YOLO Label Assignment 演進
Label assignment 的本質問題是:
在 dense prediction 中,一個 GT 對應大量候選框,誰應該負責學習?
不同策略的差異,在於:
- 正樣本數量如何決定
- 是否考慮預測品質
- 是否支援 NMS-free
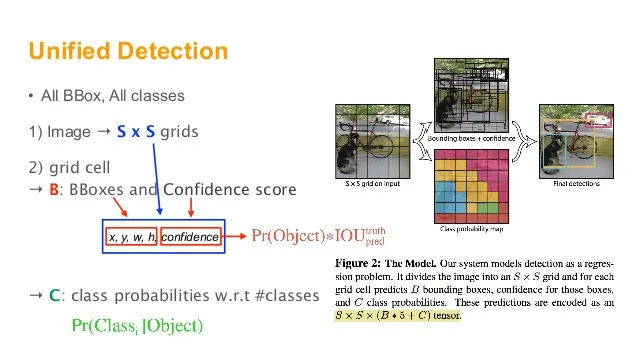
空間責任分配(Grid-based)
Grid-based Responsibility(YOLOv1)
- 設計動機
- 以固定空間責任分配,將 detection 轉為單次前向的回歸問題
- 結構簡單、計算量低,符合 early real-time 設計目標
- 設計方式
- 將影像劃分為 (S \times S) grid
- 物體中心落在哪個 grid cell,該 cell 負責預測
- 每個 cell 預測 (B) 個 bounding boxes
- 在該 cell 中,IoU 最大的 predictor 作為正樣本
- 核心特性
- Cell-level one-to-one:每個物體只屬於一個 cell(由中心決定)
- Predictor-level one-to-one:每個物體僅由一個 box 負責
- Assignment 僅依賴位置與 IoU
- 主要問題
- 空間分辨率受限:難以處理密集或小物體場景
- 缺乏尺度先驗:需直接回歸各種尺寸,學習困難
- 匹配機制僵硬:無法依預測品質動態調整
問題
固定的空間責任分配缺乏彈性,難以應對密集與多尺度場景。
固定規則匹配(Anchor-based)
Anchor-based 階段的核心邏輯是**「先驗幾何決定責任」**,其特點與侷限如下:
- 空間與形狀雙重約束:正樣本必須同時滿足「中心落在特定網格」與「形狀符合 Anchor 模板」兩個硬性條件。
- 預測無關(Prediction-agnostic):分配過程僅依賴幾何關係(IoU、比例、距離),完全不參考模型當前的預測品質(如分類信心度或精確位置)。
- 正樣本擴展趨勢:演進過程從 One-to-One(YOLOv2 的 Best-IoU)轉向 One-to-Many(YOLOv5 的 Cross-grid),透過增加監督訊號來加速收斂。
- 主要瓶頸:
- 規則生硬:無法處理形狀極端或重疊嚴重的物體。
- 目標衝突:有時幾何位置最接近的 Anchor,其預測品質反而不如較遠的 Anchor,導致訓練效率低下。
