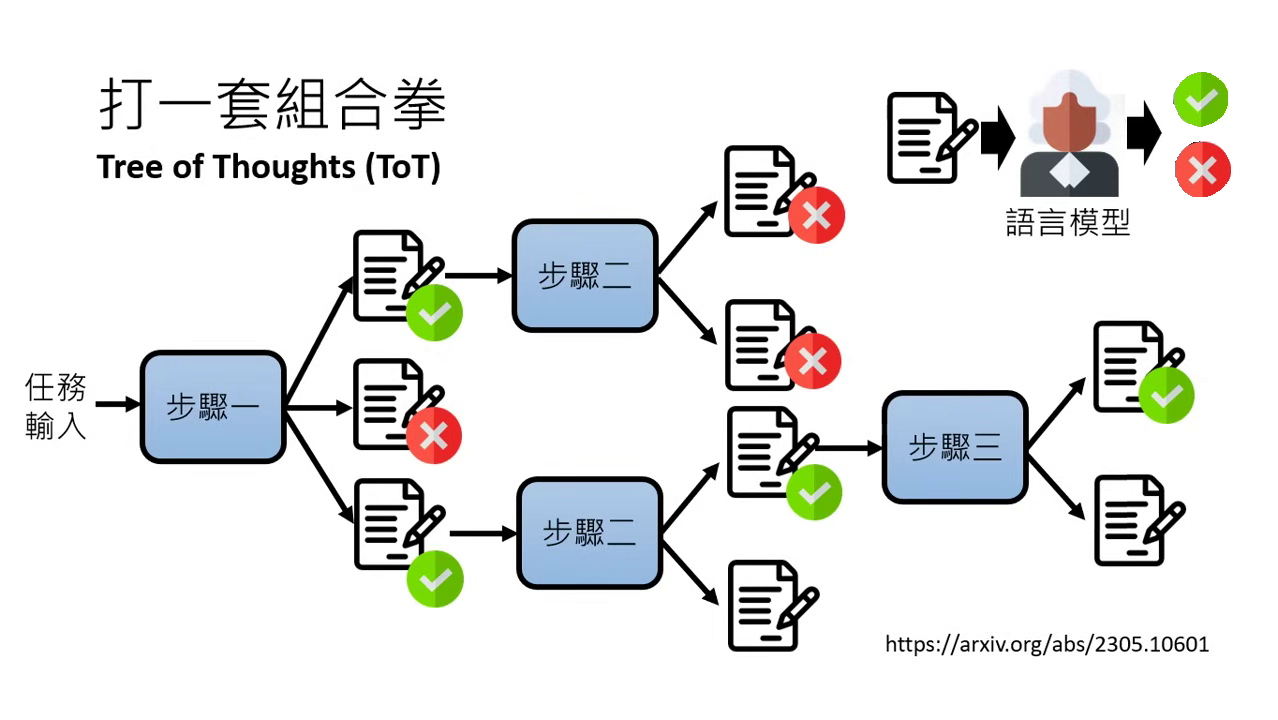
自我一致性與思維樹 (Self-Consistency & Tree of Thoughts)
- Self-Consistency:對同一個問題重複擲多次骰子(請求多次),取最常出現的答案作為結果。
- Tree of Thoughts (ToT):一種組合技。在每個拆解步驟中產生多個答案,並透過自我反省檢查對錯,若發現錯誤則退回上一步(Backtracking)尋找新路徑,直到得到終極解答。
 |  |
|---|---|
| Self-Consistency | Tree of Thoughts (ToT) |
強化方法四:提供工具 (Using Tools)
語言模型雖然強大,但也有不擅長的事(如:精密運算、即時資訊)。透過工具的輔助,可以強化其各項能力。
