大型語言模型的推理過程不用太長、夠用就好
推理長度 vs. 正確率:越長真的越好嗎?
迷思與觀察
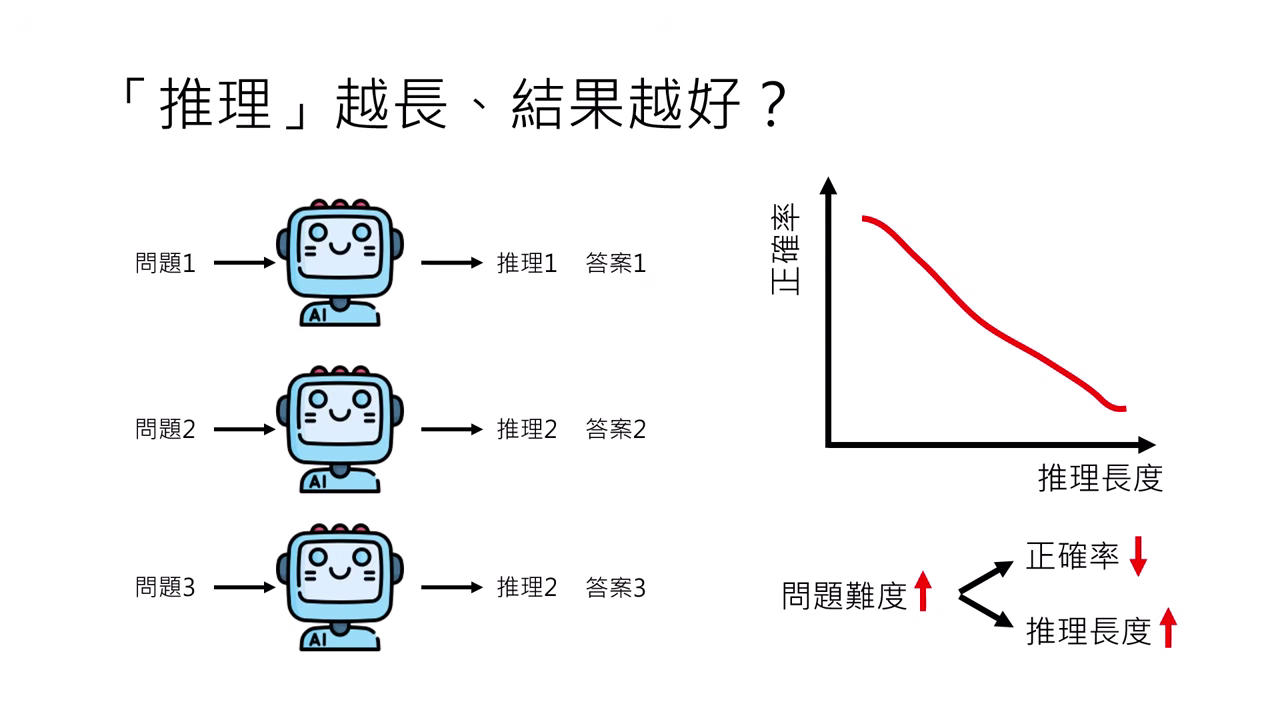
- 過去觀點認為推理過程越長,結果可能越好。但許多實驗數據顯示,推理長度與正確率往往呈現負相關(越長越容易錯)。
- 潛在因素:這不代表長度導致錯誤,而是因為「問題本身較難」才導致模型需要想比較久,而難題本身的正確率本來就低。
嚴謹實驗驗證 (AIME 案例)
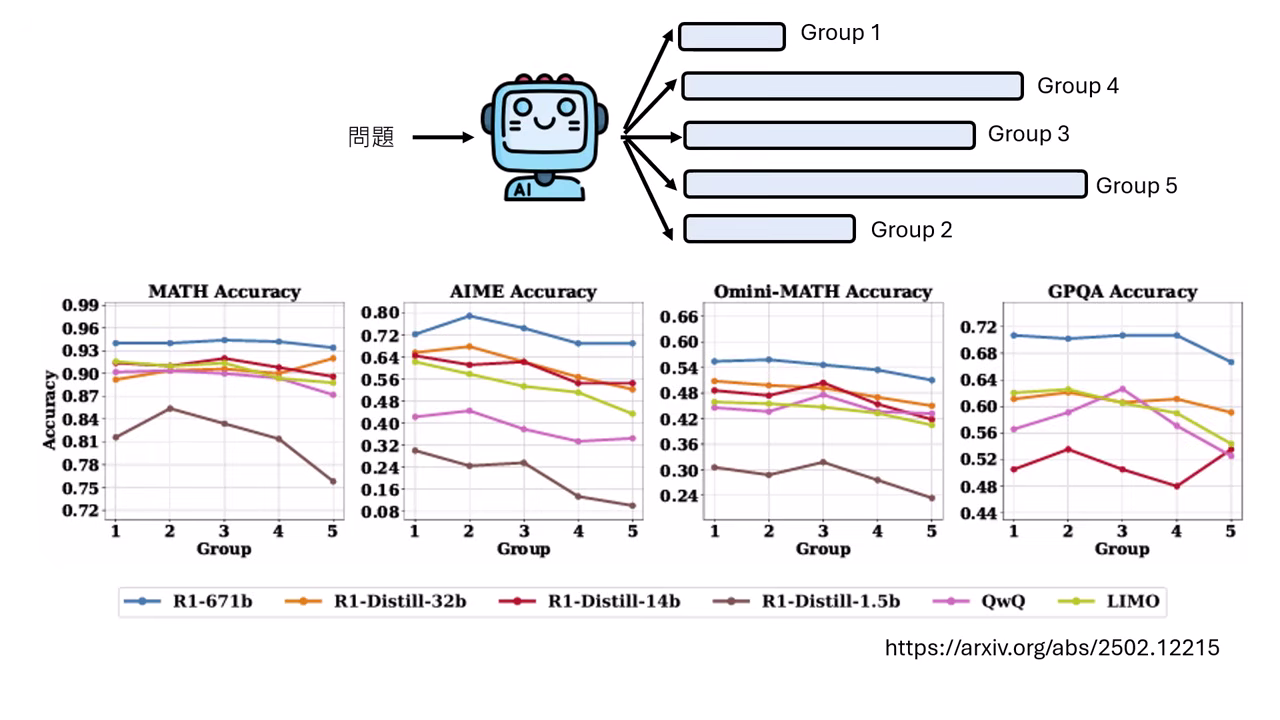