問題
固定規則匹配僅考慮「位置是否靠近」或「形狀是否相似」,卻忽略了**「預測得準不準」**。
Best-IoU Matching(YOLOv2–YOLOv4)
- 設計動機
- 引入 anchor 尺寸先驗,降低回歸難度
- 透過固定規則匹配,保持訓練簡單且穩定
- 設計方式
- 每個 GT 僅在其中心所在的 grid cell 中匹配
- 計算該 cell 內所有 anchors 與 GT 的 IoU:
- 選擇 IoU 最大的 anchor 作為正樣本:
- 標籤定義:
- 核心特性
- Anchor-level one-to-one:每個 GT 僅在其對應尺度與 grid cell 中匹配一個最佳 anchor
- Assignment 僅依賴 位置與 IoU
- 正樣本數量固定,與模型預測無關
- 主要問題
- 正樣本稀少,監督訊號有限
- 不考慮分類或定位品質
- 在密集場景中可能出現正樣本不足
Ignore Mechanism(YOLOv3–YOLOv5)
- 設計動機
- 避免與 GT 高重疊的 anchors 被誤當為負樣本
- 減少正負樣本衝突,提升訓練穩定性
- 設計方式
- 對非最佳匹配但�與 GT 高重疊的 anchors,不作為負樣本處理
- 標籤定義:
- 核心特性
- 忽略高 IoU 的非最佳 anchor
- 避免高 IoU anchor 產生錯誤的負梯度
- 提升訓練穩定性與收斂效果
- 主要問題
- 仍屬於固定規則匹配
- 無法依模型預測品質動態調整正樣本
 |
|---|
| 除最佳匹配的 anchor 外,與 GT 具有高 IoU 的候選不作為負樣本(ignore),僅低 IoU 的候選被視為背景參與訓練 |
Anchor Ratio Matching(YOLOv5)
- 設計動機
- 透過尺寸先驗提供更多合理正樣本
- 降低 early training 時 IoU 匹配的不穩定性
- 設計方式
- 以 尺寸比例取代 IoU 作為匹配條件,設 GT 為 ,anchor 為 :
- 常用 threshold:
- 所有符合條件的 anchors 作為正樣本(one-to-many)
- 核心特性
- Anchor-level one-to-many
- 僅依賴幾何尺寸關係(prediction-agnostic)
- 增加監督訊號並加速收斂
- 主要問題
- 不考慮分類或定位品質
- 固定規則可能導致次優分配