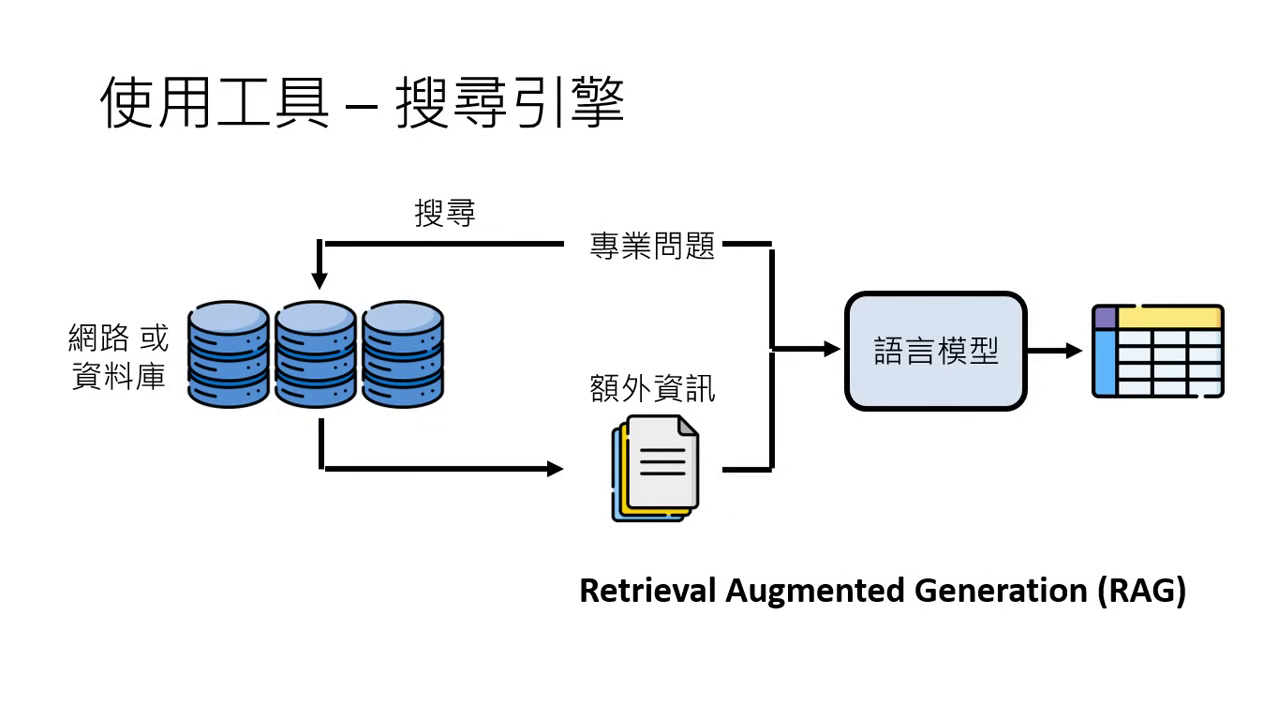
搜尋引擎 (RAG - Retrieval Augmented Generation)
- 對抗幻覺:語言模型本質是文字接龍,並沒有內建即時資料庫,因此會對未見過的資訊(如 Sora)產生瞎掰的現象。
- 運作邏輯:
- 將問題拿去搜尋(網路或特定私有資料庫)。
- 取得搜尋結果作為「額外資訊」。
- 將問題與搜尋內容拼接在一起,交給語言模型去做文字接龍,產出精確且具參考來源的答案。
寫程式與執行 (Program of Thought)
- 解決數學問題:與其用文字接龍硬算,模型可以選擇寫出一段程式碼並呼叫 Solver(解題模組)來運算,避免在計算過程中產生人類不可能犯的錯誤。
