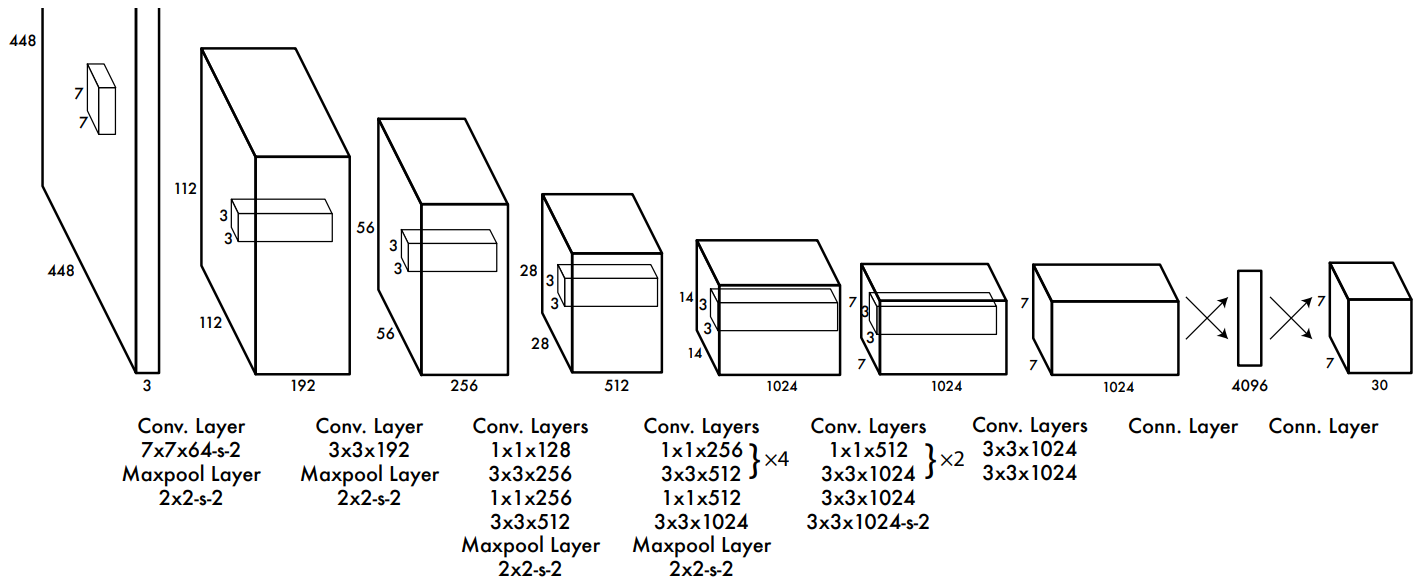
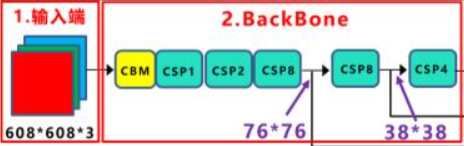
YOLO Backbone 的演進
YOLO 的 backbone 演進,並不是單純「越做越深」,而是一條讓深度可訓練、梯度可流動、計算可控的設計路線。
Classification → Detection Backbones
早期 YOLO 並沒有為 detection 設計專用 backbone,而是直接沿用分類模型。
- YOLOv1–v2
- 使用類分類 CNN(YOLOv1 自建 CNN、YOLOv2 的 Darknet-19)
- 優點是結構簡單、速度快
- 但特徵表達能力有限,難以同時支撐多尺度與精細定位
- 關鍵問題
- 分類 backbone 追求語意抽象
- Detection 需要同時保留 空間細節 + 語意層級
- 這個衝突在小物體與密集場景中特別明顯
 |  |
|---|---|
| YOLOv1 Custom CNN | YOLOv2 Darknet-19 |
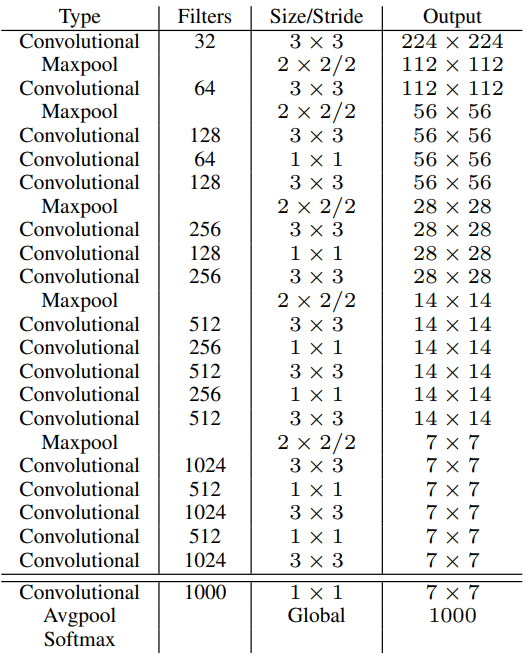
Residual Backbone:讓深度可用(YOLOv3)
YOLOv3 是第一個真正解決 backbone 深度問題的版本。
- Darknet-53
- 引入 residual connection
- 讓梯度可以穩定傳遞到深層
