A Novel Table Tennis Stroke Recognition Method Using The Bimodal Deep Neural Networks with Skeletal-Temporal Transformer and Racket Geometric Features
結合骨架時序轉換器與球拍幾何特徵之雙模態深度神經網路於桌球擊球動作辨識之研究
👉 Download NCHU_CS_Master_Thesis_2025_ChaoEnHuang.pdf
桌球擊球資料集實驗結果
為直觀呈現模型結果,我們將預測結果、骨架姿態與球拍幾何資訊疊加於影片中,清楚展示模型可穩定辨識八類擊球動作,並正確掌握其時序與語意變化。 此結果驗證所提出之骨架時序建模與球拍幾何特徵設計,可有效提升辨識精度與穩定性,展現於智慧運動分析應用中的實用潛力。
JHMDB 實驗結果
比較 HIT Network 與本方法在動作的預測序列顯示,HIT 容易誤判關節構型相似的動作,缺乏時間脈絡理解;相對地,本方法能連續正確預測整段動作階段,展現出更高的一致性與語意辨識力。 於 JHMDB 資料集上亦達到 83.8% F1-score,證明具備良好泛化能力與語意穩定性。
摘要
本研究提出一套結合2D 骨架模態與RGB 視覺模態之雙模態深度神經網路架構,應用於桌球擊球動作辨識任務。
骨架模態採用 SkateFormer 模型建構時間序列特徵,描述姿態變化與語意脈絡;影像模態則使用 SlowFast ResNet 結構擷取紋理細節與場景資訊。
模型額外整合球拍之區域面積與中心座標等幾何特徵,輔助標示揮拍過程的起訖區間。
訓練資料集由專家示範建構,涵蓋正手與反手共八類典型擊球動作,並以滑動視窗方式建立具時間連續性的標註片段。
實驗結果顯示,本方法在桌球資料集上達到 96.1% 的 Precision、96.4% 的 Recall 與 96.2% 的 F1-score,
相較 HIT Network 相對提升 25.9%,整體效能亦優於 SkateFormer 與 SlowFast ResNet 等基準模型;
在 JHMDB 通用動作資料集上亦取得 84.2% 的 Precision、83.8% 的 Recall 與 83.8% 的 F1-score,
相較 HIT Network 相對提升 1.7%,展現穩定的分類效能與良好的泛化能力。
本研究驗證骨架與影像模態之互補性,以及幾何特徵對動作邊界判斷之輔助價值,展現其於智慧體育分析場景中的應用潛力。
關鍵字:雙模態深度神經網路、桌球動作辨識、骨架時序轉換器、球拍幾何特徵、實例分��割
 |  |
|---|---|
| 本方法之流程圖 | 雙模態動作識別架構圖 |
緒論
研究背景與動機
隨著智慧科技快速發展,運動分析逐漸導入人工智慧技術,以提升訓練與比賽的效率與精準度。 以桌球為例,傳統訓練方式倚賴人工標記與影片回放,不僅耗時,也難以客觀量化動作細節,尤其在面對大量影片分析時,效率與準確性更顯不足。
近年來,人體姿態估測(Human Pose Estimation)技術 [1] 被廣泛應用於運動動作辨識任務中。 透過卷積神經網路預測人體關節位置,建立骨架輸入進行分類,不但具備抗背景干擾能力,也能清楚描述運動結構。
然而,僅依賴單幀骨架模態仍面臨以下挑戰:
- 桌球動作類型外觀相似,僅從單幀骨架難以準確分類。
- 遮蔽與快速動作常導致關鍵點缺失,降低辨識穩定性。
- 骨架無法完整��呈現球拍等具關鍵語意的資訊。
 |
|---|
| 外觀相似的單幀骨架姿態對應不同擊球類型 (左:正手切球;右:正手平擊) |
多模態融合的必要性
為克服上述限制,研究開始導入多模態設計:
- RGB 影像模態:提供豐富外觀與場景資訊,有助於補足骨架遮蔽問題。
- 骨架模態:去除背景、強調結構,但缺乏時間與物件語意,且易因遮蔽導致關節點缺失。
- 球拍幾何特徵:擊球揮拍方向與角度能反映策略與球路變化,因此面積和中心位置能提供關鍵的時序定位資訊。
 |
|---|
| 骨架點因遮擋產生缺失現象 (左:原始 RGB 影像;右:人體姿態估測結果) |
研究目標
本研究提出一套雙模態融合桌球動作辨識系統,核心設計如下:
- 結合骨架的空間與時間資訊,提升時序建模能力。
- 輔以 RGB 影像模態,補強骨架在遮蔽與細節辨識上的限制。
- 納入球拍區域幾何特徵,協助精確掌握動作起始與終止時間點。
透過骨架與影像的語意互補,結合球拍資訊的時間定位能力,本系統具備高度辨識準確性與實務應用潛力。
文獻回顧
雖然桌球為受關注的競技運動,針對其擊球動作辨識的研究仍相對有限。為系統性整理相關工作,本章將文獻分為以下兩類:
- 專用方法:針對桌球擊球辨識所設計的模型
- 通用方法:應用於人體動作辨識並延伸至桌球任務的架構
專用方法:桌球擊球辨識(基於 2D 姿態估計的方法)
2D Pose Estimation 技術廣泛用於動作分析,透過模型預測人體關節點位置(如頭部、手肘、膝蓋),並可用於時間序列動作識別。 Kulkarni 和 Shenoy 提出一套結合 HRNet 骨架估測 [4] 與 Temporal Convolutional Network (TCN) [2] 的擊球分類模型,流程如下:
優點:
- 成功分類 11 種擊球動作,平均辨識率達 98.72%
- 展現了 2D 骨架資訊在桌球擊球動作辨識上的可行性與成效
限制:
- 僅使用少數關節,無法建立完整骨架語意
- TCN 缺乏關鍵關節與時間範圍的選擇彈性
- 未建構空間與時間的結構關聯,語意易流失
- 前視角攝影可能干擾比賽,影響實務應用
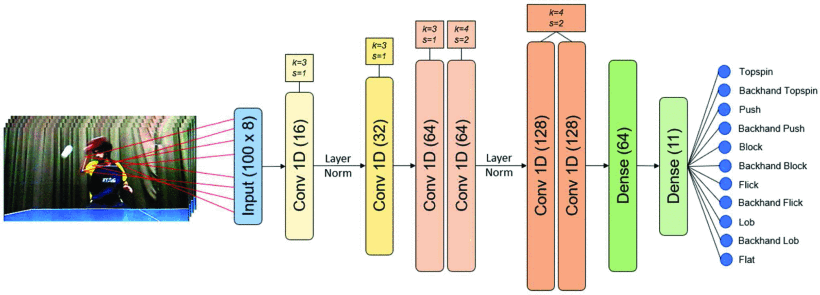 |
|---|
| TCN 之模型架構圖 [2] |
專用方法:桌球擊球辨識(基於雙分支時空卷積的方法)
Martin 等人 提出 Twin Spatio-Temporal Convolutional Neural Network (TSTCNN) [5] ,由兩條 3D 卷積分支組成:
- 分別處理 RGB 原始畫面與 Optical Flow 特徵 [6]