- 為了排除題目難度干擾,研究者對同一個模型問同一個問題五次,並將產生的答案依長度分組(Group 1 最短 ~ Group 5 最長)。
- 結果:即使是同個問題,推理長度最長的那一組(Group 5),其正確率並沒有比最短的那一組(Group 1)高。這證明了冗長的推理往往是沒有必要的。
- 核心哲學:最好的工程師(或 AI)不是把事情做到完美,而是在有限資源(算力)下把事情做到最好。若能用較短的推理得到正確答案,就不應浪費算力去長篇大論。
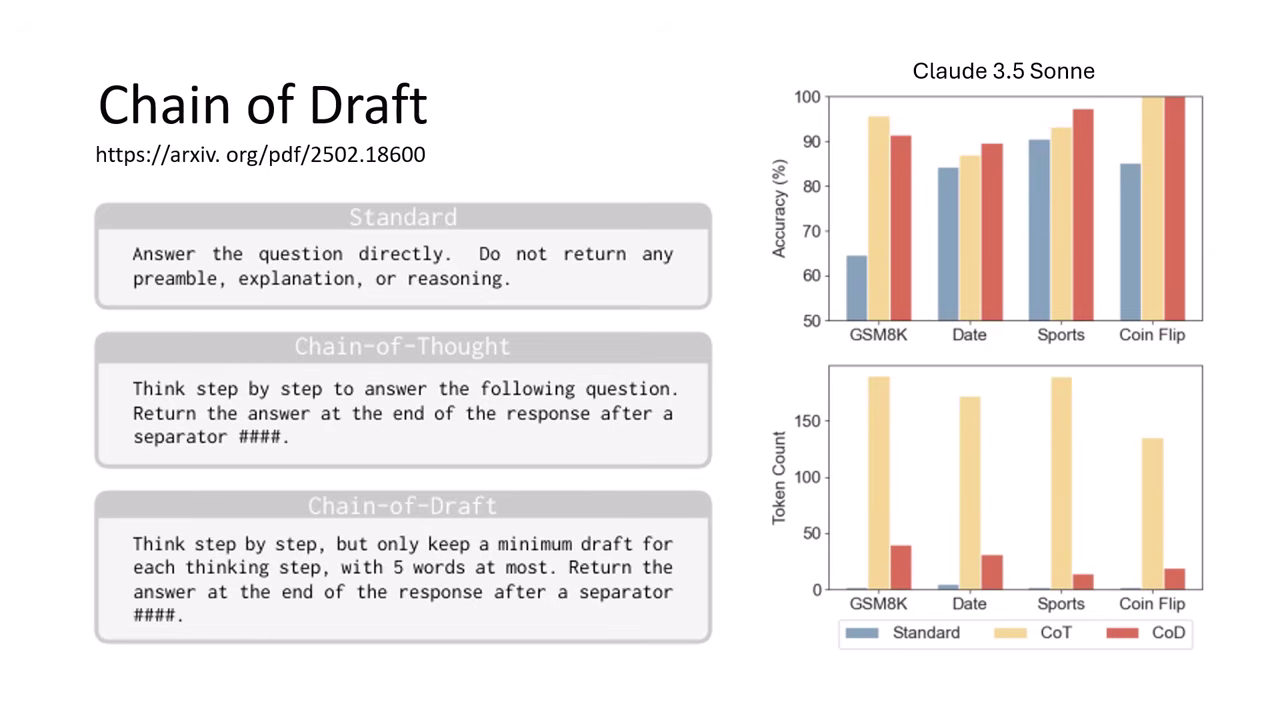
方法一:Chain of Draft (CoD)
此方法透過 Prompt 改寫,限制模型輸出的形式,屬於 Prompt Engineering 的一種。