- 設計意義
- backbone 不再只是「跑得快」
- 而是開始能承載多尺度特徵學習
- 影響
- 為後續 multi-scale prediction、FPN / PAN 打下基礎
- YOLO 開始進入「可長期演化」的架構狀態
但這一代的問題是:深度增加 ≠ 計算效率好。
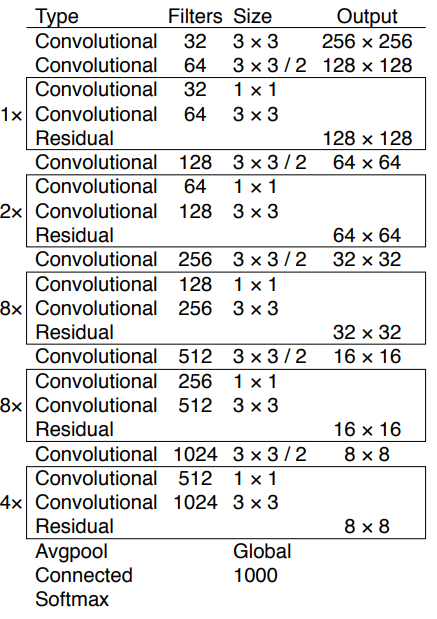
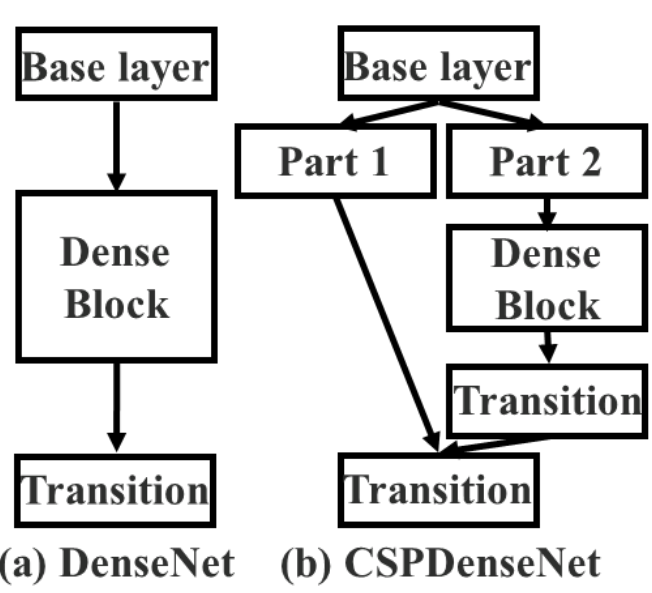
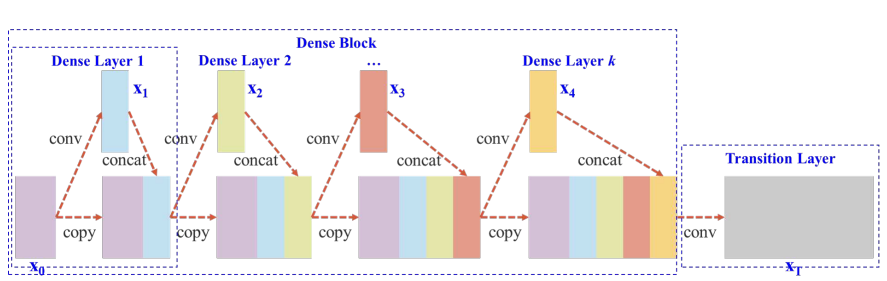
CSP:不是加深,而是「切開」梯度流
CSP(Cross Stage Partial Network)的提出,不是為了做一個更深的 backbone,而是為了解決深度 CNN 中一個被忽略的問題:
大量重複的梯度資訊,正在浪費計算與學習能力
Residual / Dense 的效率瓶頸
即使是 ResNet 或 DenseNet 這類「梯度友善」的架構,仍存在結構性問題:
- 在 residual / dense 架構中:
- 每一層都會接收到來自所有前層的梯度
- 梯度路徑雖然變短,但資訊高度相關
- 結果是:
- 不同層學到高度重複的梯度資訊
- 造成:
- 不必要的計算
- 記憶體流量(memory traffic)增加
- 訓練與推論效率下降
Residual 解決了「梯度消失」,但沒有解決「梯度重複」。
CSP 的核心假設