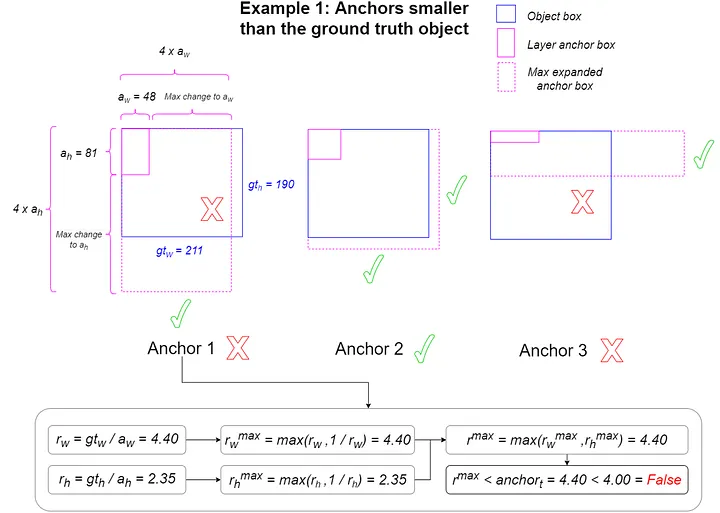 | 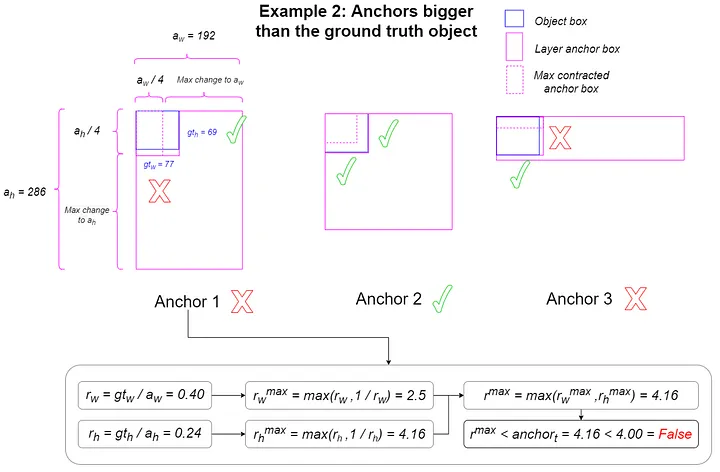 |
|---|---|
| 小尺寸 Anchor 匹配判定(檢查最大放大倍率是否 ) | 大尺寸 Anchor 匹配判定(檢查最大縮小倍率是否 ) |
Cross-grid Matching(YOLOv5)
- 設計動機
- 座標範圍擴展:中心點預測範圍由 擴展至 ,使網格具備跨界預測的能力。
- 增加正樣本:突破單一網格限制,藉由分配相鄰網格放大 one-to-many 效應,加速模型收斂。
- 設計方式
- 將 GT 中心點所在的網格,十字劃分為 四個扇區(象限)。
- 相鄰選擇策略:依據 GT 中心點落在哪個扇區,決定要擴充的網格方向。
- 若位於 左上角:額外選中 上方 與 左側 的網格。
- 若位於 右下角:額外選中 下方 與 右側 的網格(依此類推)。
- 最終分配:每個 GT 除了原本所在的中心網格,還會加上 1 到 2 個相鄰網格(通常為 3 個網格),共同參與後續的 Anchor 篩選。
- 核心特性
- Grid-level one-to-many:基於空間位置的正樣本擴充。
- 僅依賴中心點的相對位置(prediction-agnostic)。
- 將正樣本數量上限直接拉高 3 倍。
- 主要問題
- 邊界劃分生硬(在十字交界處微小的偏移就會選到完全不同的網格)。
- 仍為靜態分配,未考慮當前模型的預測品質。
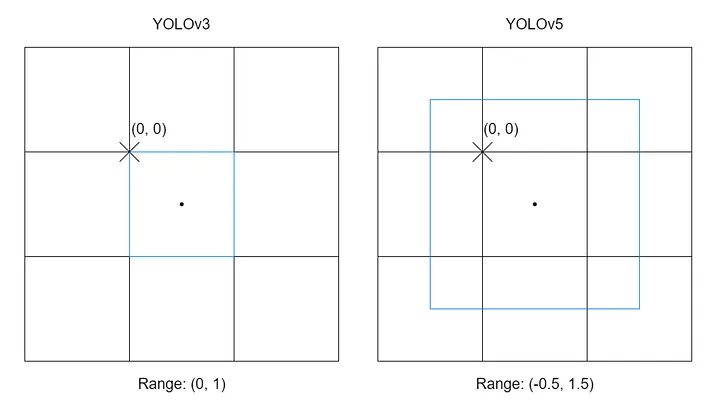 | 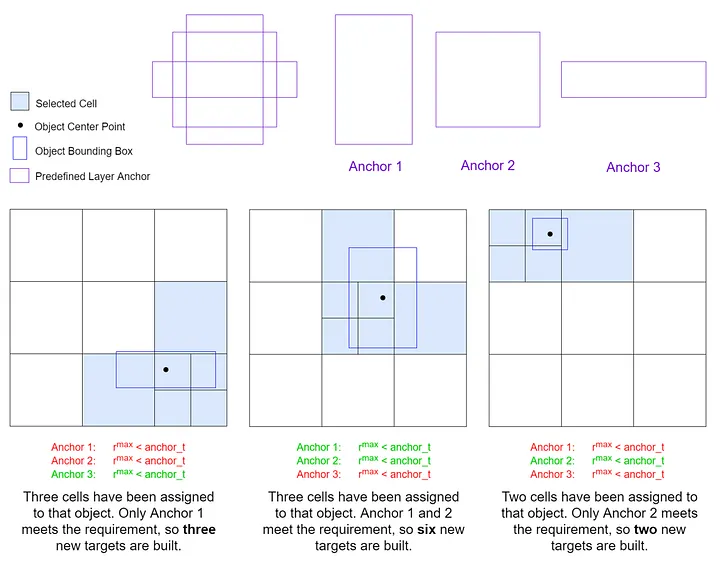 |
|---|---|
| 匹配範圍從單一網格 擴至 | 依中心偏移選相鄰網格,再以尺寸比例篩選正樣本 |
Center Prior(YOLOv5–YOLOv7)
- 設計動機
- 限制匹配範圍至 GT 中心附近
- 減少無效候選並提升訓練穩定性
- 設計方式
- 僅保留滿足下列條件的候選位置:
- 其中:
- :GT 中心
- :該層 stride
- :中心半徑(約 )
- 核心特性
- 基於位置的預篩選(prediction-agnostic)
- 顯著減少候選數量
- 常作為後續匹配(Best-IoU、SimOTA、TAL)的前置步驟
- 主要問題
- 僅依賴幾何距離,未考慮預測品質
- 半徑設定不當可能限制正樣本數量

統計驅動分配(Statistical-driven)