- 精確輸出:例如叫 GPT-4 說「哈哈」100 次,它會寫一段 Python 程式碼來精確執行,確保輸出正好是 300 個哈字。

多媒體工具調用 (DALL-E)
- 工具調用:大型語言模型(如 GPT-4)可以呼叫 DALL-E 進行文字生圖。
- 賀卡產生應用:此技術可應用於自動產生龍年賀年卡,模型會顯示「Creating images」字樣代表正在呼叫工具。
- 實務建議與技巧:
- 細節檢查:雖然 AI 產生的龍看起來有模有樣,但有時會出現怪異細節,例如鬍鬚長在頭上變成「呆毛」,需定睛觀察才能發現。
- 避短指令:由於 AI 產生的圖片內容若包含文字(尤其是中文)容易出現拼錯或亂碼,建議在指令中特別強調「圖上不要出現文字」,以確保賀卡品質。

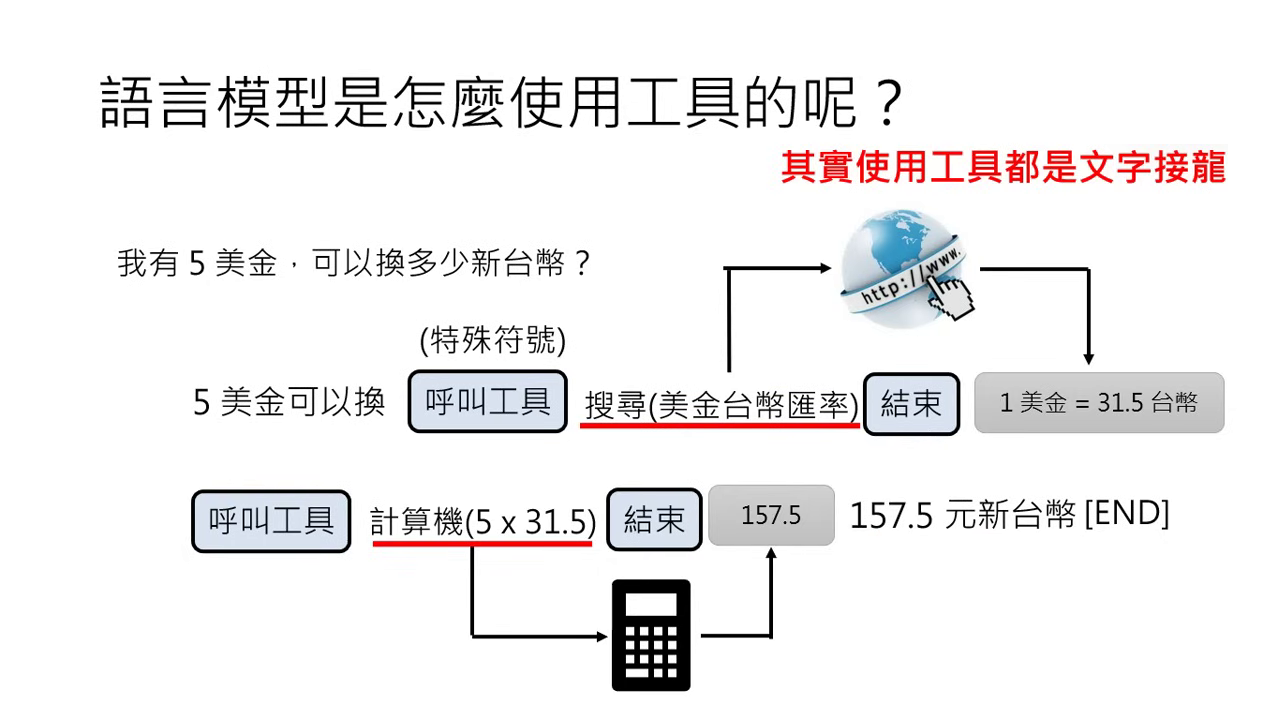