CSPNet 明確提出一個假設:
CNN 的效能瓶頸,不只是深度或寬度, 而是「不同層是否真的學到不同的資訊」。
因此 CSP 的目標不是增加 capacity,而是:
- 最大化梯度組合的多樣性(gradient combination diversity)
- 最小化重複梯度造成的無效學習
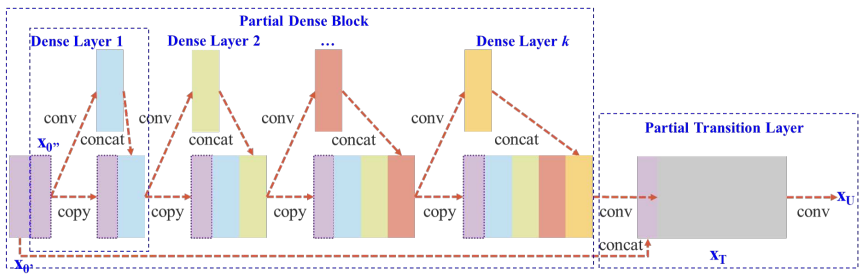
CSP 的核心做法
不讓所有 feature 都參與所有層的梯度回傳,而是刻意截斷一部分梯度流。
具體作法是:
- 在一個 stage 開始時:
- 將輸入 feature map 沿 channel 切成兩部分
- 兩條路徑:
- Path A:直接 bypass(不進入深層 block)
- Path B:進入完整的 residual / dense block
- 在 stage 結尾:
- 先對 Path B 做 transition(如 conv / pooling)
- 再與 Path A concat
- 刻意選擇「fusion last」策略以截斷梯度重用
 |  |
|---|---|
| DenseNet | Cross Stage Partial DenseNet |
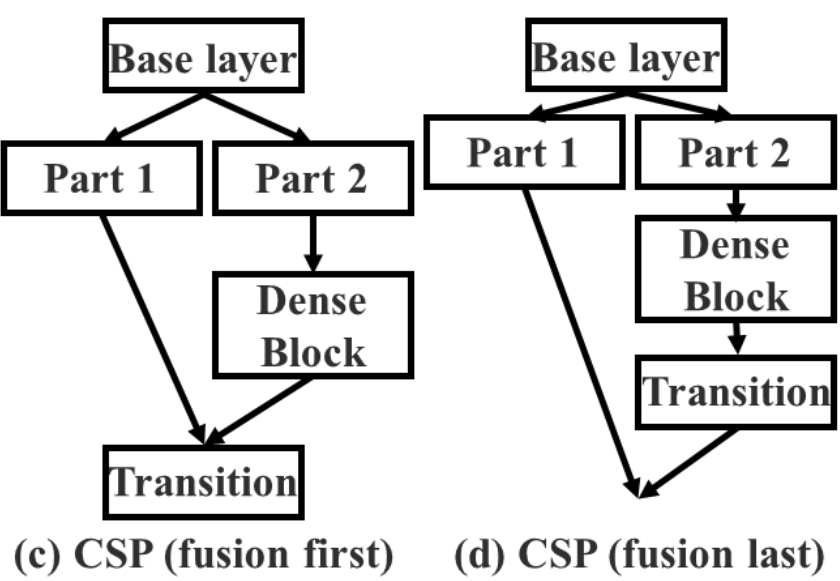
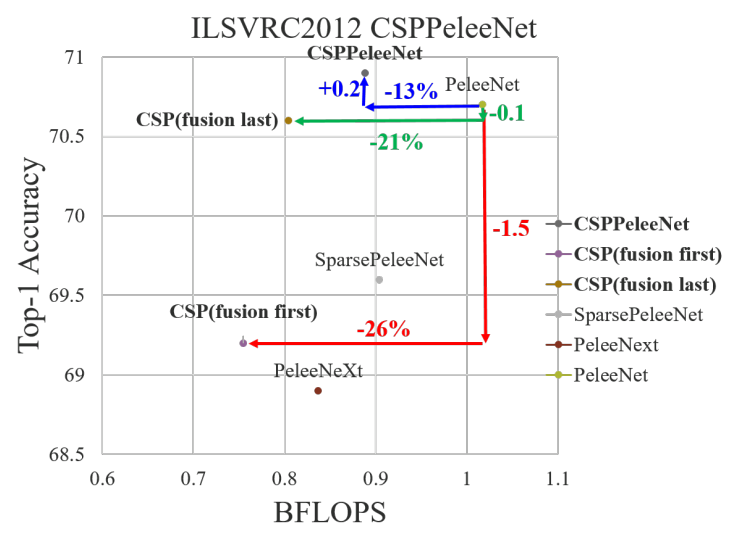
為什麼一定要「fusion last」?