- 操作方式:
- 不只是叫模型
Think step by step。 - 而是要求模型:每一各思考步驟都只是一個「草稿 (Draft)」,且每一條草稿不能超過 5 個字。
- 不只是叫模型
- 成效:
- 實驗顯示(如 Claude 3.5 Sonnet),CoD 能讓輸出長度大幅縮短,但正確率與標準 CoT 相當,甚至在某些任務上表現更好。
方法二:給模型推論工作流程 (Inference Workflow)
此方法不需訓練模型,而是透過人為設定參數來控制。
- 控制手段:
- 調整 Sampling 的數量(少一點)。
- 縮小 Beam Search 的 Beam Size。
- 限制樹狀搜尋(Tree Search)的規模(樹長小棵一點)。
- 目的:透過外部限制,直接物理性地減少模型生成過長推理的可能性。
方法三:教模型推理過程 (Imitation Learning)
此方法透過挑選訓練資料,教導模型「精簡」思考。
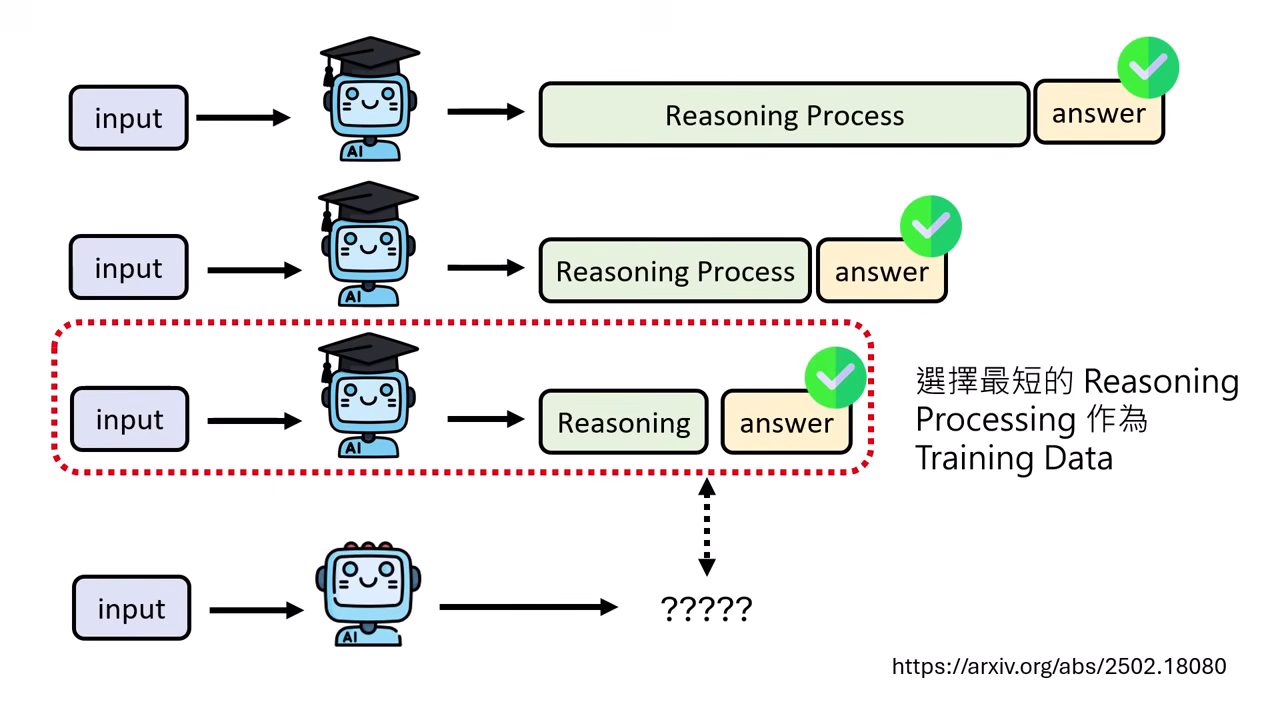
最短推理過程當作學習
- 當「老師模型」針對同一題產生多種推理路徑且都答對時,只挑選「最短」的那一條推理過程當作訓練資料給「學生模型」學。
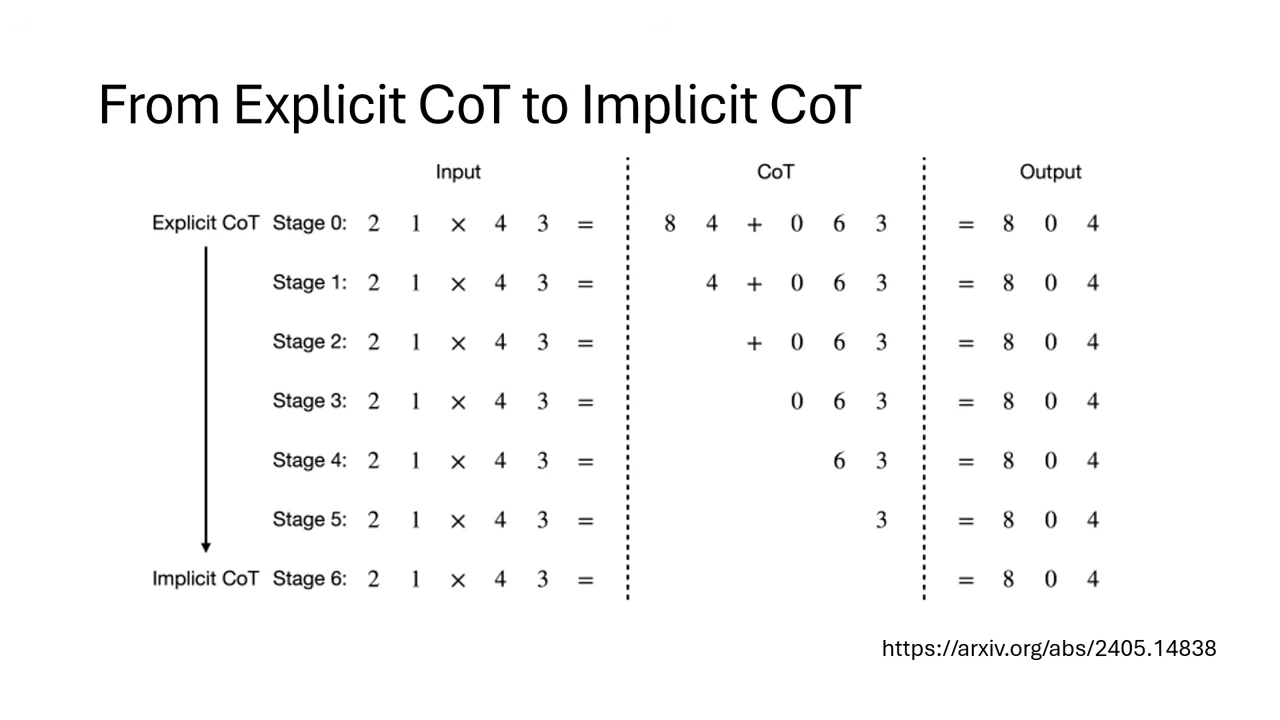