Adaptive Training Sample Selection
- 設計動機
- 解決固定 IoU 閾值過於僵硬的問題
- 根據每個物體的幾何分佈,自適應決定正樣本閾值
- 設計方式
- 空間預篩
- 在每個 FPN 層級中,選取距離 GT 中心最近的 個候選框
- 合併所有層級作為候選集合
- 統計分佈
- 計算候選框與 GT 的 IoU,得到均值與標準差:
- 動態閾值
- 正樣本條件
- IoU
- 且候選框中心位於 GT 內部
- 空間預篩
- 核心特性
- 統計驅動閾值(Statistical-driven)
- 為每個 GT 自動產生適當數量的正樣本
- 統一 Anchor-based 與 Anchor-free 的分配機制
- 主要問題
- 仍屬於 Prediction-agnostic
- 未利用模型當前的分類或定位品質
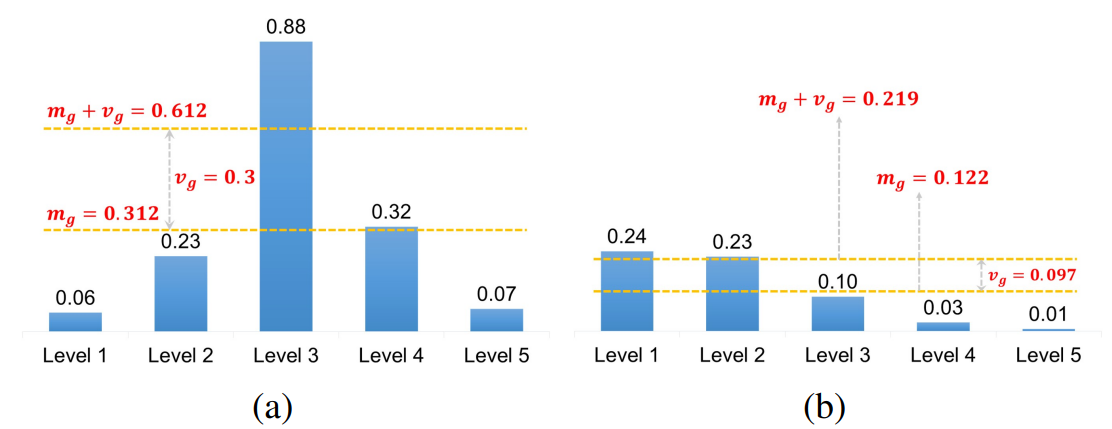
| 圖示 | IoU 分佈情況 | 動態閾值結果 | 正樣本情況 |
|---|---|---|---|
| (a) | 整體 IoU 高且集中 | 閾值變高 | 只留下少量高品質樣本 |
| (b) | 整體 IoU 低且分散 | 閾值變低 | 保留較多中等樣本 |
關鍵
ATSS 以統計學打破固定閾值,達到靜態匹配極限;但因未考慮「預測品質」,進而催生了後續的動態分配(SimOTA/TAL)。
動態分配(Dynamic Assignment)
Optimal Transport Assignment(YOLOX)
- 設計動機
- 解決固定 IoU 或固定 top-k 等規則過於僵硬的問題
- 將樣本分配由幾何或統計規則,提升為基於預測品質的全局最佳化
- 同時考慮分類與定位品質,使匹配更符合模型當前能力
- 設計方式
- 全局匹配建模
- 將 label assignment 視為 Optimal Transport(最優傳輸)問題
- 在所有候選框與 GT 之間尋找整體最小匹配成本
- 品質成本
- 包含 classification 與 IoU / regression loss
- 動態分配
- 根據最優傳輸結果,自動決定每個 GT 的正樣本數量
- 全局匹配建模
- 核心特性
- Global optimal assignment:從整體成本最小化角度進行分配,而非局部閾值或排序規則
- Prediction-aware:分配直接依賴模型當前的分類與定位品質