相關論文做了非常關鍵的 ablation:
- Fusion first(先 concat 再 transition)
- 梯度仍然高度重複
- 計算下降,但 accuracy 明顯掉
- Fusion last(先 transition 再 concat)
- 梯度流被有效截斷
- 計算量下降 20%
- Top-1 accuracy 幾乎不變(僅 ~0.1%)
 |  |
|---|---|
| Fusion Fisrt 和 Fusion Last 的模型架構 | Fusion Last 明顯比 Fusion First 好 |
這證實 CSP 的關鍵不是結構形式,而是 「避免不同路徑學到相同梯度訊號」。
CSP 解決的三個實際問題
CSPNet 它同時解決三個工程層面的問題:
- 強化 learning capability
- 在計算更少的情況下,模型反而學得更好
- 特別對 lightweight backbone 效果顯著
- 降低 computational bottleneck
- 計算不再集中在少數層
- 提升硬體 utilization(GPU / CPU / ASIC)
- 降低 memory traffic
- 減少 feature map 的重複讀寫
- 對 edge / embedded 裝置特別重要
在 YOLO 中使用它
- YOLOv4:CSPDarknet-53
- 明顯降低 FLOPs
- 改善梯度流動穩定性
- YOLOv5:CSP-based Backbone
- CSP 成為「工程上可維護」的核心骨幹
- 讓模型 scaling(s / m / l / x)變得可控
 |  |
|---|---|
| YOLOv4:CSPDarknet-53 | YOLOv5:CSP-based Backbone |
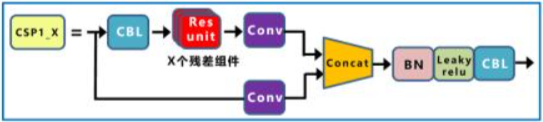
CSP1_X(用在 Backbone)
- 核心設計目的
- 解決 深層網路中梯度重複、學習冗餘 的問題
- 讓 backbone 可以變深,但不讓計算與梯度爆炸
- 結構特徵
- 將輸入 feature 切成兩條路徑
- 主幹路徑:經過多個 Residual / Bottleneck block
- 捷徑路徑:幾乎不做計算,直接保留原始特徵
- 在 stage 結尾進行 Concat + Conv 融合
- 將輸入 feature 切成兩條路徑
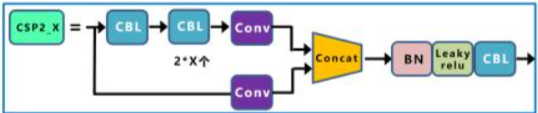
CSP2_X(用在 Neck)
- 核心設計目的
- 降低 Neck 階段的計算量與延遲
- 在特徵已經足夠語意化的前提下,避免過度複雜化
- 結構特徵
- 同樣採用雙分支結構,但:
- 不使用 Residual block