運作機制:如何「使用」工具?
- 文字接龍式調用:模型透過輸出特殊的預定義符號來代表呼叫工具(例如:
搜尋[關鍵字])。 - 資訊回傳:符號間的內容即為操作指令。工具執行後的結果(如匯率查詢、程式運行結果)會被貼回到對話框中,模型再根據這些新資訊繼續接龍。
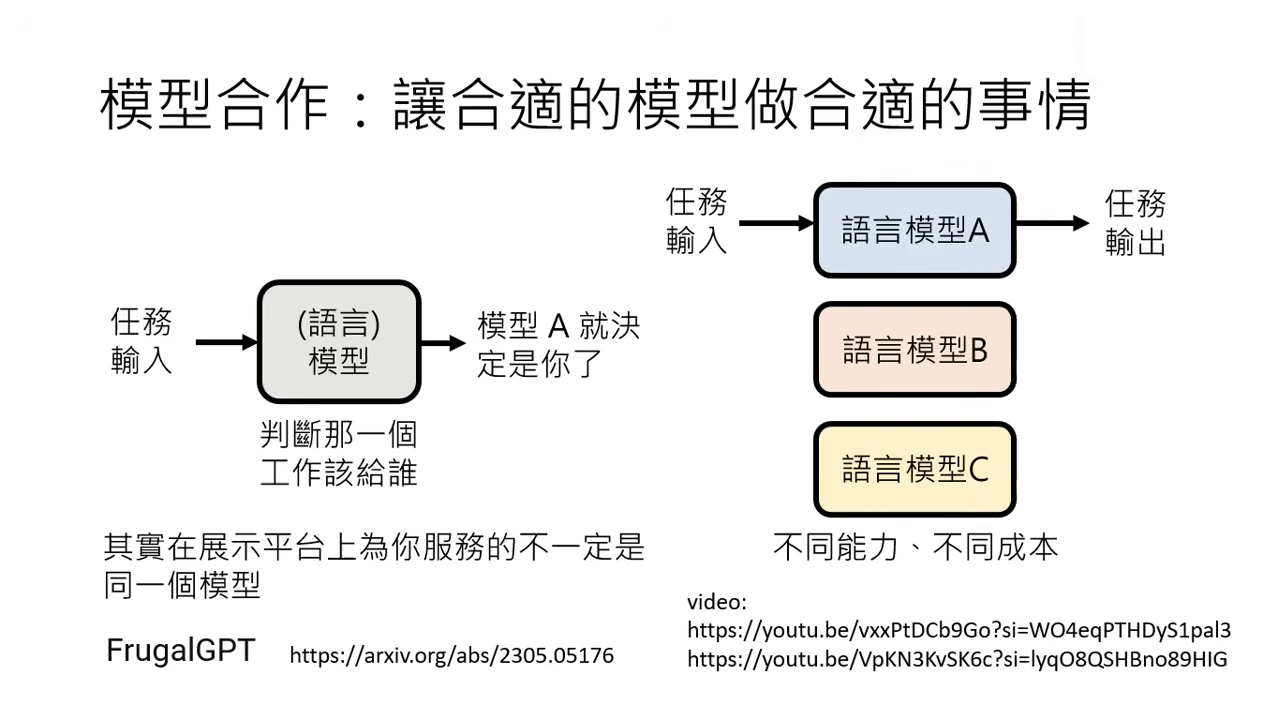
強化方法五:模型合作 (Multi-model Cooperation)

模型合作的核心理念:1 + 1 > 2
- 合作的重要性:即使是像 GPT-4 這樣強大的模型,透過與其他語言模型合作,也能發揮出更強的力量。
- 成本與效率優化:
- 不同模型有不同的能力與使用成本(如 GPT-4 貴、GPT-3.5 便宜)。