- Dynamic positives per GT:每個 GT 的正樣本數量由匹配結果自動決定
問題
OTA 需透過 Sinkhorn 等迭代方法 求解最優傳輸,導致 計算成本高、訓練效率較低,因此實務上常以近似方法(SimOTA)取代。
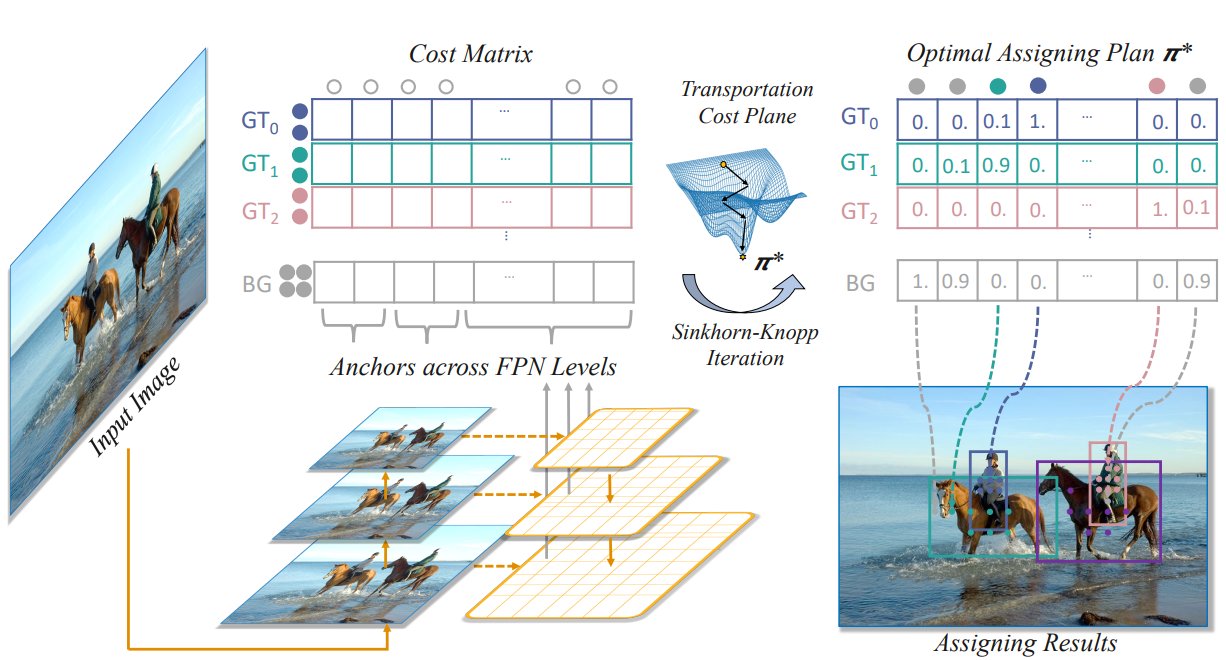
- Forward 預測
- 取得所有 anchors(跨 FPN)的分類與 bbox
- 計算 Cost Matrix
- 對每個 GT × Anchor 計算:
- 分類 cost
- 回歸 cost
- center prior cost
- 對每個 GT × Anchor 計算:
- Dynamic k 設定需求
- 每個 GT 分配 k 個正樣本(自適應決定)
- Optimal Transport 求解
- 使用 Sinkhorn 得到最優分配矩陣
- 產生最終指派
- 根據分配矩陣
- 每個 anchor 指派給 最大的 GT
- 分配值接近 0 的 anchors 設為 background
Simplified Optimal Transport Assignment(YOLOX)
- 設計動機
- OTA 將匹配建模為全局最優傳輸問題,但需透過 Sinkhorn 求解,計算成本較高
- 目標是在保留 OTA 核心優點的同時,降低訓練開銷
- Loss / Quality aware(基於分類與回歸成本匹配)
- Center prior(優先匹配中心附近樣本)
- Dynamic positives(每個 GT 的正樣本數量自適應)
- Global view(從全局角度進行樣本分配)
- 關鍵簡化
- Cost 定義
- 使用分類與回歸損失作為匹配成本
- Center prior(候選篩選)
- 僅在 GT 中心附近區域選取候選 anchors,縮小搜尋範圍
- Dynamic Top-k
- 以 IoU 品質估計每個 GT 的正樣本數量
- 在候選區域內選擇成本最低的 k 個作為正樣本
- 無需 OT 求解
- 直接對 cost 排序並選取 Top-k,取代 Sinkhorn 最優傳輸迭代
- Cost 定義
- 效果
- 顯著降低訓練時間與計算量
- 避免 OT 求解帶來的額外超參數與數值計算負擔
關鍵
SimOTA 本質是 用局部 Top-k 排序近似 OTA 的全局最優分配。
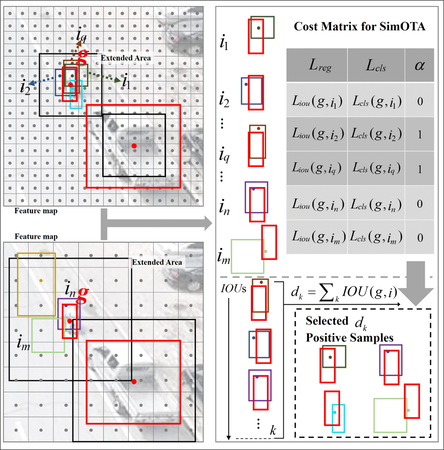 |