- 改為 連續的 CBS / CBL 卷積
- 整體結構更淺,計算成本更可控
- 同樣採用雙分支結構,但:
- 為什麼不用 Residual
- Neck 的特徵已是融合後的高階語意
- 不再需要深層表示學習,Residual 的收益有限
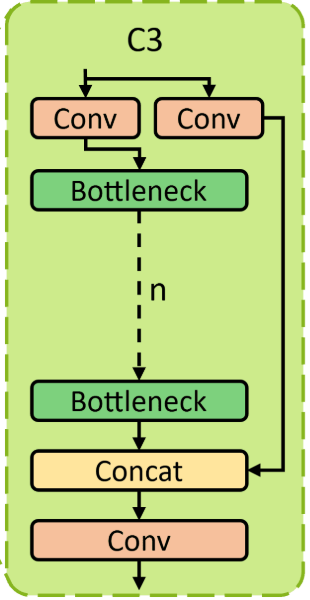
CSP 家族的工程化演進
C3(YOLOv5:經典 CSP Bottleneck)
- YOLOv5 裡的
C3,本質上就是一種 CSP Bottleneck 的實作(常被視為 BottleneckCSP 的變體) - 核心目的
- 把 CSP「分流+拼接」落到工程可用的 backbone/neck block 上:
- 一部分特徵走較深的 bottleneck 堆疊
- 一部分走較淺/捷徑路徑,最後 concat 融合
- 把 CSP「分流+拼接」落到工程可用的 backbone/neck block 上:
- 直觀特徵
- 結構偏「經典 CSP」:split →(n 個 bottleneck)→ concat → fuse conv
- 設計重點在「省計算 + 保梯度」,但模組組合/巢狀程度在後期會顯得較厚重(尤其你要做多任務或更換 head 時)
C2f(YOLOv8:更順暢梯度的輕量 CSP)
- Ultralytics 官方把
C2f定義成 “Faster Implementation of CSP Bottleneck with 2 convolutions” - 核心目的
- 保留 CSP 的「分流精神」,透過中間特徵累積提升特徵重用,使資訊與梯度傳遞更直接且高效
- 與 C3 的關鍵差異
- C3:bottleneck 為封閉堆疊,只輸出最後結果
- C2f:所有中間層特徵一起 concat,使資訊與梯度流更順暢
- 設計特點
- 使用較小的 hidden channels,透過特徵累積提升表達能力,在不增加深度與計算量下提高效率
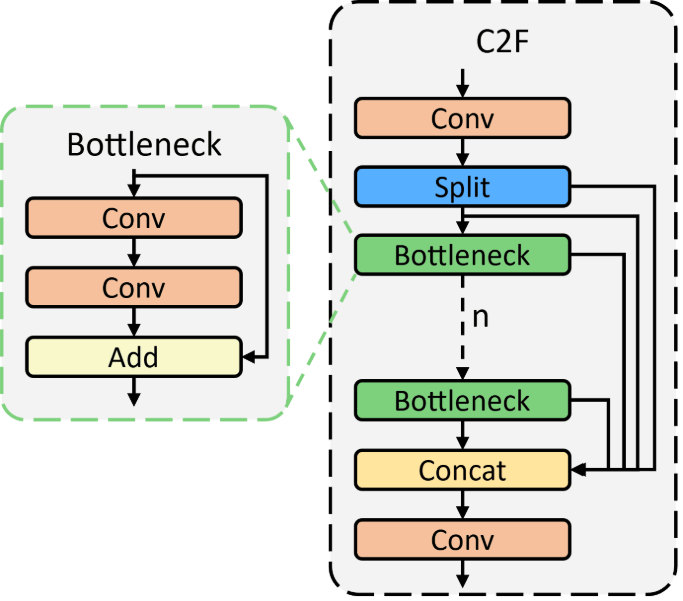
C3k(YOLOv11:可調感受野 CSP)
- Ultralytics 官方對
C3k的描述是:“a CSP bottleneck module with customizable kernel sizes”,而且它是C3的子類別,帶k(kernel size)參數 - 核心目的
- 在不改變 CSP(分流 → 堆疊 → 融合)結構的前提下,將感受野大小透過參數
k(如 3、5)進行控制 - 透過較大的卷積核擴大局部上下文範圍,增強局部區域的上下文建模能力
- 在不改變 CSP(分流 → 堆疊 → 融合)結構的前提下,將感受野大小透過參數
C3k2(YOLOv11:C2f 強化版 CSP)
- Ultralytics 官方文件顯示