- 可以引入一個分配工作的模型(語言模型或非語言模型皆可),判斷任務難易度。
- 殺雞焉用牛刀:簡單任務交給便宜模型處理,困難任務才交給 GPT-4,藉此在維持效果的同時大幅降低成本。
- 相關技術:FrugalGPT。
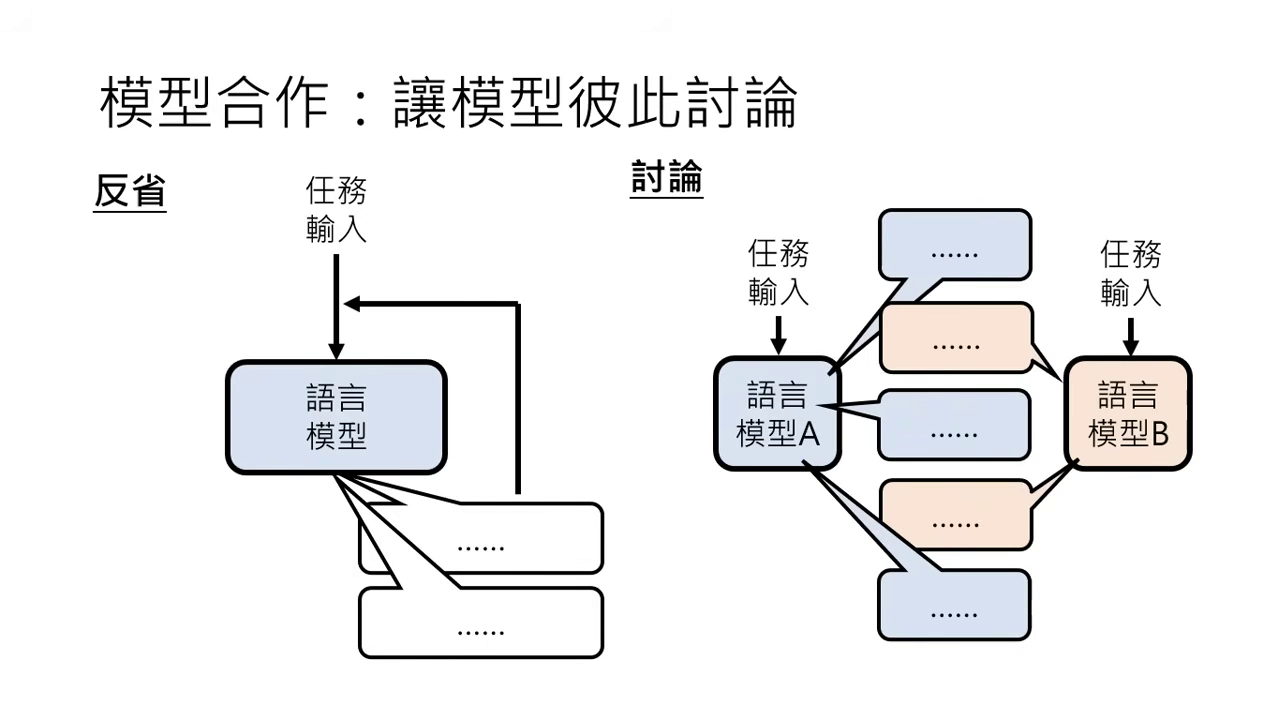
讓模型彼此「討論」 (Model Discussion)
- 反省 vs. 討論:
- 反省 (Self-Reflection):模型自問自答,推翻前一個答案的可能性較低,因為它傾向認同自己的觀點。
- 討論 (Multi-model Discussion):多個模型互動,能接受到新的刺激與不同輸入,更有機會推翻並修正之前的錯誤答案。
- 關鍵因素:
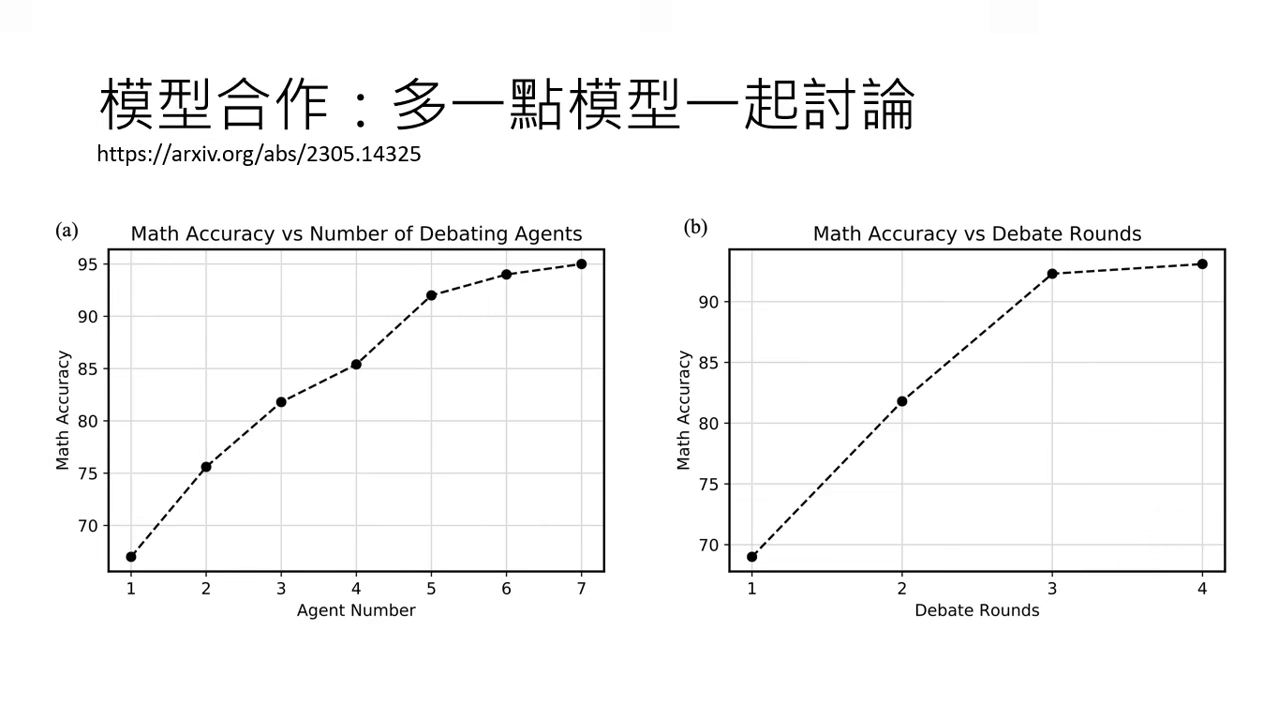