|---|
| 在中心區域篩選候選,依 IoU 決定 Dynamic k,選取 cost 最小的 Top-k,近似全局匹配,無需 Sinkhorn。 |
Task-Aligned Assignment(YOLOv8)
- 設計動機
- 一階段偵測的 分類分數 與 定位品質(IoU) 容易不對齊,導致「分數高但框不準」或「框準但分數低」
- 目標是用一個 task-aligned metric 同時衡量分類與定位,讓正樣本更偏向「又準又有信心」的候選點
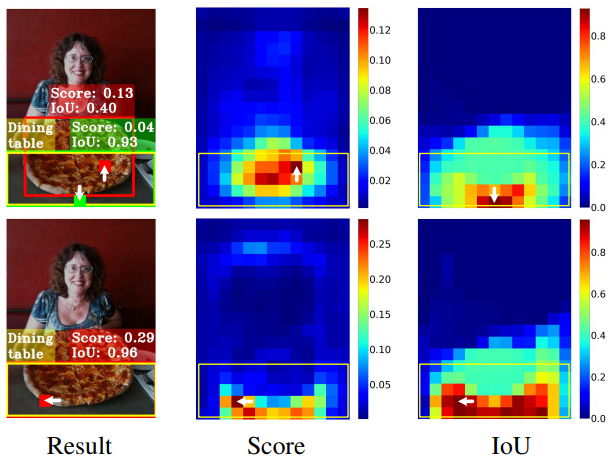
方法 分類最佳位置(紅框) 定位最佳位置(綠框) 對齊情況 最終預測效果 ATSS(上) 偏離物體中心 位於另一位置 分類與定位不一致 選到分數高但 IoU 低的框 TOOD(下) 接近物體中心 與紅框重合 分類與定位對齊 選到同時高分且高 IoU 的框
- 關鍵機制
- Task-aligned metric(對齊度量)
- 以「對應類別分數」與「IoU」加權相乘:
- 為該 GT 類別的預測分數
- 為 GT 與預測框的 IoU
- YOLOv8 預設常用
- 以「對應類別分數」與「IoU」加權相乘:
- 候選篩選(in-GT / center-based candidates)
- 先只保留 anchor point 落在 GT 框內 的候選(等同先縮小搜尋空間)
- Top-k 正樣本選擇
- 對每個 GT,依 取 Top-k 作為正樣本(預設 Top-k=10)
- 衝突處理
- 若同一個 anchor 同時被多個 GT 選中,保留 overlap/IoU更大(或對齊度量更好)的 那個 GT
- Soft target score(用對齊度量加權)
- 分配完後,會用「正樣本的對齊度量做 normalization(並結合最大 IoU)」去縮放 target scores,讓分類的 supervision 直接反映定位品質
- Task-aligned metric(對齊度量)
- 效果
- 正樣本更「任務對齊」(分類×定位一起考量),提升訓練穩定性與收斂品質
關鍵
TAL 的核心是 用 排序挑 Top-k,並用 soft target score 讓分類監督帶入定位品質。
多分支監督分配(Multi-Branch Supervision)
Coarse-to-Fine Lead Guided(YOLOv7)
- 設計動機
- 單一嚴格匹配可能導致正樣本不足,使訓練初期收斂不穩定