- 利用 3D 卷積建構空間-時間特徵
- 最後融合兩模態資訊進行分類
優點:
- 雙分支設計同時捕捉 空間構型(RGB) 與 運動動態(Optical Flow)
限制:
- 光流在高速度與運動模糊場景中準確度下降
- 未引入骨架語意,對細粒度肢體姿勢辨識不足
- 僅以雙線性插值進行靜態融合,缺乏注意力機制的語意選擇性與適應性
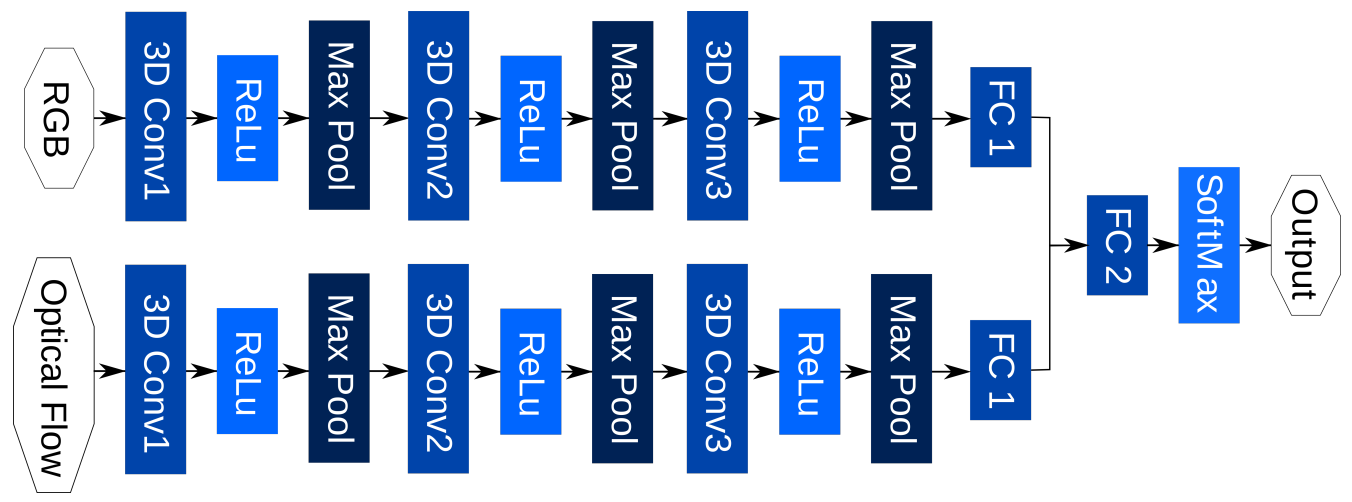 |  |
|---|---|
| TSTCNN 之模型架��構圖 [5] | 光流影像產生流程示意圖 [5] 左上:原始 RGB 影像;右上:光流幅度影像 左下:估計出的前景影像;右下:過濾後的光流影像 |
通用方法:人類動作辨識(基於骨架時序建模的方法)
骨架模態具備抗背景干擾與光照變化的優勢,已成為動作辨識的重要依據。Do 與 Kim 提出的 SkateFormer [7] 是此方向的代表性模型,其設計特色如下:
- 採用 Transformer 架構 [8] ,將 3D 骨架序列依空間與時間語意結構劃分為四個分支進行建模
- 引入 Partition-Reversal 機制切分還原特徵,維持骨架時序結構一致性
- 擅長建構遠距關節與長時間依賴,提升動作時序辨識能力
限制:
- 高動態動作(如揮拍、轉身)易導致關節遮蔽、缺失或錯置
- 骨架品質低落將直接傳遞至注意力機制,影響語意聚焦
- 完全依賴骨架模態,缺乏 RGB 或光流等多模態補強線索
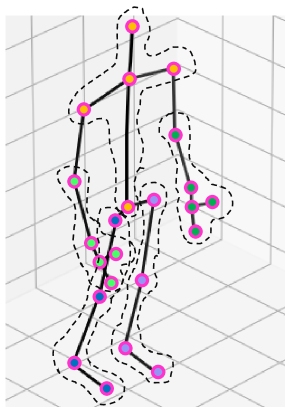 |
|---|
| 理想情況下的完整關節量測 [7] |
通用方法:人類動作辨識(基於互動注意力建模的方法)
Faure 等人 提出的 HIT Network [9] 採用雙分支設計,整合 RGB 與骨架模態:
- RGB 分支 擅長捕捉動態紋理與物件互動
- 骨架分支 建立關節之間的空間語意關聯
- 最終透過 Attentive Feature Fusion Module 進行深度融合,用於分類與動作區段預測
優點:
- 結合 視覺(RGB) 與 骨架(Pose) 表徵,透過 注意力融合機制 實現穩健的雙模態整合
- 同時利用 外觀紋理 與 姿態結構 資訊,強化對 動作語意 的理解與分類能力
限制:
- 僅針對單幀骨架進行 Pose Encoding,缺乏時間建模能力
- 難以辨識動作中的微小變化與演化順序,易造成語意混淆
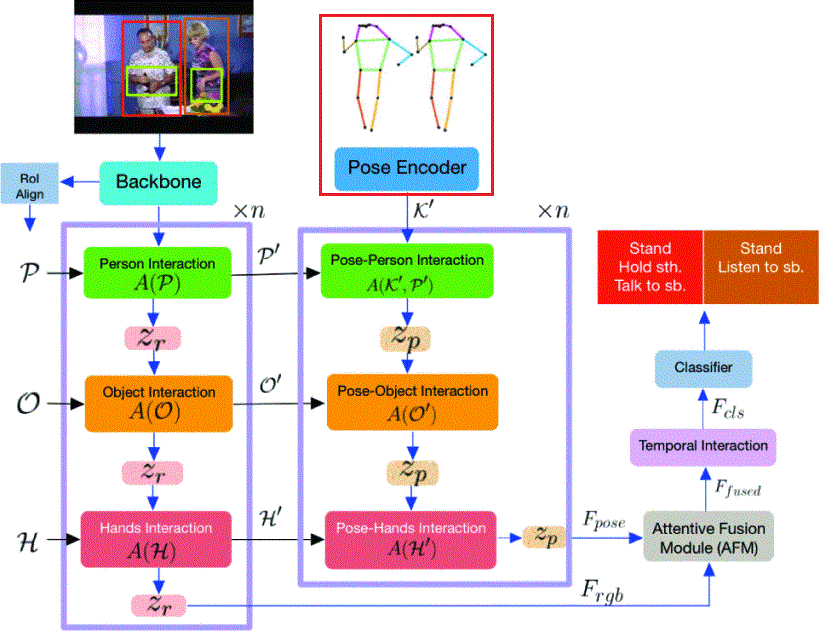 |
|---|
| 單幀骨架編碼示意圖 [9] |
研究方法
本研究系統如圖所示,整體流程可分為四個模組:
-
Object Segmentation(物件分割):
利用 YOLOv11 架構 [14] 對輸入影片中的球拍區域進行分割,並擷取其面積與中心座標作為幾何特徵。
-
Pose Estimation(姿態估測):
採用 YOLOv11 架構 [14] 之姿態估測模型,擷取每一幀選手的2D 關節點資訊,建立骨架序列。
-
Action Recognition(動作辨識):
將骨架序列輸入 SkateFormer,RGB 序列輸入 SlowFast ResNet,並透過雙模態架構進行時序辨識。
-
Predicted Results(結果輸出):
將辨識結果與關鍵資訊疊加回原始影片,進行可視化輸出。
|
|---|
| 本方法之流程圖 |
物件分割模型
本研究採用基於 YOLOv11 架構 [14] 的物件分割模型,針對影片中球拍區域進行精確分割與幾何資訊提取,支援後續動作辨識任務。
深度學習於影像分割中的應用背景
- CNN 在視覺任務中的角色 [10]:透過多層卷積與池化操作,CNN 能逐層抽取影像特徵並進行分類、分割與關鍵點推論。
- Segmentation vs. Detection:傳統偵測使用 Bounding Box,無法提供像素層級資訊;而實例分割可提供物件精確輪廓。
- FCN 語意分割的突破 [11]:Fully Convolutional Networks (FCN) 將傳統 CNN 架構改造成全卷積形式,能對影像中每個像素進行類別預測,實現語意分割。然而,其限制在於無法區分同類別的不同實體,僅能提供類別層級的輪廓資訊。
- 代表方法:為克服 FCN 的不足,後續如 Mask R-CNN [12] 與 YOLACT [13] 等方法結合物件偵測與像素分割機制,進一步實現可區分不同實體的即時實例分割能力 (Instance Segmentation),提升語意與空間的解析度。
球拍分割的挑戰性
- 快速移動與運動模糊
- 形狀細長且容易與背景混淆
- ��尺寸與視角變化劇烈
二維人體姿態估計模型
本研究採用基於 YOLOv11 架構 [14] 的單階段姿態估計模型,針對影片中運動員的骨架資訊進行精準定位與建構,提供後續時序動作辨識關鍵的人體幾何特徵。
人體姿態估計的研究背景與應用價值
- 2D Human Pose Estimation 目標:預測人體 17 個關節點(如肩、肘、髖、膝),建立具空間幾何關係之骨架結構。
- 視覺辨識中的角色:有助於區分動作中細微差異,如肢體揮動的節奏與關節角度變化。
- 實務應用需求:桌球運動中動作細緻且快速,傳統 RGB 方法難以穩定捕捉所有姿態變化。
YOLOv11 架構於姿態估計中的優勢
- 單階段設計(Single-stage):於一次前向傳遞中同時完成人物偵測與骨架關鍵點回歸。
- 多層特徵融合:結合不同解析度之訊息,提升模型在局部與整體骨架結構間的辨識能力。
- 使用預訓練權重:採用 YOLOv11-pose 官方模型,強化模型泛化能力並加速訓練流程。
 |
|---|
| 物件分割暨人體姿態估計網路架構圖 |
YOLOv11
YOLOv11 是一種單階段(single-stage)物件偵測與姿態估計架構 [14] ,延續了 YOLO 系列一貫的高速推論特性,同時在精度與結構設計上進行多項升級。相較於傳統兩階段模型,YOLOv11 能在單一前向傳遞中同時完成物件定位與關鍵點回歸任務,特別適用於即時需求場景,如桌球動作辨識。