- 數量與回合數:參與討論的模型越多、討論回合數越多(目前實驗約 3~4 回合最有效),正確率通常越高。
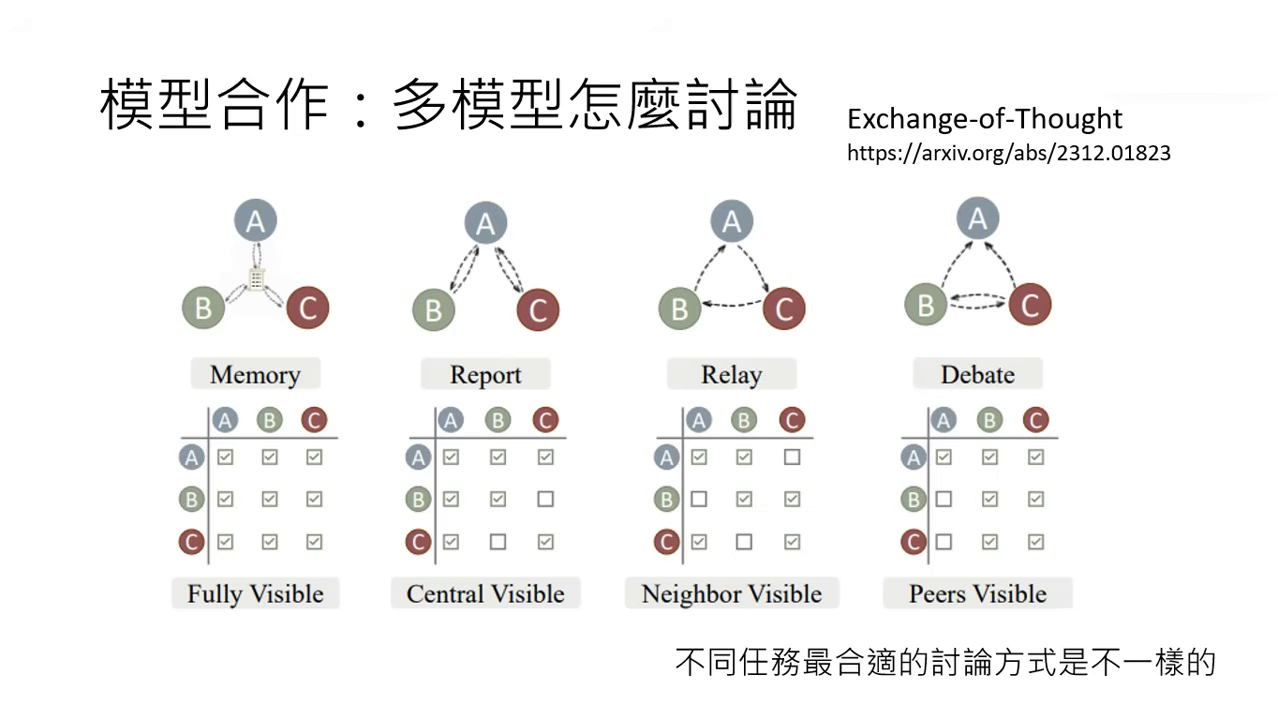
- 討論方式 (Exchange of Thought):包含「所有人都看所有人的答案」、「老闆與部屬(部屬只向老闆報告)」或「辯論與裁判」等多元形式。
 |  |
|---|---|
| 多一點模型一起討論 | 討論方式 |
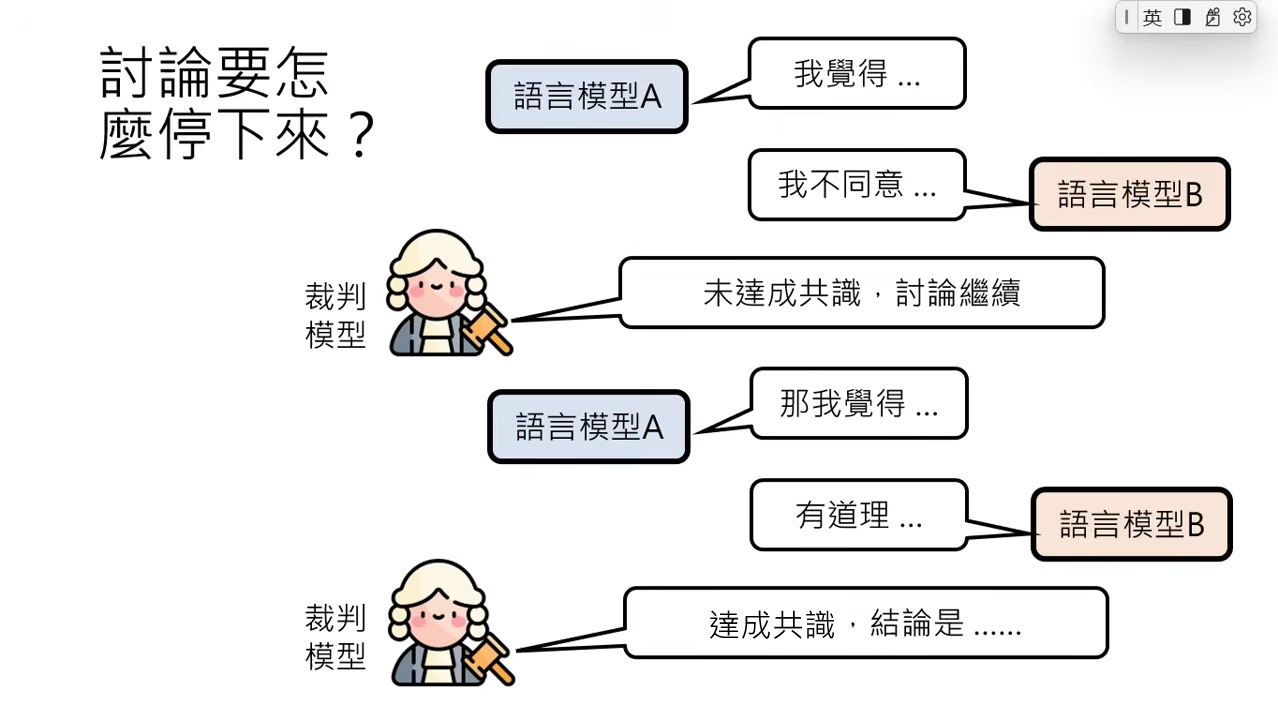
討論的終止機制與裁判模型
- 裁判模型 (Referee Model):
- 負責讀取不同模型的建議,判斷彼此是否達成共識。
- 若未達成共識,則指令繼續討論;若達成共識,則負責做出摘要並產出最終答案。
- 克服「溫良恭儉讓」的性格:
- 模型在訓練中被教導要禮貌,容易因為被質疑而退縮,導致討論過快結束。
- Prompt 技巧:需使用強烈指令刺激模型,例如「不需要一定同意對方的想法」或「對方的看法當作參考即可」,以維持討論的深度。
 |  |
|---|---|
| 裁判模型 (Referee Model) | Prompt 技巧 |
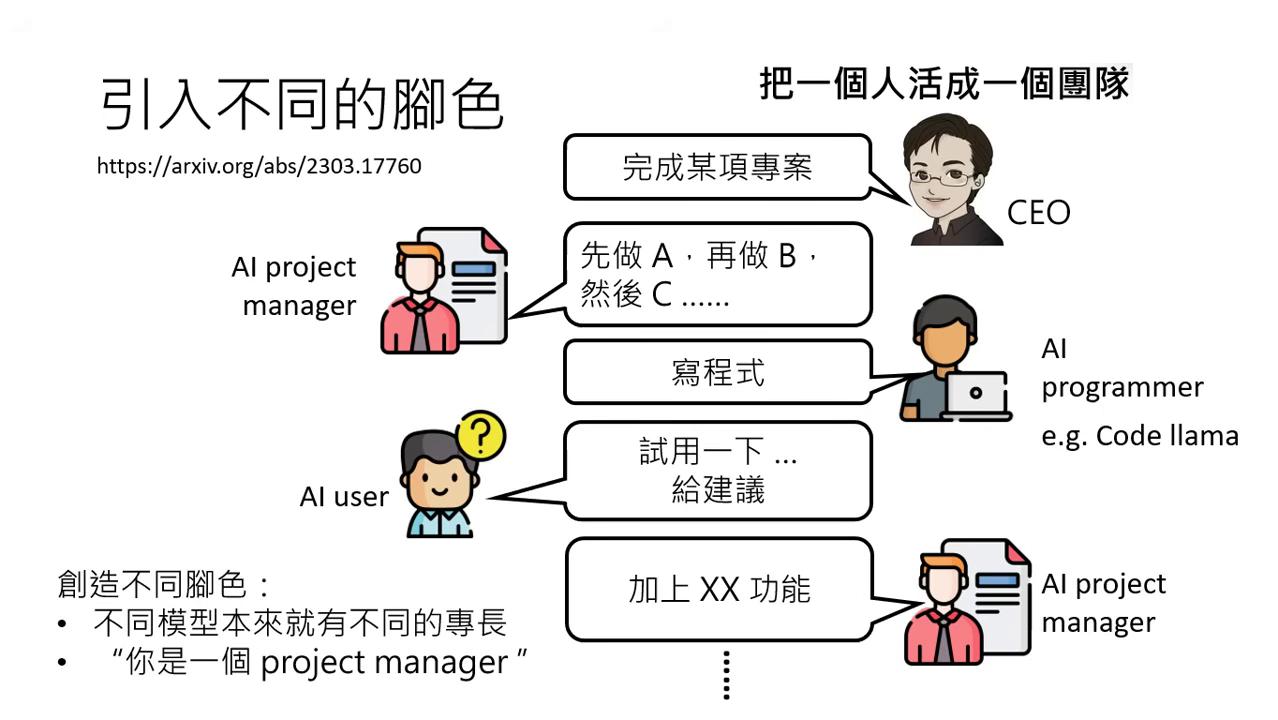
組建 AI 團隊:引入不同的角色
- 角色賦予方式:
- 專業模型:使用具備特定專長的模型,如 Code Llama 專精於寫程式。
- 指令賦予 (Prompting):透過 Prompt 讓模型扮演不同角色(如:專案經理、工程師、測試員)。
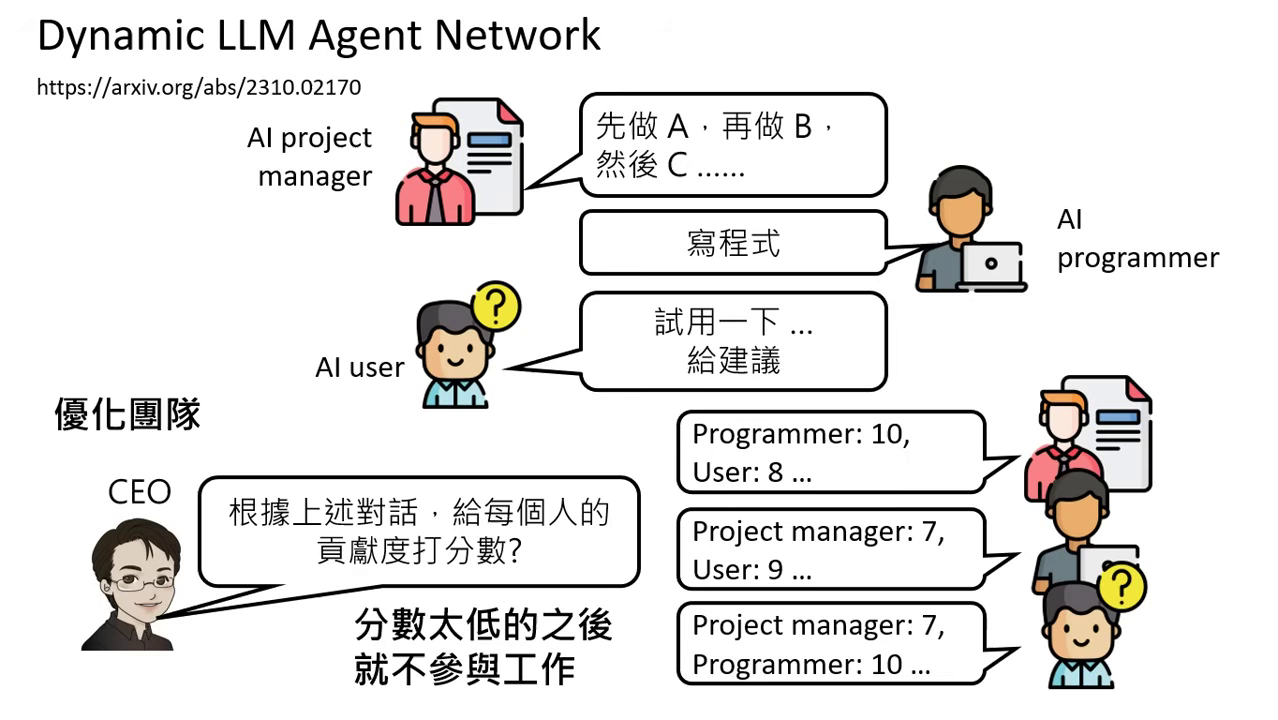
- 團隊優化與考績系統:
- 打考績 (Dynamic LLM Agent Network):讓模型彼此互給分數,分數低的模型未來將不被允許參與工作,藉此優化團隊品質。
- 開源專案實例:如 MetaGPT 或 ChatDev,它們能模擬一家軟體公司的運作,雖然解決真實世界複雜任務仍有難度,但已展示出自動化開發的潛力。
 |  |
|---|---|
| 引入不同的腳色 | 打考績 (Dynamic LLM Agent Network) |
關鍵觀念澄清
- 參數固定不變:上述所有強化方法皆沒有訓練模型,模型的參數是固定的,僅是輸入改變了。
- 無記憶效應:In-context Learning 產生的能力不具備持久性。若開啟新的對話且不提供相同資訊,模型會回到原本的狀態(不會保留學會的特殊知識)。