C3k2繼承自C2f,並帶有c3k(bool)與attn等參數,用於控制內部單元的類型與表達能力- 它不是「替代 CSP」,而是把 C2f 當底座,中間的重複單元可以切換成更強的
C3k
- 它不是「替代 CSP」,而是把 C2f 當底座,中間的重複單元可以切換成更強的
- 核心目的
- 在保留 C2f 輕量與良好梯度流的前提下,提供可選的表達能力增強
- 當
c3k=True時,將內部重複單元替換為較大卷積核的C3k,以提升區域上下文建模能力
- YOLOv11 中的使用方式
- 淺層(高解析度)階段維持
c3k=False以降低計算量 - 深層(低解析度)階段才啟用
c3k=True,在較低成本下提升上下文建模能力
- 淺層(高解析度)階段維持
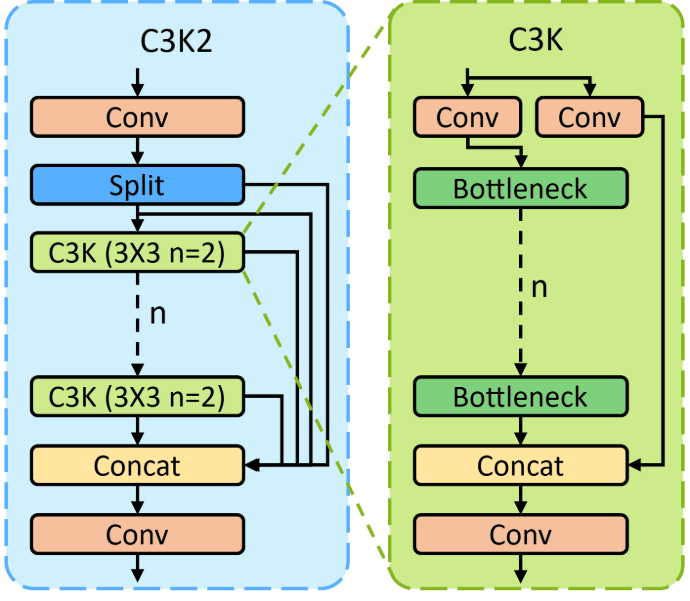
設計問題的升級:從「效率」到「可擴展性」
CSP 及其工程化版本(C3 / C2f / C3k2)已經成功解決:
- 梯度重複與計算冗餘
- FLOPs 與 memory traffic 問題
- 即時推論的效率瓶頸
但在實務中,許多高效 backbone 開始採用 concat-based aggregation(如 DenseNet、VoVNet、CSPVoVNet),這類架構帶來新的挑戰:
模型擴展不再穩定
模型變大後,常出現收斂變慢、性能提升有限甚至退化的現象,其原因並非計算量不足,而是:
模型擴展會改變梯度路徑分佈,導致梯度傳遞結構失衡。
Feature Aggregation 造成資訊退化
在深層網路中,多次的 concat、residual 與 feature fusion 會使不同層特徵過度混合,進而造成:
深層特徵影響力被稀釋,有效訊號比例下降,使模型容量增加但表示能力未同步提升。
ELAN:從「深」轉向「梯度路徑設計」
這條演進主軸的核心不是「加深網路」,而是:
控制梯度流與資訊保留,而不是單純增加層數或參數。
ELAN 出現前:Concat-based 的問題
在 ELAN 之前,YOLO 系列 backbone 的演進其實已經經歷過一條重要路線:
Dense-style aggregation → VoVNet → CSPVoVNet
這條線的核心問題是:
Concat 雖然能強化特徵融合,但當模型加深時,會導致計算成本與梯度傳遞結構逐漸失衡。
-
DenseNet
- Dense-style aggregation 透過大量 concat 帶來強特徵重用與順暢的梯度傳遞,但其代價是:
- 每層都與所有前層 concat,channel 持續膨脹
- 記憶體存取與計算成本極高,難以用於即時模型
- Dense-style aggregation 透過大量 concat 帶來強特徵重用與順暢的梯度傳遞,但其代價是:
-