為提升模型在複雜背景、物體遮擋與快速移動條件下的辨識表現,YOLOv11 進一步整合多個先進模組,包括 SPPF、PANet、C3K2、C2PSA,共同強化特徵提取、語意聚合與空間注意力表徵能力。以下分述各模組設計與其於本研究中的角色。
SPPF 模組(Spatial Pyramid Pooling - Fast) [15]
模組背景與設計理念
- 傳統 CNN 難以同時兼顧局部細節與全域上下文,尤其在物件尺寸變化大時易影響辨識效果。
- SPP(Spatial Pyramid Pooling)[17] 透過多尺度池化捕捉不同感受野特徵,但原始設計計算成本較高。
SPPF 改進重點
- 快速版設計(Fast):將多尺度 MaxPool 操作串接重複使用,降低計算複雜度。
- 架構特性:使用三層串接式 5×5 MaxPooling 操作,有效聚合多尺度語意。
在本研究中的角色
- 應用於骨架與影像特徵提取的末端,協助模型取得更廣泛的上下文資訊,提升對不同尺度骨架變化與物體區域的辨識穩定性。
 |
|---|
| SPP 與 SPPF 模組架構比較 |
PANet 模組(Path Aggregation Network) [16]
模組背景與應用需求
- 高階特徵具語意但缺細節,低階特徵具細節但缺語意,特徵融合成為重要課題。
- PANet 延伸自 FPN(Feature Pyramid Network)[18] ,強化下行傳遞路徑,以提升定位精度。
PANet 核心特性
- Bottom-up 強化路徑:由高層往低層回傳資訊,使模型得以整合更多空間訊息。
- Adaptive Feature Fusion:透過路徑加總與融合,提升多層次資訊流的利用效率。
在本研究中的角色
- 整合不同層級的特徵圖,有助於提升分割準確度與骨架預測的空間一致性,特別適用於複雜背景與動作模糊下的解析。
 |
|---|
| 路徑聚合網路架構圖 |
C3K2 模組(Cross Stage Partial with two 3×3 convolution layers)[14]
模組背景與設計動機
- 傳統 Bottleneck 的限制:常以 1×1 卷積進行通道壓縮與特徵轉換,雖能降低運算量,但 對邊緣與紋理細節的感知較弱,在需要高精度局部特徵時表現不足。
- C2F 與 CSPNet 的傳承:YOLOv11 延續自 CSPNet [20] 的設計理念,透過 跨層部分連接 (Cross Stage Partial) 與 特徵分支融合,避免重複計算並促進梯度流,兼顧效率與表徵能力。
- C3 → C3K2 的改良:在 YOLOv8 的 C2F [19] 基礎上,YOLOv11 導入 C3K 與 C3K2。其中 C3K2 固定使用雙層 3×3 卷積 Bottleneck,取代傳統 1×1 設計,以加強 非線性建模能力 與 邊界細節捕捉。
結構設計特色
- 雙層 3×3 卷積堆疊:強化對 局部紋理與邊界 的辨識精度。
- 固定 Bottleneck 數量:減少架構變異,提升 深層資訊傳遞穩定性。
- 跨層融合優勢:兼顧 低階空間資訊保留 與 高階語意特徵提取。
在本研究中的角色
- 提供更穩定的空間結構建模基礎,能準確捕捉如手肘、膝蓋等高變異性關節點,進而提升姿態估計精度與動作細節感知能力。
 |
|---|
| C2F、C3K2 與 C3K 模組結構比較示意圖 |
C2PSA 模組(Cross Stage Partial with Parallel Spatial Attention)[14]
模組背景與任務挑戰
- 姿態估計與動作辨識需聚焦於肢體區域,傳統 CNN 難以主動選擇關鍵區塊。
- Attention 機制可引導模型資源集中於高資訊密度區,但需設計兼顧��效率與效果的架構。
模組架構與特性
- 雙 PSA 路徑:將輸入通道拆分為兩支路徑,獨立套用空間注意力(PSA)模組。
- 殘差串接融合:保留原始特徵脈絡,並強化注意力加權後的區域資訊。
- 多層卷積強化選擇性聚焦:特別對低對比與遮蔽的關節區域效果顯著。
在本研究中的角色
- 強化模型對於手腕、腳踝等細節部位的辨識能力,提升骨架預測在遮擋與動作模糊下的穩定性與準確性。
 |
|---|
| 平行空間注意力模組(C2PSA) 與 PSA 子模組結構示意圖 |
骨架時序導向動作識別模型
SkateFormer 模型專為動作辨識中的骨架模態設計,具備時序建模與空間結構感知能力,能有效提升動作語意理解與辨識準確性。其整體流程如下:
-
輸入骨架序列
每筆輸入為 ,其中 為時間長度、 為每幀的關節點數、 為每點的座標維度。
-
特徵轉換與嵌入
經三層線性投影轉換至高維特徵空間,並加入 Skate-Embedding(時間+骨架位置編碼)以強化模型對動作進程的理解。
-
SkateFormer Blocks
主體架構由 4 個時序層級組成(、、、),每層重複堆疊兩次,支援跨時間尺度建模。
-
注意力與卷積機制
- Skate-MSA(骨架-時間多頭自注意力)
- G-Conv(骨架卷積)
- T-Conv(時間卷積)
- FFN 與殘差連接 採通道分割策略並行建模空間與時間依賴關係。
-
語意向量輸出
特徵經 Pooling 後壓縮至固定維度語意向量,作為後續交互模組與最終分類的輸入。
 |
|---|
| SkateFormer 架構圖 |
骨架與時間關係建模
在骨架為基礎的動作辨識中,關節點於時間軸上的連續排列提供了動作語意的關鍵資訊。 傳統圖卷積網路(GCNs)雖能建模關節鄰接關係,但受限於僅傳遞局部訊息,難以捕捉如手腕與肩膀等遠距但語意密切的互動。 同時,一維時間卷積只能處理固定視窗內的區域變化,難以涵蓋整體動作流程,如擊球的起始、施力與收尾等階段。
為克服上述限制,SkateFormer 採用基於 Transformer 的自注意力架構,並引入分區式骨架建模策略。 具體而言,將骨架劃分為 個不重疊的子集合 ,涵蓋右手臂、左手臂、右腿、左腿、肩膀、腰部、右眼耳與左眼耳。 每個子集合內的關節依從身體中心向外的順序排列,以模擬真實動作中的能量傳遞。