Explicit to Implicit CoT (將顯性推理轉為隱性)
- 概念:訓練模型將推理過程「內化」(心算),而不需要寫出來。
- 漸進式移除法:
- 先讓模型學完整的 Reasoning 過程。
- 訓練模型在移除第 1 個推理 Token 後仍能產生答案。
- 依此類推,逐漸移除更多 Token。
- 結果:在簡單任務(如乘法、GSM8K)上,可以訓練出一個完全不輸出推理過程,但正確率與會推理的模型相當的模型。
方法四:以結果為導向學習推理 (Reinforcement Learning, RL)
此方法透過設計 Reward Function,讓模型學會自我控制長度。
RL 導致長度暴增的原因
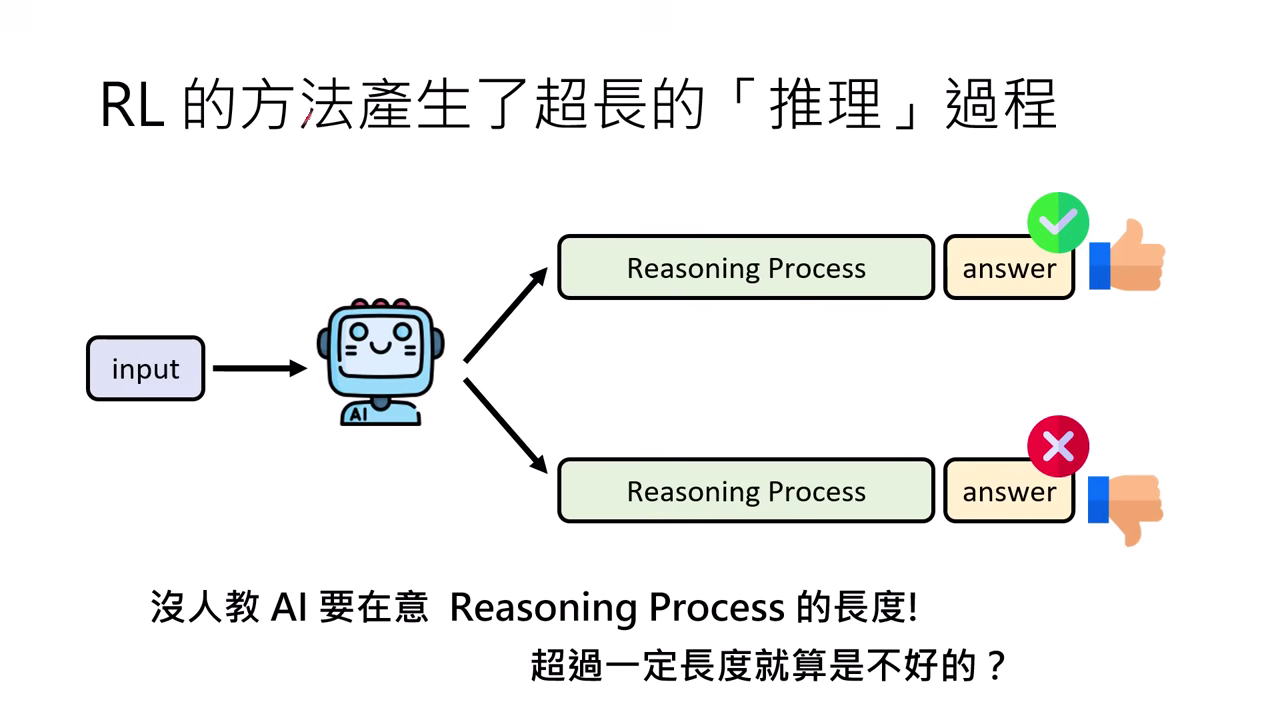
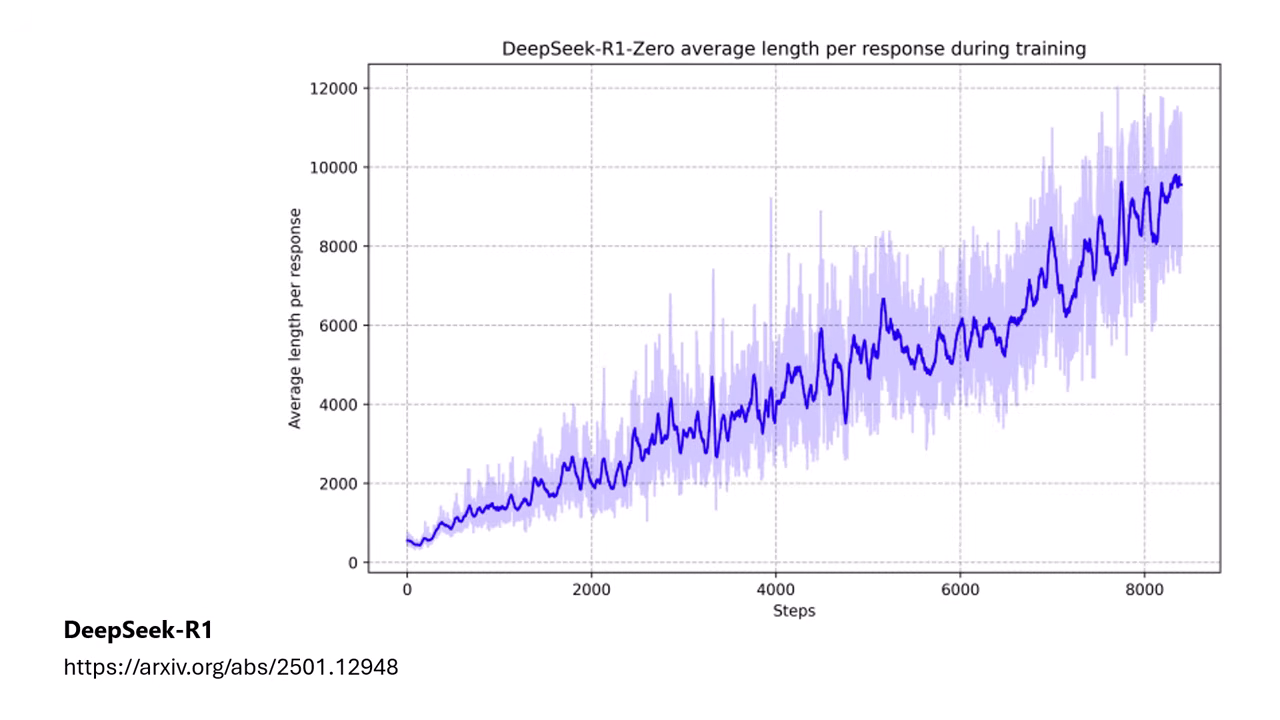
- 在傳統 RL(如 DeepSeek-R1-Zero)訓練中,Reward 只看「答案對不對」。模型發現只要想得夠久、反覆驗證就能答對,因此在沒人管長度的情況下,推理過程會無止盡地變長。
 |  |
|---|---|
| 沒有人教 AI 要在意 Reasoning Process 的長度 | DeepSeek-R1-Zero 推理過程會無止盡地變長 |
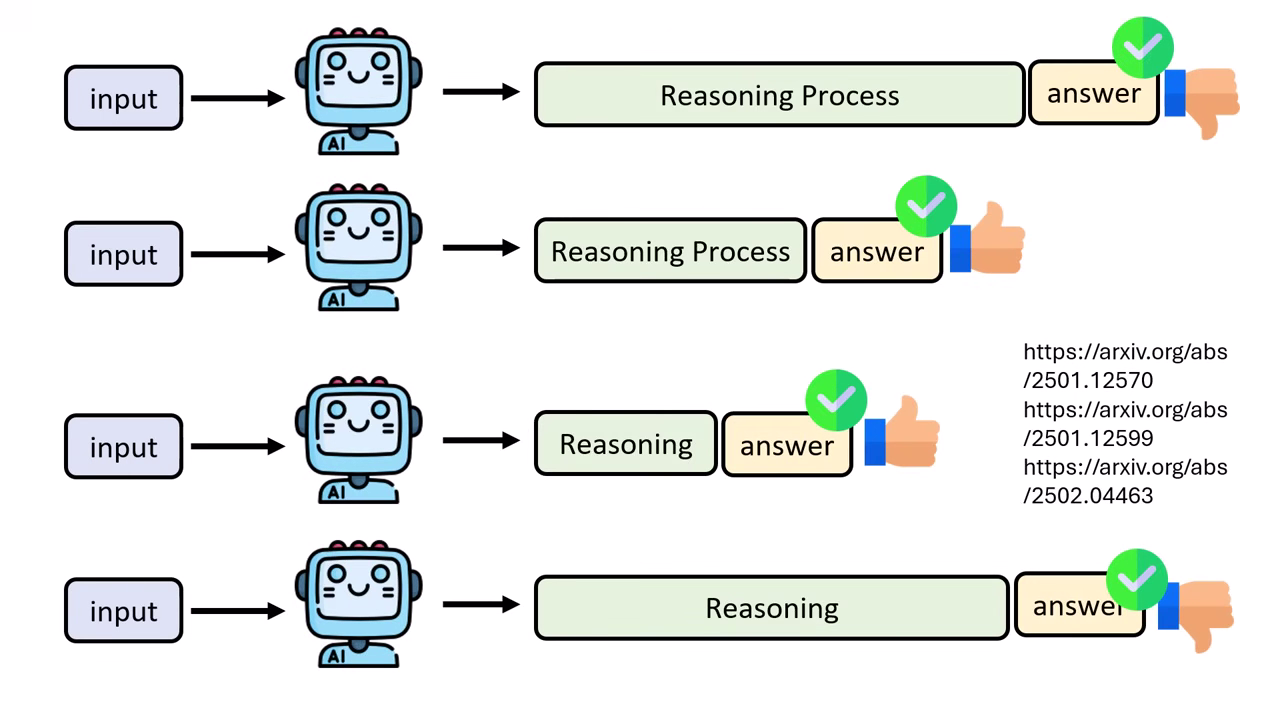