VoVNet(One-Shot Aggregation)
- VoVNet 嘗試在保留 multi-layer aggregation 的前提下,解決 DenseNet 的工程瓶頸:
- 多層卷積後 一次性聚合(OSA)
- 避免中間層反覆 concat
- 顯著降低 memory access cost
- 但本質上:
- 所有特徵仍匯入同一條梯度流
- 梯度資訊高度相關,冗餘問題尚未解決
- VoVNet 嘗試在保留 multi-layer aggregation 的前提下,解決 DenseNet 的工程瓶頸:
-
CSPVoVNet
- 為了進一步改善梯度冗餘,研究者將 CSP 的分流思想引入 VoVNet:
- 將 feature 分成兩路
- 一部分進入 OSA block
- 一部分直接 bypass
- 僅在 stage 結尾再進行 concat
- 將 feature 分成兩路
- 這讓模型同時達成:
- 降低重複梯度
- 提升梯度多樣性
- 減少計算量與記憶體流量
- 但在 concat-based 架構持續加深時仍存在限制:
- 深度擴展會改變梯度傳遞路徑長度與分佈
- 影響收斂穩定性與參數利用效率
- 網路深度難以有效擴展
- 為了進一步改善梯度冗餘,研究者將 CSP 的分流思想引入 VoVNet:
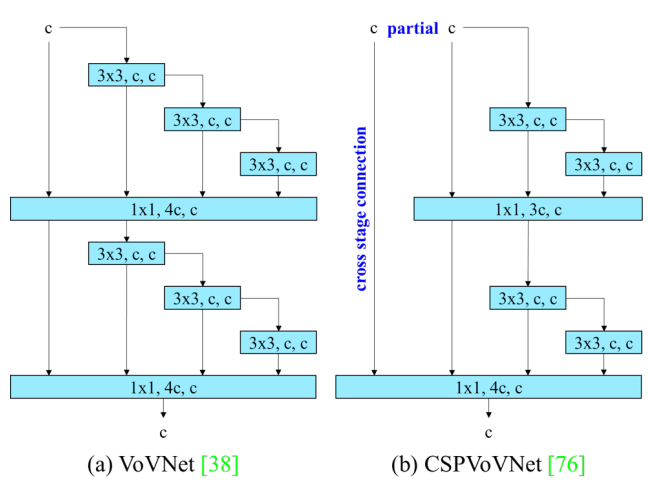
隨著深度增加,梯度路徑長度與分佈逐漸失控,使模型容量增加但學習效率未能同步提升。
ELAN(YOLOv7):控制梯度路徑長度
- 設計背景
- 在 concat-based 架構中,模型加深後的關鍵問題不是計算量,而是梯度傳遞路徑的結構會影響收斂與學習能力
- 設計目標
- 在增加深度與寬度時,保持訓練穩定
- 避免 feature aggregation 破壞梯度資訊
- 核心機制
- 多分支並行卷積堆疊
- 不同深度的分支最後再一次性 concat
- 明確設計不同長度的資訊與梯度路徑
- 關鍵思想
- 控制 最短與最長梯度路徑
- 讓不同層學到的特徵保持多樣性
- 效果
- 可在不影響收斂的情況下擴展模型容量
- 成為 YOLOv7 backbone/neck 的核心模組
ELAN 僅解決了梯度「如何傳遞」,但若各分支學習到的特徵高度重疊,會產生資訊冗餘,導致即便路徑再多,也無法提升資訊的完整性與多樣性。
E-ELAN:可擴展的特徵聚合架構
- 設計動機
- 防止梯度路徑退化:避免因單純堆疊 block 導致梯度路徑過於複雜,進而破壞原有的穩定收斂狀態。
- 突破參數效益瓶頸:解決模型擴張時常見的特徵同質化問題,確保新增的參數能轉化為有效的學習能力。
- 設計目標
- 在擴展模型容量時保持原始梯度路徑完全不變
- 核心機制
- Expand:使用 group convolution 增加 channel 與 cardinality