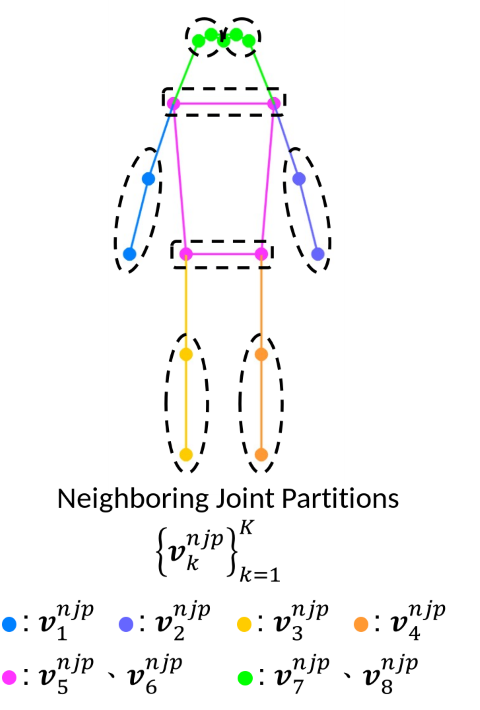 |
|---|
| 人體骨架分區示意圖 |
此外,SkateFormer 將關係建模劃分為兩大面向:
- 空間關係(Skeletal Relation Types):區分「鄰近關節」與「遠距關節」,分別捕捉區域內細節與整體協調性。
- 時間關係(Temporal Relation Types):區分「局部時間」與「全域時間」,前者對應細微動作變化,後者涵蓋動作節奏與結構。
 |
|---|
| 骨架與時間關係的類型示意圖 |
透過上述設計,SkateFormer 能自動加權辨識 關鍵幀與關鍵關節,強化語意特徵學習,並有效平衡辨識效能與計算效率,克服 GCN 與傳統 Transformer 在遠距建模與效率上的瓶頸。
骨架時序轉換器
SkateFormer Block 是本架構的核心,承襲 Transformer 設計,包含自注意力層(Self-Attention Layer)與前饋神經網路(Feed-Forward Network, FFN)。 如圖所示,為同時捕捉骨架的空間結構與時間動作變化,輸入特徵先經 LayerNorm 與線性變換,並於通道維度拆為三路,對應骨架圖卷積(G-Conv)、時間卷積(T-Conv)與骨架多頭自注意力模組(Skate-MSA),分別為:
G-Conv 模組引入可學習的關節關聯矩陣(形狀為 ),動態建構潛在連接,強化空間關節建模能力;T-Conv 採一維卷積(kernel size = )針對 通道特徵進行時間建模;Skate-MSA 則具備空間-時間分區注意力,能根據關節距離與時間跨度設計加權策略。
三者輸出經串接後通過線性層融合,並與輸入進行殘差連接完成自注意力階段,運算流程如下:
接著進入 FFN 階段,由兩層線性層與中間 GELU 激勵函數組成,並搭配殘差與 LayerNorm:
為擴展時間感受野、減少計算負擔,模型部分區塊開頭加入 stride=2 的一維卷積與 BatchNorm 組成的下採樣模組,壓縮時間長度並保留語意資訊。 整體設計融合 G-Conv、T-Conv 與 Skate-MSA,實現空間-時間-語意的三軸建模,有效捕捉跨關節互動、動作演化趨勢與判別語意,提升辨識效能。
 |
|---|
| Skate-MSA:四分支特徵依據空間與時間關係分割與還原後整合 |
骨架與時序的分區與反轉
Skate-MSA 為強化空間與時序的特徵建模,設計結合空間鄰近性與時間連續性的分區與重組策略,提升模型對結構互動與語意邏輯的表現能力:
-
輸入特徵表示為骨架序列:每一幀包含 個關節,每個關節提供 2D 座標資訊,總體輸入表示為:
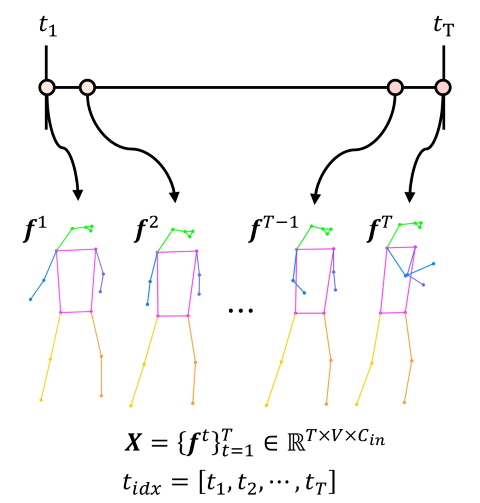
骨架序列輸入示意圖 -
空間分區(Spatial Partitioning)
- 鄰近關節分區(Neighboring Joint Partitions):將 個關節依人體解剖結構分為 個不重疊分區,每分區含 個關節:
- 骨架軸表示:
- 遠距關節分區(Distant Joint Partitions):對每個位置 ,從各鄰近分區擷取對應關節:
-
時間分區(Temporal Partitioning)
- 局部時間軸:將完整時間序列分割為 個子段:
- 全域時間軸:每隔 幀取樣形成跨時序片段:
- 完整時間軸重建關係式:
-
四種張量重排策略(Joint-Time Pairing):輸入張量 經結合後重排為:
- :鄰近關節 × 局部時間:
- :遠距關節 × 局部時間:
- :鄰近關節 × 全域時間:
- :遠距關節 × 全域時間:
-
模組整合
- 每組重排張量皆輸入對應的多頭自注意力模組建模後,再透過逆操作 還原至原始形狀 ,利於通道維度拼接與融合。
 |
|---|
| 骨架與時間特徵之結構重排與還原操作示意圖 |
多頭自注意力模組
為統一處理四種骨架-時間分區產生的特徵張量,Skate-MSA 首先將每一特徵張量 調整為形狀 ,其中 為 batch size, 分別為分區後的時間與空間維度。 接著展平成 ,並透過三個線性權重 映射為查詢(Q)、鍵(K)、值(V):
自注意力機制中,每個 head 的輸入會 reshape 為 ,進行如下計算:
其中, 是位置偏差矩陣,考慮時間(相對位置 )與空間結構(骨架位置 )的語意對應,組合方式如下:
最後將所有 個 head 的輸出串接,形成最終表示:
計算複雜度分析
傳統自注意力輸入為 ,其複雜度為:
- 內積計算(注意力權重):
- 總體複雜度為:
Skate-MSA 透過空間與時間的分區,顯著降低計算成本。以四種分區為例:
四者總和為:
因此,相較於傳統自注意力的計算複雜度,Skate-MSA 的總體複雜度約為其的:
骨架-時間位置嵌入
為建構時間與關節位置的結構化表示,SkateFormer 採用骨架-時間位置嵌入(Skate-Embedding)策略,整合:
- 固定時間索引特徵(Temporal Embedding, TE):將正規化後的時間索引 輸入 Sinusoidal Encoding,產生 。
- 可學習關節特徵(Skeletal Embedding, SE):為每個關節編號設計對應嵌入向量 ,不依賴實際座標。
最後,兩者透過通道維度進行逐元素相乘,形成最終的骨架-時間嵌入:
此嵌入可幫助模型在每個時間點與關節節點中注入對應語意與時空資訊。
 |
|---|
| Skate-Embedding 結構示意圖 |
雙模態導向動作識別模型
細粒度動作辨識如桌球擊球,常伴隨細微的肢體差異與物件操作行為。 傳統單模態模型(僅使用 RGB �或骨架)難以全面捕捉人物動作與目標物之間的時空語意關係。 Faure 等人提出的 Holistic Interaction Transformer Network(HIT Network)為典型雙模態架構,融合單幀 RGB 與 2D 姿態特徵,並透過人物與物件的語意交互建模來提升辨識能力。 然而,HIT 所採用的骨架模態僅為靜態姿態,缺乏時間序列建模能力,導致對連續性動作與階段過渡的掌握有限。