解決方法 1:相對標準 (Relative Standard)
- 不能設定絕對長度(如:超過 1000 字就扣分),因為題目有難易之分。
- 做法:計算該問題在答對狀況下的「平均推理長度」。
- Reward 機制:只有當「答對」且「長度比平均短」時,才給予正面獎勵;若比平均長則視為不好。
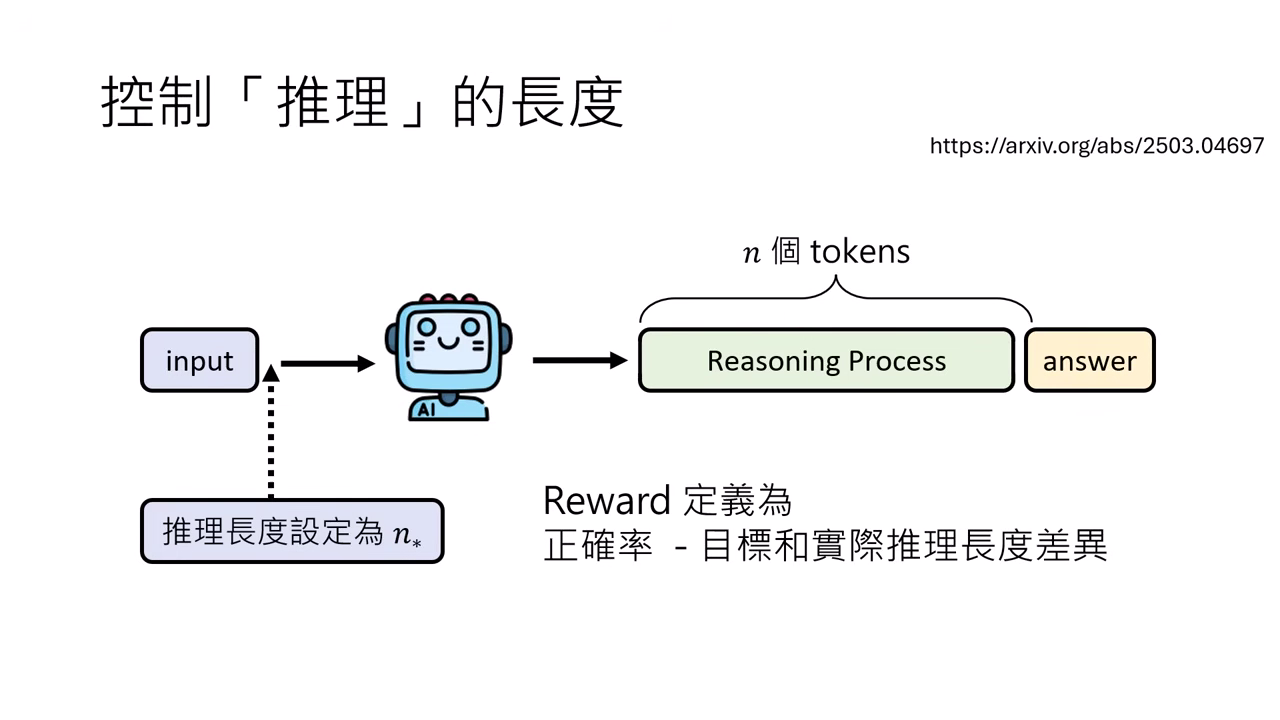
解決方法 2:教模型控制長度 (Controllable Length)
- 做法:在 Prompt 中直接指定目標長度(例如: 字)。
- Reward 設定:
正確率 - |��目標長度 - 實際長度|。若與指定長度差距過大,Reward 就會降低。 - 成效:
- 模型能學會根據指令輸出特定長度的推理,誤差約在 2%~6% (In-domain)。
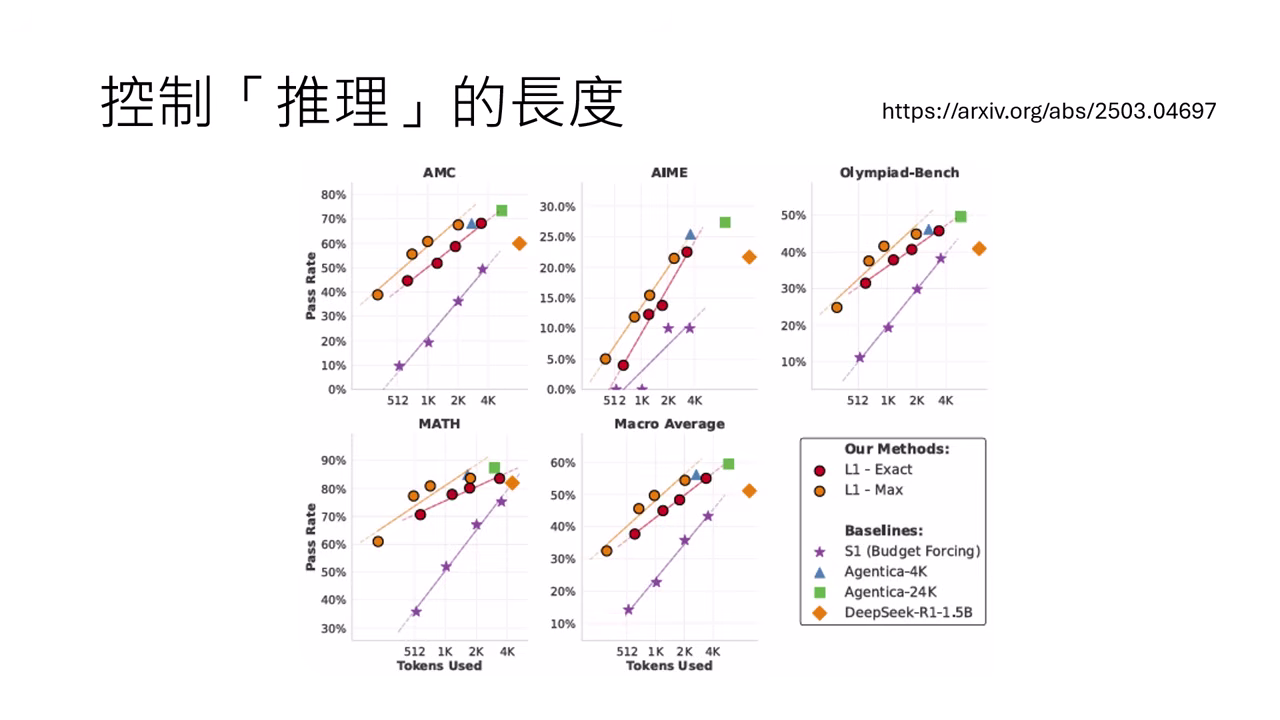
- L1 vs. S1:透過 RL 學會控制長度的模型 (L1),其表現遠優於被「強制截斷 (Cut off)」的模型 (S1)。且當允許長度越長時,L1 的能力會逼近無限制的模型。
 |  |
|---|---|
| 與指定長度差異過大,Reward 就會降低 | L1 透過 RL 學會控制長度,比 S1 直接截斷效果好很多 |