- Shuffle:將不同 group 的特徵重新排列
- Merge cardinality:重新聚合各 group 特徵
- 僅修改計算 block,不改變 transition layer
- 關鍵價值
- 提升學習能力,但不破壞原有梯度傳遞路徑
- 讓不同 group 學到更具多樣性的特徵
- 效果
- 模型可持續擴展而不影響收斂
- 提升參數與計算利用效率
- 支撐 YOLOv7 大模型(E6 / E6E)
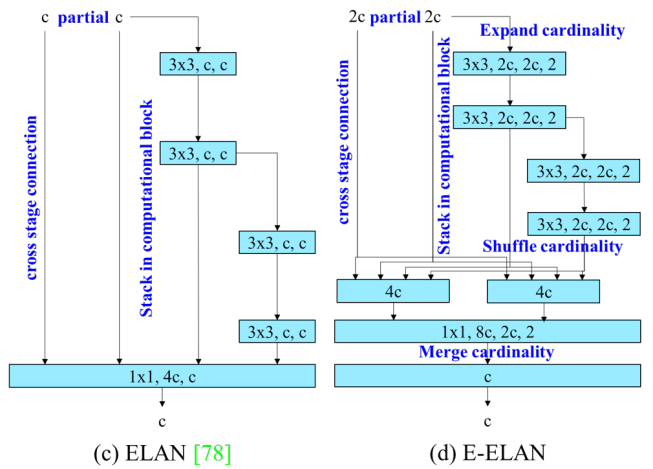
ELAN 家族雖優化了梯度的「傳遞路徑」,但無法解決深層網路因層層下採樣導致的資訊丟失。一旦原始細節在傳遞中遺失,後端的聚合路徑也無法憑空找回,這形成了資訊傳輸的不可逆瓶頸。
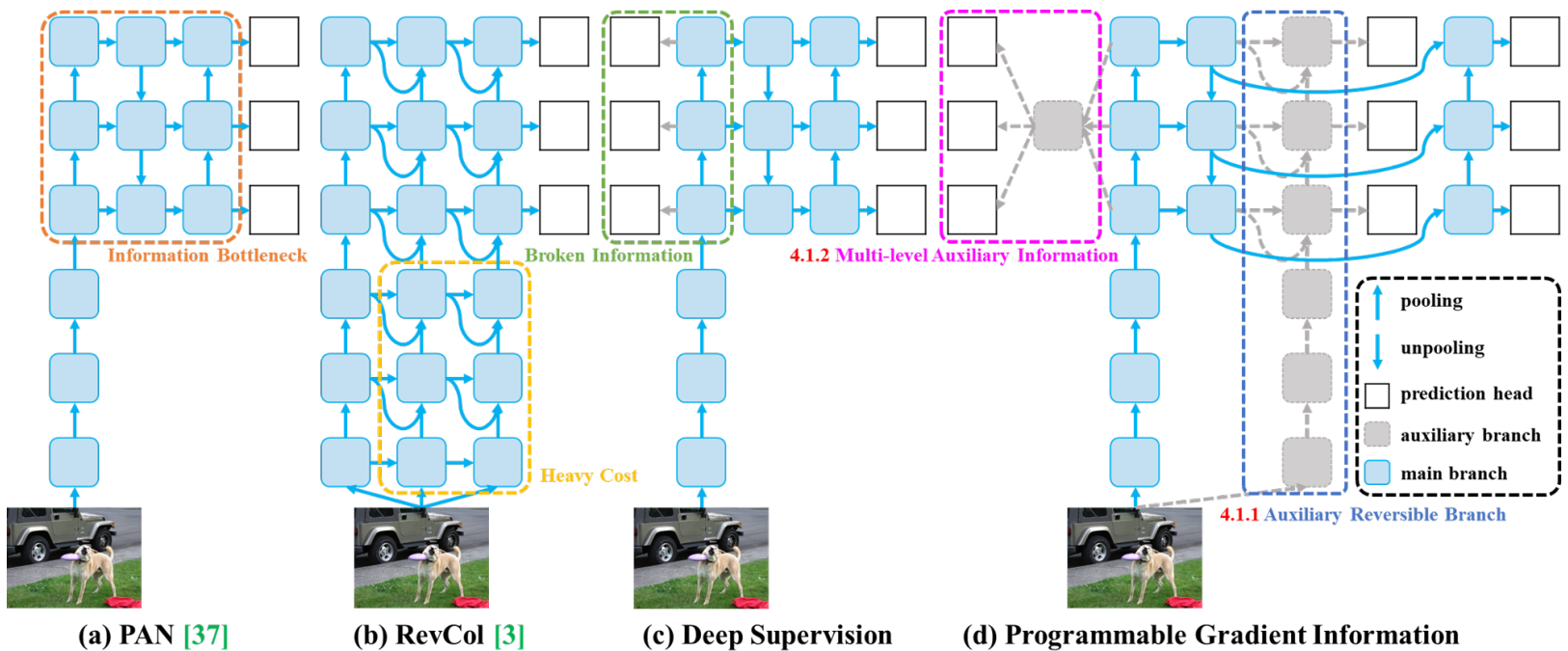
GELAN(YOLOv9):最大化資訊保留
- 設計出發點
- 資訊瓶頸 (Information Bottleneck):深層網路在前向傳遞中會產生資訊退化,導致有效特徵不可逆地消失。
- 無效梯度:當特徵殘缺,Loss 產生的梯度便不可靠,導致收斂變慢且深度擴展失去效益。
- 核心思想
- 從 Information Bottleneck 角度重新設計 backbone
- 在相似計算量下,最大化有效資訊傳遞與參數利用效率
- 讓��模型深度增加時,性能能穩定提升而非飽和或退化
- 結構特徵
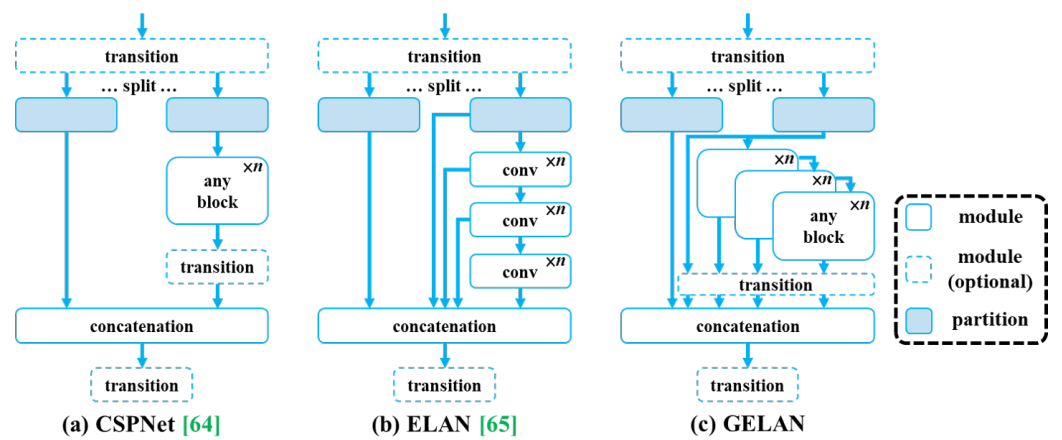
- Generalized ELAN(GELAN):延續 ELAN 的梯度路徑規劃,並融合 CSP 的特徵分流概念
- 採模組化設計,可靈活整合 Conv / Residual / CSP 等單元
- 強調 可擴展性(scalability) 與穩定梯度流
- 搭配機制
- PGI(Programmable Gradient Information)
- 透過 auxiliary reversible branch 提供更完整的資訊來源
- 引入 multi-level auxiliary supervision,提升梯度品質並減少資訊破碎
- 僅在訓練階段使用,推論無額外成本
- PGI(Programmable Gradient Information)
- 效果
- 在相同或更少的 參數與 FLOPs 下取得更高 AP
- 模型加深時性能呈現穩定成長,訓練更穩定
- 在小物體與複雜場景中具有更好的表現
 |
|---|
| 從路徑優化到資訊保留的泛化演進 |
 |
|---|
| PGI 透過輔助分支破解資訊瓶頸 |
這一系列 backbone 的核心不是「多快」,而是「學到的資訊是否被浪費」。