本研究延續 HIT Network 的設計精神,提出具時序感知與幾何感知能力的強化架構,融合以下兩項關鍵模組:
-
時間感知骨架特徵:
採用前面所述的 SkateFormer 模型,處理多幀骨架序列以捕捉關節運動的時空依賴關係,提升對連續動作的語意建模能力。
-
幾何感知球拍特徵:
整合 YOLOv11 所推導之球拍分割結果,包含其幾何中心與面積,作為與手部與人物之間空間互動的重要輔助訊號。
如下圖所示,整體架構中,模型自輸入影像中擷取四個區域:人物(P)、手部(H)、球拍(O)與球拍幾何特徵(R),透過 RoI Align 投影至統一空間後進行區域互動建模。
各模態特徵透過多層次互動模組(Person / Object / Hands / Racket Interaction)建構語意表示,並經由特徵選擇模組(, )篩選重要區域特徵。
與此同時,SkateFormer 將骨架序列嵌入為語意性姿態表徵,並分別與 RGB 模態中各區域進行一對一跨模態互動(Pose-Person、Pose-Object、Pose-Hands、Pose-Racket),加強動作語境中多源特徵的對齊與關聯。
最後,骨架模態與 RGB 模態特徵分別記為 與 ,經注意力融合模組(Attentive Fusion Module, AFM)整合��為融合特徵 ,並送入時間交互模組(Temporal Interaction, TI)以強化跨幀語意一致性,最終產生分類向量 ,用於預測動作類別。
|
|---|
| 雙模態動作識別架構圖 |
RGB 影像特徵擷取
為增強模型對動作時序資訊的表徵能力,本研究於 RGB 模態中採用 Feichtenhofer 等人 [21] 提出之 SlowFast 架構作為特徵提取骨幹,其設計理念為同時捕捉影片中長期語意與短期動作變化。 整體架構如下圖所示,由兩條獨立路徑組成:
- Slow Path:處理低影格率(low frame rate)輸入,具備較高通道數與較低時間解析度,用於學習動作的長期特徵與語意脈絡。
- Fast Path:對應高影格率輸入,通道數僅為 Slow Path 的 ,但時間解析度為其 倍,能有效捕捉短期運動細節。
兩路徑皆以 ResNet 為基礎,於 res2、res3、res4 層提取特徵,並透過 lateral connections 將 Fast Path 的細節資訊融合至 Slow Path,以建構具時間尺度融合能力的多層特徵。此設計提升了模型對複雜動作序列中不同時間特性的辨識能力,並兼顧效率與語意保留。
 |
|---|
| SlowFast ResNet 架構示意圖 |
感興趣區域對齊
本研究採用 He 等人於 Mask R-CNN 中提出的 RoI Align 技術 [12] ,以精確擷取特徵圖中各目標區域的表徵資訊。 如下圖所示,RoI Align 相較傳統 RoI Pooling,移除量化操作、採用浮點對齊,有效解決空間資訊失真問題,提升精細任務(如姿態估計)中的特徵品質。
該方法利用雙線性插值計算 RoI bin 中浮點座標的像素值,插值公式如下所示:
其中, 為鄰近的整數像素值,、 表示浮點座標與左上角點的相對位置。
此外,我們為每影格設計動態 RoI(Dynamic RoI),涵蓋人物(Person)、手部(Hands)、球拍(Racket)等目標區域,並各自抽取對應特徵。 該機制能確保重要物件資訊被完整保留,並提供一致對齊的特徵表示,供後續模組(如 、、、)進行語意交互與跨模態融合。
 |
|---|
| 感興趣區域對齊示意圖 |
語意交互模組與跨模態融合設計
在動作識別任務中,人物與語意區域(物件、手部、球拍)之間的互動關係提供了關鍵線索。 本研究基於 HIT Network 擴展設計以下四種交互模組:
- 人物交互 A(P)
- 物件交互 A(O)
- 手部交互 A(H)
- 球拍幾何交互 A(R)
這些模組皆採用 交叉注意力(Cross-Attention)機制,以人物區域作為查詢(Query),其餘語意區域為鍵(Key)與值(Value),進行語意特徵對齊與融合。
RGB 模態語意融合流程
RGB 模態特徵透過以下順序進行語意交互與更新:
其中,每個語意模組的交叉注意力運算為:
最終,模態內部聚合模組整合語意區域資訊,產生加權表示 :
 |
|---|
| 語意交互模組的運算機制圖 |
 |
|---|
| 模態內部聚合模組運算機制圖 |
姿態模態的跨模態語意交互
骨架序列特徵 分別與來自 RGB 模態的四個語意區域 進行跨模態對齊,整體運算流程為:
其中,每個注意力模組 採用如下計算方式:
注意力特徵融合模組
為提升雙模態動作辨識任務中不同模態資訊的融合品質,本研究採用注意力特徵融合模組(Attentive Feature Fusion Module, AFM),整合來自姿態分支的動作特徵 與 RGB 分支所提取的外觀特徵 ,以獲得更具語意區辨性的表徵。 由於兩模態在特徵空間與語意結構上存在顯著差異,傳統的元素相加或通道串接難以有效對齊其語意,因此 AFM 模組設計具備以下特性:
-
通道串接融合: 將 與 進行串接,使兩者共存於同一空間,保留模態特有訊息。
-
自注意力機制(Self-Attention): 對融合後特徵透過三組 卷積映射為查詢(Query)、鍵(Key)、值(Value),計算語意對應性:
其中 為可學習的投影矩陣, 為通道維度。
-
後處理模組: 包含 Layer Normalization、殘差連接與兩層 卷積,穩定融合語意並提升辨識能力。
-
模態融合特徵輸出 : 作為時序建模模組輸入,有助於捕捉長短期動作變化,強化對微動作與高相似姿態的辨識表現。
 |
|---|
| 注意力特徵融合模組之結構圖 |
時序交互模組
在完成空間語意融合後所獲得的特徵圖 雖已能描繪當前畫面之語意資訊,但人類動作本質具有連續性,語意判斷往往依賴跨時間的上下文關係。 若僅觀察單一幀畫面,容易導致語意斷裂與判斷偏誤。 為此,本研究引入時序交互模組(Temporal Interaction Module, TI),整合來自當前畫面及其前後時間片段的融合特徵,以建構具時間一致性與完整語意脈絡的動作表徵。 該模組設計如下列步驟進行:
-
跨時間特徵建構: 構造時間長度為 的特徵序列 ,包含當前畫面與其前後各 幀之融合特徵 ,本研究設定 ,即使用連續 31 幀資料;
-
交叉注意力融合: 以當前時間步的特徵作為查詢向量(Query),整段時間序列 作為鍵(Key)與值(Value),運用交叉注意力計算語意對應性與時間上下文整合,形成最終時序特徵 :
-
分類器映射: 將 輸入至兩層全連接分類器 ,並於中間引入 ReLU 函數提升模型非線性能力與判別精度:
透過上述時序交互設計,模型能整合多時刻語意資訊,強化動作脈絡的理解,提升對動作變化趨勢、微動作區辨與高相似姿態判別之整體穩定性與準確性。
實驗結果與討論
實驗環境
本研究於高效能運算環境下進行桌球擊球動作辨識模型的訓練與預測。 由於任務涉及大量影像處理與深度神經網路之計算,故採用 GPU 加速運算以縮短訓練時間並提升推論效能。 具體環境與設備配置如下:
-
作業系統與硬體:
- 平台為 Ubuntu 22.04.1
- 處理器:Intel® Core™ i9-9820X @ 3.30GHz
- 記憶體:128GB RAM
- 圖形處理器:NVIDIA TITAN RTX(TU102 架構)
-
開發與深度學習平台:
- 使用 Anaconda 作為開發管理環境
- Python 版本為 3.10.13
- 深度學習框架:PyTorch 2.4.1,並搭配 CUDA 12.1 執行 GPU 加速
-
資料擷取設備:
- 使用 Sony HDR-CX450 數位攝影機擷取影像資料,支援 Full HD(1920×1080)解析度與每秒 60 幀(FPS)錄影,能有效捕捉桌球擊球過程中的細節與動作變化。
| 類別 | 規格與版本 |
|---|---|
| 處理器(CPU) | Intel® Core™ i9-9820X CPU @ 3.30GHz |
| 顯示卡(GPU) | NVIDIA TITAN RTX(TU102 架構) |
| 記憶體(Memory) | 128 GB |
| 作業系統(OS) | Ubuntu 22.04.1 |
| CUDA | 12.1 |
| Python 環境 | Python 3.10.13、PyTorch 2.4.1 |
| 攝影機(Camera) | Sony HDR-CX450(1920×1080@60FPS) |
資料集
本研究使用兩組資料集進行訓練與評估:JHMDB 公開資料集與自建的桌球擊球資料集。
JHMDB
JHMDB(Joint-annotated Human Motion Data Base)是針對動作辨識任務設計的公開資料集 [22] ,涵蓋 21 類日常動作(如跳躍、投球、走路等),共收錄 960 段裁切與標準化的短影片,每段影片僅呈現單一動作,總計 31,838 幀皆具有人工標註,解析度為 320×240,如下圖所示。
-
實驗設定: 本研究依據 HIT Network [9] 的實驗設置,採用官方提供之
split-1分割進行訓練與測試,並以幀級平均精度(frame-level mAP)作為主要評估指標,用以驗證模型的辨識準確性與時間感知能力。 -
標註來源與處理: 人物邊界框、物件偵測與骨架資料皆沿用 HIT Network 提供之偵測結果:
-
訓練與測試處理:
- 訓練階段將骨架關節座標對齊至人工標註的人物框;
- 測試階段則對齊至 YOWO [23] 偵測出的人物框,以強化姿態與人物區域的一致性;
- 手部區域則以左右手腕關節點建立邊界框,強化手部與物件互動建模能力。
 |
|---|
| JHMDB 之範例影格 |
桌球擊球資料集
為驗證所提方法於實際運動情境中辨識細微動作��差異的能力,本研究構建一組具代表性的桌球擊球資料集,涵蓋八類典型擊球動作,並結合時序切片、動作標註與多模態資訊擷取,建構高品質的雙模態輸入。
-
資料來源與拍攝配置
- 資料來源:由 國立中興大學 運動與健康管理研究所 許銘華教授親自示範擊球動作。
- 拍攝設備:Sony HDR-CX450 攝影機,支援 1920×1080 解析度與 60 FPS 高幀率。
- 拍攝位置:固定於球桌長邊側面,鏡頭對準左側選手(右手持拍),模擬比賽視角。
-
動作分類與發球機設定
-
動作分類:共 8 類,分為正手與反手兩大類。
類型 動作名稱 反手 切球、擰球、推球、拉球 正手 切球、平擊、殺球、拉球 -
發球設備:奧奇 TW-2700-E7K 發球機 [29],具備旋轉、頻率、落點等多項控制功能。
-
-
前處理與標註策略
-
滑動視窗切片:每段影片採用長度為 32 幀的視窗(前後各 16 幀),即以時間點為中心進行時序建構。
-
標註階段劃分:
- 前進階段(Forward Phase):語意明確,標註為八類擊球動作。
- 收拍階段(Return Phase):
- 語意模糊,統一標註為 background。
- 訓練階段中,從各類擊球動作中均衡抽取背景樣本,作為非動作區間的學習依據。
- 測試階段則保留完整收拍序列,評估模型在實際情境下的背景辨識能力。
-
類別樣本數量(前進階段):
反手動作 樣本數 正手動作 樣本數 反手切球 1023 正手切球 1049 反手擰球 1002 正手平擊 609 反手推球 1604 正手殺球 901 反手拉球 829 正手拉球 1486 反手總計 4458 正手總計 4045 - 總樣本數 8503 -
資料集切分概況:
資料集 數量 訓練資料(前進階段) 6250 訓練資料(收拍階段) 6250 測試資料(前進階段) 2253 測試資料(收拍階段) 3920
-
 |
|---|
| 滑動視窗切割示意圖 |
-
幾何特徵提取(球拍)
- 採用第 3.1 節所述之 YOLOv11-SEG 模型對球拍進行實例分割,從遮罩中擷取:
- 遮罩面積:反映球拍出現比例
- 中心座標:球拍在畫面中的位置
- 物件框:提供空間參考
- 上述資訊有助於判斷揮拍起始,提升動作邊界判別能力與模型時序感知效果。
- 採用第 3.1 節所述之 YOLOv11-SEG 模型對球拍進行實例分割,從遮罩中擷取:
-
骨架特徵提取(Skeleton)
- 使用 Ultralytics [14] 官方 YOLOv11-Pose 進行 2D 人體姿態估計。
- 模型輸出包含 17 個 COCO 格式關節點位置,涵蓋頭部、軀幹、四肢等。
- 預測準確、運作穩定,為骨架模態建模提供基礎,輔助模型捕捉動作語�意變化。
評估標準
本研究採用下列三種主要評估指標,用以衡量多類別擊球辨識模型的效能:
混淆矩陣
-
觀察分類正確性與誤判情形。
-
構成元素:
- TP(True Positive):正確預測為該類別。
- FP(False Positive):錯誤預測為該類別。
- FN(False Negative):未正確預測該類別。
- TN(True Negative):正確排除非該類別。
-
有助於掌握易混淆的類別組合,提供後續優化參考依據。
-
常用於視覺化模型在各類別間的預測分布。
 |
|---|
| 混淆矩陣 |
分類指標
-
三項指標皆以百分比形式呈現:
-
精確率 (Precision):預測為該類別的樣本中,有多少是正確的。
-
召回率 (Recall):實際屬於該類別的樣本中,有多少被正確預測。
-
F1-score:精確率與召回率的調和平均,評估分類整體平衡。
-
總體評估指標
-
所有類別在評估中具相同權重,避免多數類別主導結果。
-
適用於類別分布不均的情境,能反映整體分類的平衡性與穩定性。
- :第 類別的指標數值
- :總類別數
JHMDB 結果分析
-
分類穩定性與語意連貫性分析:
- 為評估模型於動作序列中的語意一致性,觀察 shoot ball與 shoot bow兩動作的預測結果。
- 每影格左上角顯示預測類別,綠色代表正確、紅色代表錯誤,用以比較預測穩定度。
-
HIT Network 表現:
-
僅依賴單幀骨架,缺乏時序建模能力。
-
常因關節構型相似而產生錯誤:
shoot ball起跳階段 → 誤判為jump- 手臂下垂階段 → 誤判為
catch - 落地階段 → 誤判為
run shoot bow準備與拉弓階段 → 誤判為pour或shoot gun
-
顯示其無法穩定辨識語意轉變與動�作邊界。
-
-
本研究方法表現:
-
結合:
- 多幀骨架時序建模 → 把握動作脈絡變化。
- 影像模態語意輔助 → 穩定跨幀預測。
-
結果顯示:
- 能正確辨識整段
shoot ball與shoot bow動作。 - 對動作階段有良好一致性與語意理解。
- 能正確辨識整段
-
-
數據比較結果:
模型 Precision Recall F1-score HIT Network [9] 83.9% 82.4% 82.4% Our Proposed Method (w/o racket) 84.2% 83.8% 83.8% -
提升原因:
- 利用多幀骨架資訊學習語意脈絡。
- 有效降低誤判與遺漏,提升分類準確性與穩定性。
 |
|---|
| shoot ball 動作之預測結果比 |
 |
|---|
| shoot bow 動作之預測結果比較 |
- 實驗結果:
桌球擊球資料集結果分析
為驗證本研究資料集上各類動作辨識模型的分類效能,透過混淆矩陣、量化指標與視覺分析進行比較。以下各節依模型設計理念進行探討。
SlowFast ResNet:單模態特徵表徵的侷限
-
實驗設定:
- 採用 SlowFast ResNet 作為 RGB 單模態骨幹。
- Slow 分支提取語意、Fast 分支捕捉細節變化。
-
侷限分析:
- 僅倚賴外觀與動作紋理,缺乏結構性與動態建模。
- 對於姿態相似的細微擊球動作易混淆。
-
整體表現:
- 如下圖所示的混淆矩陣揭示其混淆情形。
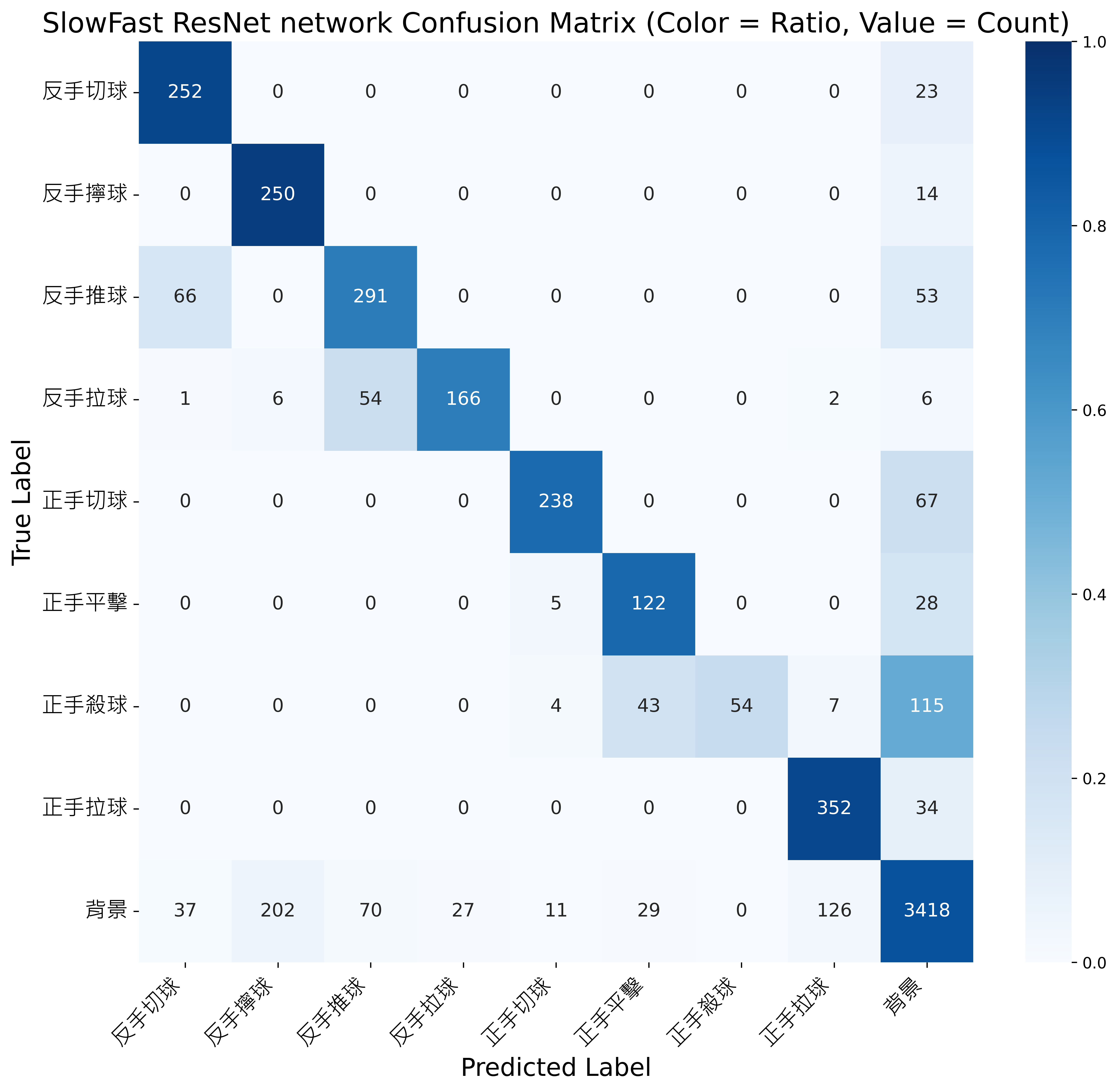
SlowFast ResNet 模型之混淆矩陣結果 - 平均分類表現如下:
Model Precision Recall F1-score SlowFast ResNet [21] 77.8% 76.4% 73.4%
HIT Network:單幀骨架導致的方向模糊與時序限制
-
設計特點:
- 使用單幀骨架輸入,提升效率但喪失時序連貫性。
-
問題一:方向性模糊
- 無法分辨前進階段與收拍階段。
- 缺乏時間動態,導致語意判斷模糊。
- 如下圖所示:
- (左) 預測錯誤的收拍影像。
- (中) 收拍姿態 vs. (右) 前進姿態差異極小。

單幀骨架姿態之方向性模糊示意圖 -
問題二:姿態歧義
- 不同類別若骨架構型相似,容易誤判。
- 單幀缺乏跨幀動作上下文(temporal context),難以辨識微小差異。
- 如下圖所示,舉例說明:
- 將「正手平擊」誤判為「正手切球」。

單幀骨架姿態之姿態歧義示意圖
(左) 測試樣本之錯誤預測結果 (GT: 正手平擊, Pred: 正手切球)
(中) 錯判樣本之骨架姿態 (正手平擊)
(右) 類似姿態之正確樣本骨架 (正手切球)- 將「反手推球」誤判為「反手切球」。

單幀骨架姿態之姿態歧義示意圖
(左) 測試樣本之錯誤預測結果 (GT: 反手推球, Pred: 反手切球)
(中) 錯判樣本之骨架姿態 (反手推球)
(右) 類似姿態之正確樣本骨架 (反手切球) -
混淆矩陣觀察:
- 下圖顯示常見誤判組合:
- 「反手拉球」誤為 background。
- 「正手平擊」與「正手切球」高度混淆。
- 「反手推球」與「反手切球」易混淆。
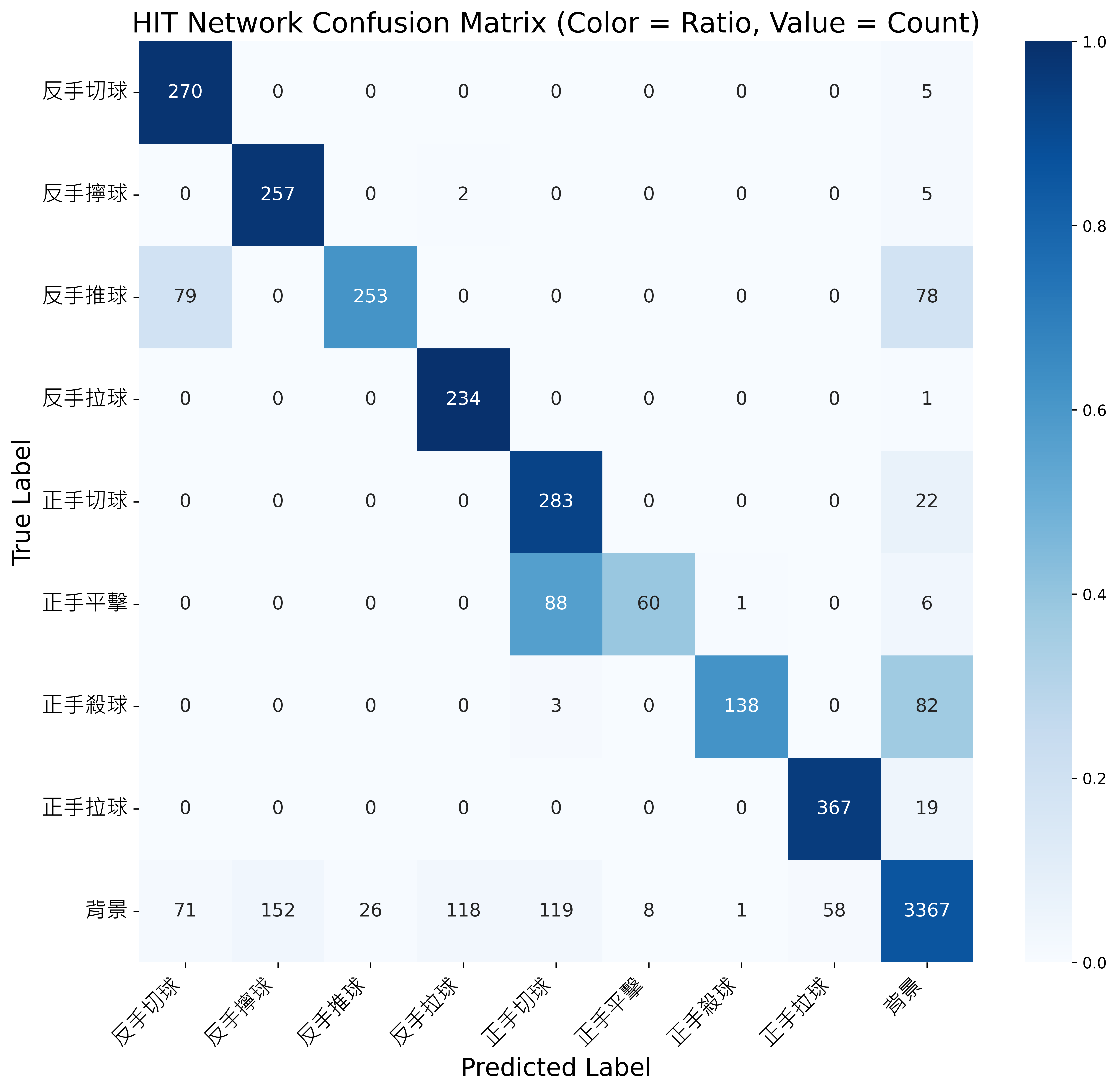
HIT Network 模型之混淆矩陣結果 - 下圖顯示常見誤判組合:
-
整體表現:
Model Precision Recall F1-score HIT Network [9] 78.7% 81.2% 76.4%
SkateFormer 分析:時序建模強化模型能力但關節遮蔽影響辨識穩定性
-
設計特點:
- 採用多幀骨架序列進行建模。
- 時序區塊結合空間與時間的分區(Skate-MSA),強化關節間的連續性與動態交互。
-
分類優勢:
- 如下圖所示,混淆矩陣集中於對角線,表示分類結果一致且準確。
- 可有效區分如「正手切球」、「正手平擊」、「反手推球」等動作順序或幅度細微差異的類別。
- 彌補單幀骨架模型對相似姿態難以辨識的弱點,展現優異的語意理解力。
-
遮蔽限制:
- SkateFormer 完全依賴姿態估測結果,當關節因遮蔽而遺失或錯位時,將導致骨架劣化 (pose degradation)。
- 如下圖所示:
- (左) 正手平擊中,所有關節皆穩定辨識。
- (中)(右) 在反手切球與反手推球中,左手因被軀幹遮蔽導致節點消失或錯誤,破壞動作的連續性。

遮蔽導致關節點遺失與骨架劣化之示意圖
(左) 所有關節節點皆穩定辨識(正手平擊)
(中) 左手被遮蔽導致節點遺失(反手切球)
(右) 左手被遮蔽導致節點遺失(反手推球) -
混淆矩陣觀察:
- 類別間無明顯誤判集中的橫列或縱列,顯示 SkateFormer 於整體分類上具有高一致性與穩定性。
- 然而,若觀察「反手切球」與「反手推球」等易受遮蔽影響之類別,仍可發現些微非對角線的誤判分布,顯示骨架節點遺失在局部區段仍可能影響動作辨識的準確性。
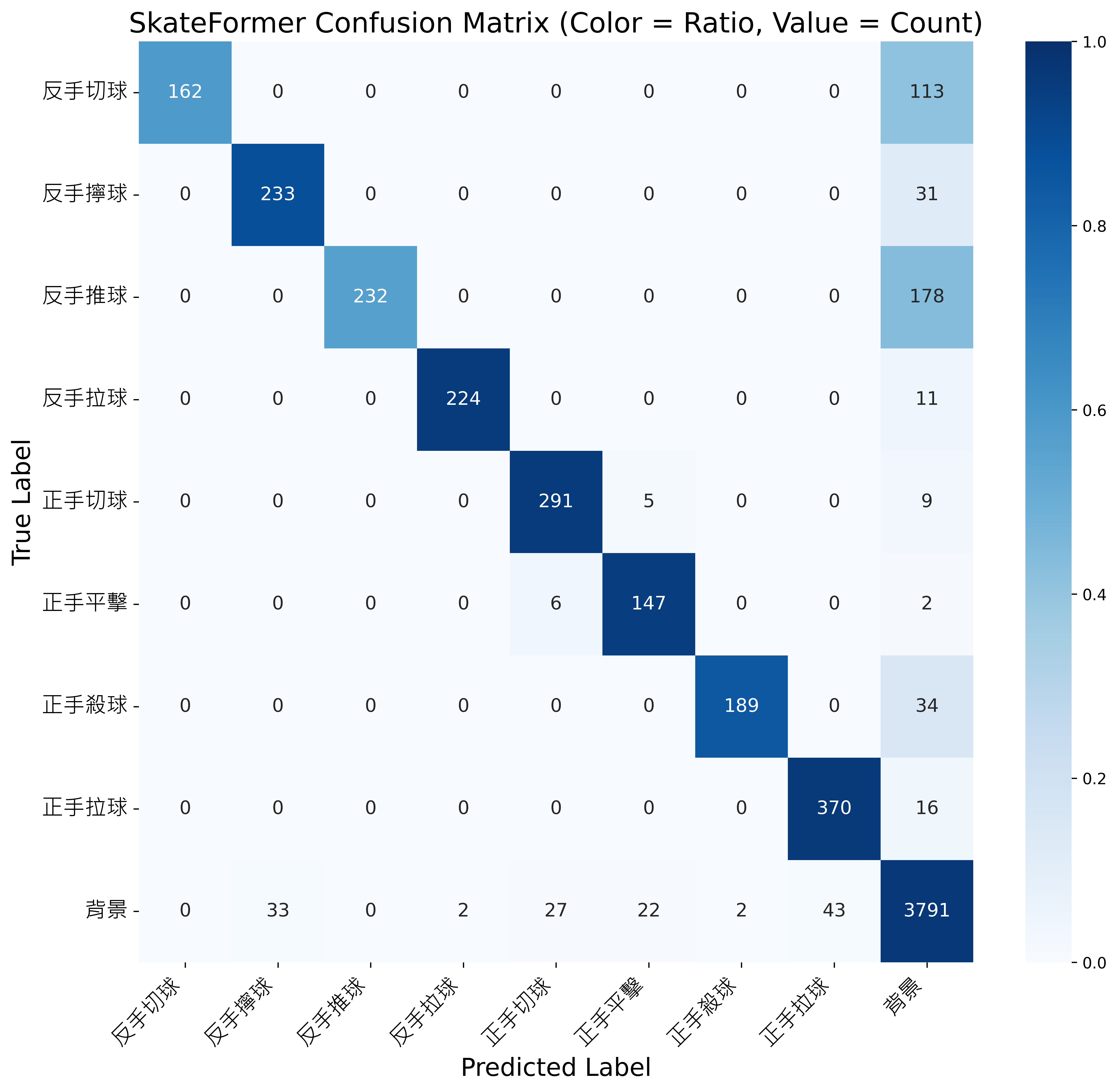
SkateFormer 模型之混淆矩陣結果 -
整體表現:
- 相較於 HIT Network 與 SlowFast 等基準模型,SkateFormer 在辨識正確性與語意理解力方面表現更佳,能有效捕捉關節間的連續變化與動作語意資訊。
Model Precision Recall F1-score SkateFormer [7] 93.3% 85.2% 87.9%
本研究方法(不含球拍資訊):跨模態特徵互補提升分類效果
-
設計特點:
-
互補優勢:
- 骨架估測品質下降時,RGB 模態仍能提供動作語意依據。
- 實作上無需額外引入球拍資訊,即可有效增強穩定性與分類準確度。
-
混淆矩陣觀察:
- 如下圖所示,混淆矩陣分布更加集中於對角線。
- 整體分類穩定性與一致性優於 SlowFast、HIT、SkateFormer。
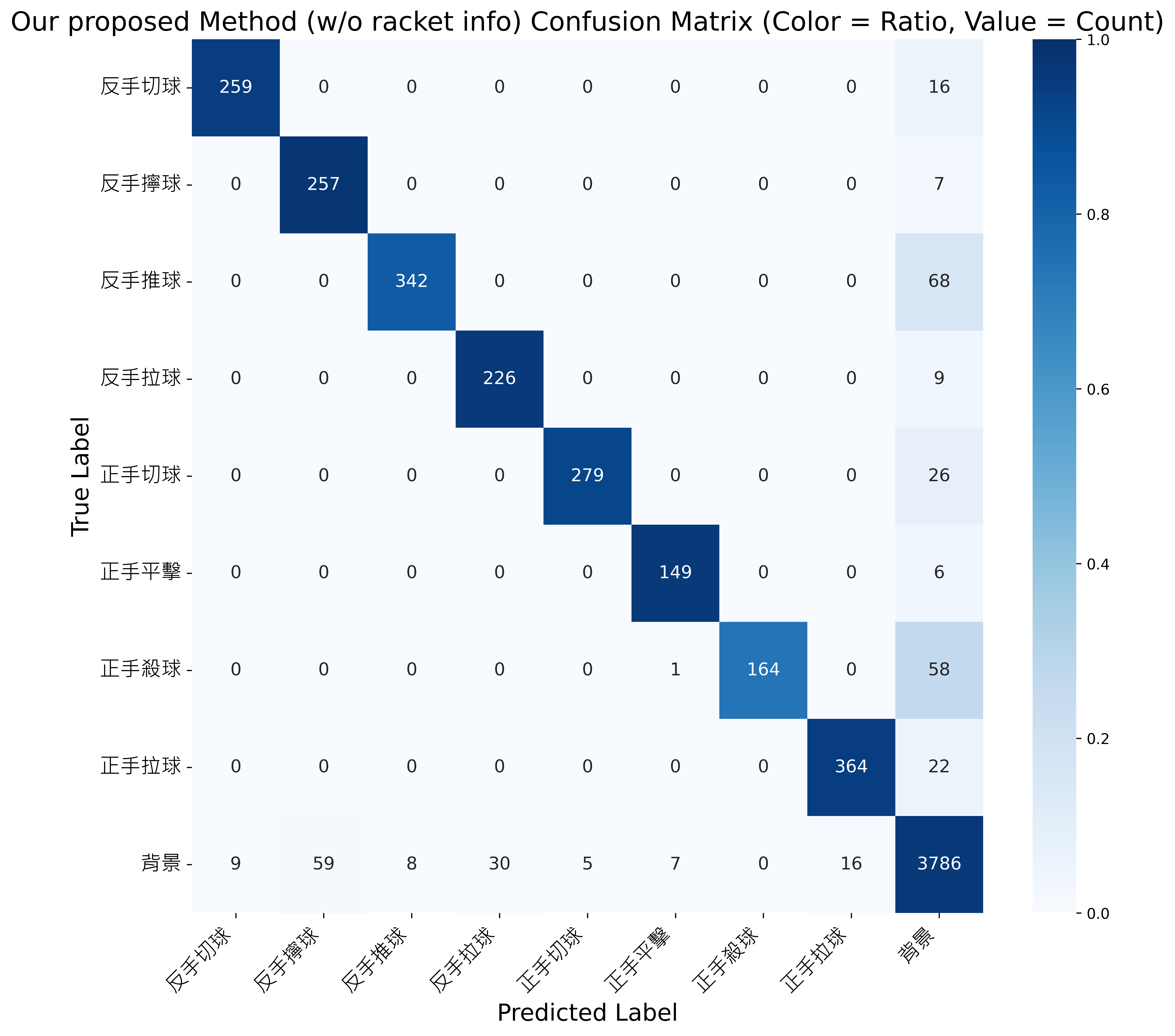
本研究方法(不含球拍資訊)之混淆矩陣結果 -
整體表現比較:
Model Precision Recall F1-score SlowFast ResNet [21] 77.8% 76.4% 73.4% HIT Network [9] 78.7% 81.2% 76.4% SkateFormer [7] 93.3% 85.2% 87.9% Our Proposed Method (w/o racket info) 94.2% 91.5% 92.4%
本研究方法(引入球拍資訊):強化動作邊界辨識
-
研究觀察與設計動機:
- 分析結果顯示,每次擊球平均涵蓋約 31 張影格。
- 模型於「動作起始與結束」時出現錯誤率顯著上升,推論為邊界模糊問題(boundary ambiguity)。
- 欲強化邊界辨識,故引入球拍幾何資訊(區域面積與中心座標)作為額外輔助特徵。
-
平均影格統計:
反手動作 平均影格數 正手動作 平均影格數 反手切球 27.5 正手切球 33.9 反手擰球 29.3 正手平擊 31.0 反手推球 31.5 正手殺球 27.9 反手拉球 33.6 正手拉球 29.7 - 平均 30.6 -
引入球拍幾何資訊的效益:
- 前進與收拍階段的球拍面積與位置存在幾何差異,可作為邊界判斷依據。
- 輔助克服滑動視窗缺乏明確動作起訖點的侷限。
- 提升模型在時序邊界處的解析穩定性與分類精度。
-
錯誤率熱圖觀察:
- 下圖為模型錯誤率分布(每段標準化至 31 格),比較未引入與引入球拍資訊前後的差異。
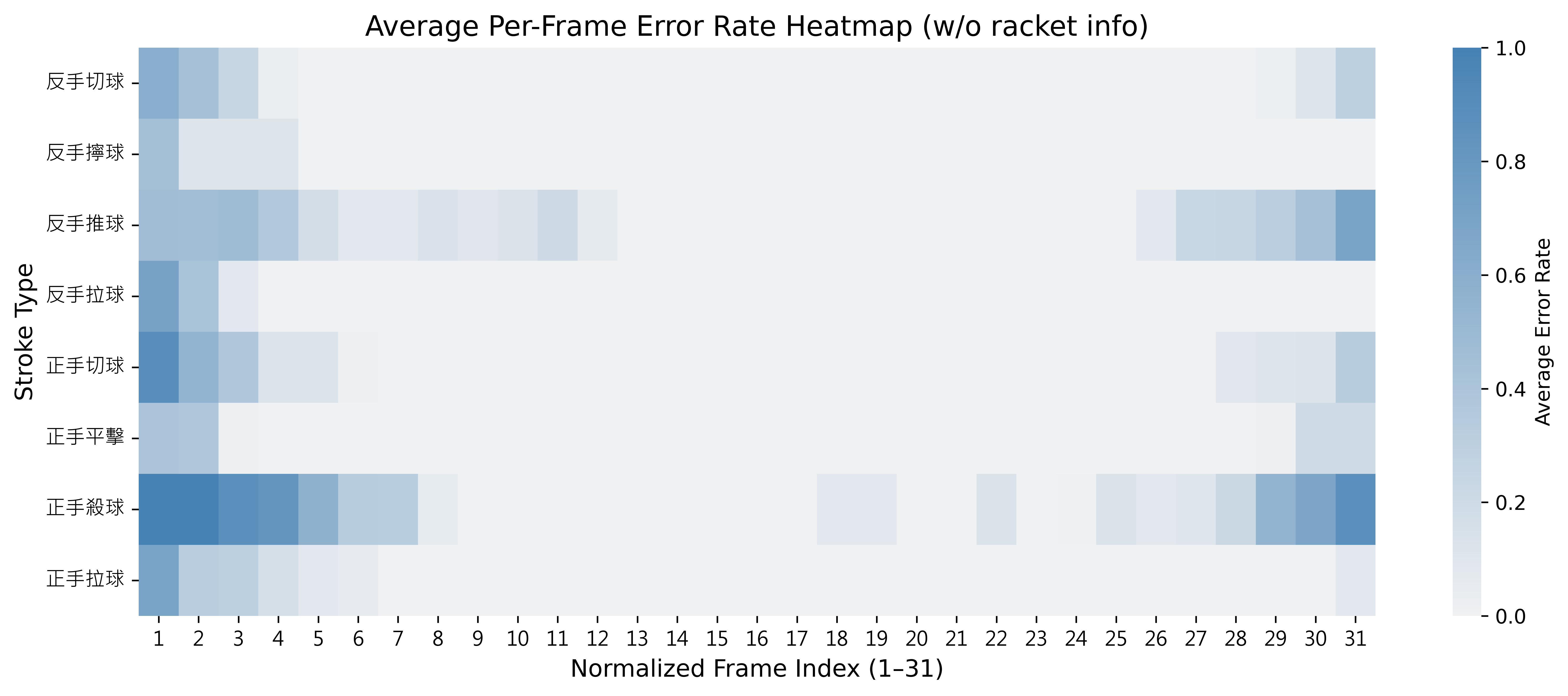
未引入球拍資訊下模型於動作邊界處之錯誤率分布 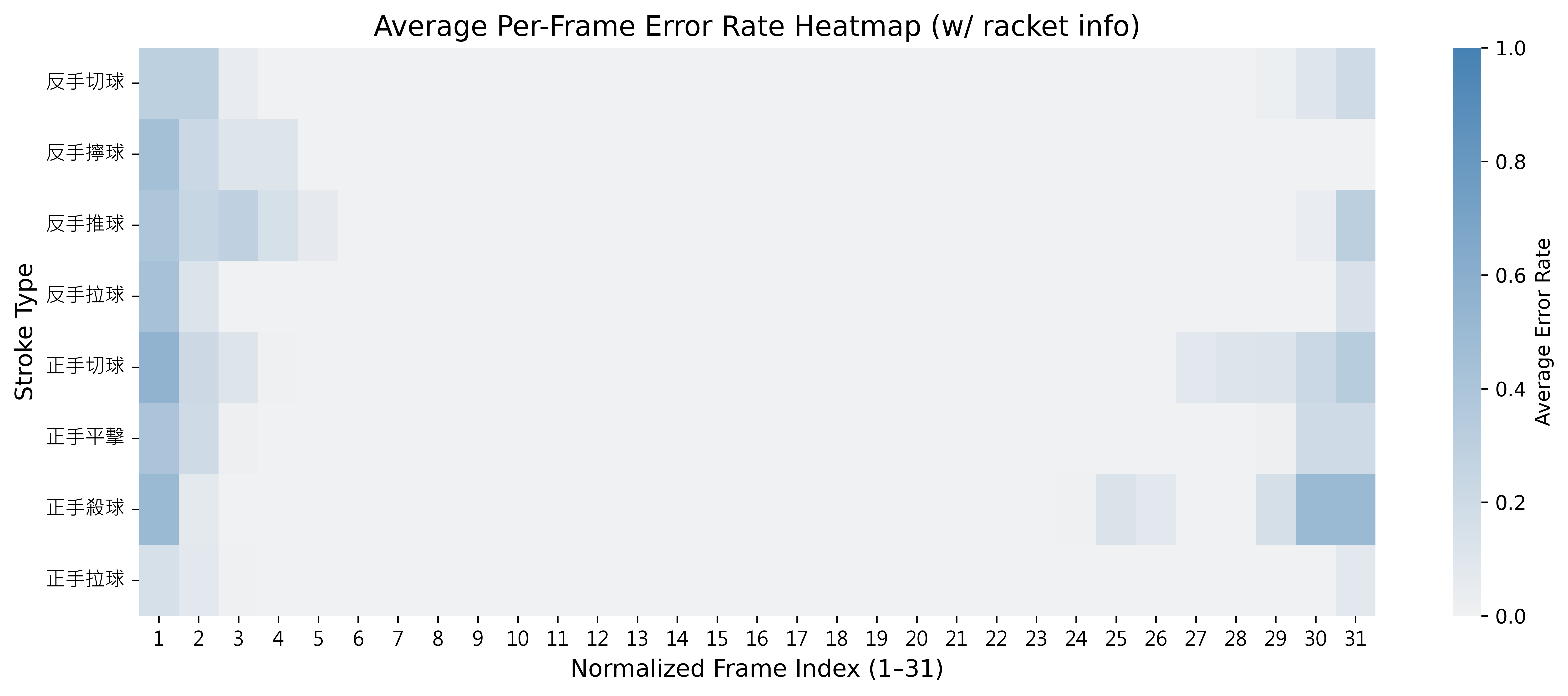
引入球拍資訊下模型於動作邊界處之錯誤率分布 -
整體分類效能比較:
Model Precision Recall F1-score Our Proposed Method (w/o racket info) 94.2% 91.5% 92.4% Our Proposed Method (w/ racket info) 96.1% 96.4% 96.2%
桌球擊球資料集實驗結果
-
辨識結果視覺化:
- 動作類別顯示於畫面左上角,綠色為正確,紅色為錯誤,方便判讀。
-
輔助資訊同步顯示:
- 每一影格標示球拍中心位置與面積,輔助辨識動作邊界。
- 顯示骨架姿態與球拍遮罩,呈現多模態輸出。
-
辨識效能優異:
- 模型能穩定辨識八類正反手動作,具良好時序與語意理解能力。
-
驗證模型設計有效性:
- 骨架建模與球拍幾何特徵設計,有效提升對相似動作的辨識力,展現實用潛力。
結論與未來展望
研究結論重點
- 雙模態架構:本研究提出結合 2D 骨架(SkateFormer) 與 RGB 影像(SlowFast ResNet) 之動作辨識架構,強化跨模態語意互補與特徵融合能力。
- 遮蔽問題解決:骨架模態建構時空依賴,RGB 模態補足遮蔽與估測誤差,提升整體辨識穩定性與準確率。
- 邊界辨識設計:分析擊球動作平均長度約為 31 幀,錯誤集中於起始與終止階段,導入 球拍幾何特徵(面積+中心) 作為輔助模態,有效改善動作邊界判斷。
- 效能優勢:本方法在桌球資料集上達到 Precision 96.1%、Recall 96.4%、F1-score 96.2%,優於 HIT、SkateFormer 與 SlowFast ResNet。
- 泛化能力:於 JHMDB 資料集亦達到 84.2% / 83.8% / 83.8% 的指標表現,證實具備良好跨任務遷移能力。
- 可視化驗證:透過影片疊加動作預測、骨架姿態與球拍資訊,直觀呈現系統準確性與語意理解能力。
未來展望方向
- 動態球拍建模:未來可拓展球拍資訊為揮拍速度、方向變化等時序特徵,增強動作語意建模深度。
- 3D 姿態擷取:現階段骨架模態為 2D 姿態,建議結合多攝影機系統以進行 3D 姿態重建,提升辨識精度與結構完整性。