- 透過 多分支與不同粒度的標籤分配:
- 主分支學習精確定位
- 輔助分支提供更密集的監督訊號,加速收斂
- 雙頭分配策略
組件 監督粒度 分配策略 (Label Assignment) 目的 Lead Head Fine (細) 使用 SimOTA 嚴格篩選最優候選框 (Positive Samples)。 確保最終預測的精確定位與高品質輸出。 Aux Head Coarse (粗) 繼承 Lead 的結果並放寬約束(如加大 Center Region),納入更多候選框。 增加早期正樣本數量,強化梯度訊號,加速 Backbone 學習。 - 核心特性
- 非獨立計算 (Shared Strategy)
- Aux Head 不是重新計算,而是基於 Lead Head 的分配結果進行「擴張」,確保兩者學習目標的一致性。
- 零推論成本 (Inference-Free)
- Aux Head 僅在訓練階段存在,推論時捨棄,不影響檢測速度。
- 收斂優化
- 透過「多目標、多難度」的學習任務,顯著提升訓練穩定性。
- 非獨立計算 (Shared Strategy)
- 效果
- 提升訓練穩定性,改善 early training 收斂速度
- 在不增加推論成本下提升精度(Aux head 僅在訓練使用)
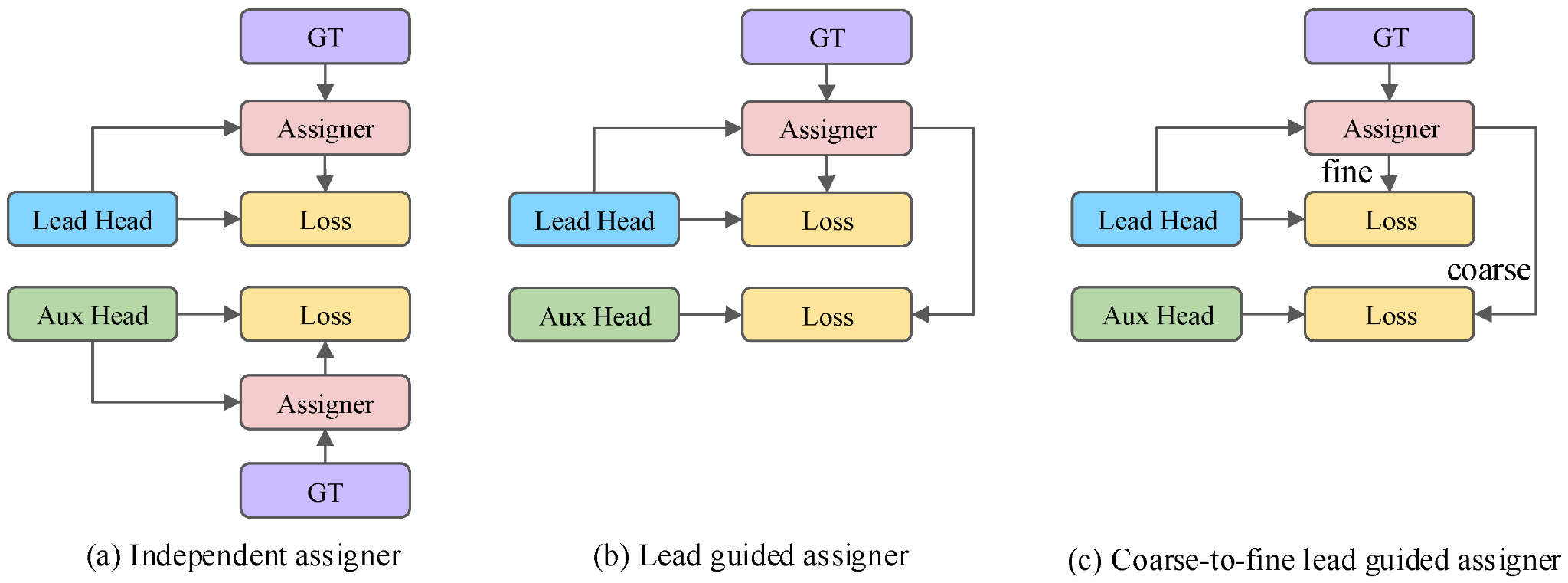
| 方法 | Assign 計算方式 | Lead / Aux 關係 | 監督粒度 | 特點 |
|---|---|---|---|---|
| (a) Independent assigner | Lead 與 Aux 各自獨立計算 assignment | 完全獨立 | 相同 | 計算量較大,兩分支學習目標可能不一致 |
| (b) Lead guided assigner | 僅由 Lead 計算 assignment,Aux 直接共享結果 | 共享相同標籤 | 相同 | 降低計算量,確保兩分支學習一致 |
| (c) Coarse-to-Fine lead guided | 由 Lead 計算 assignment,Aux 在此基礎上放寬匹配條件 | 共享但擴展 | Lead:Fine / Aux:Coarse | 增加正樣本數量,提升 early training 穩定性與收斂速度 |
關鍵
透過 Aux 放寬匹配條件,增加正樣本數量,提升 early training 的收斂穩定性。
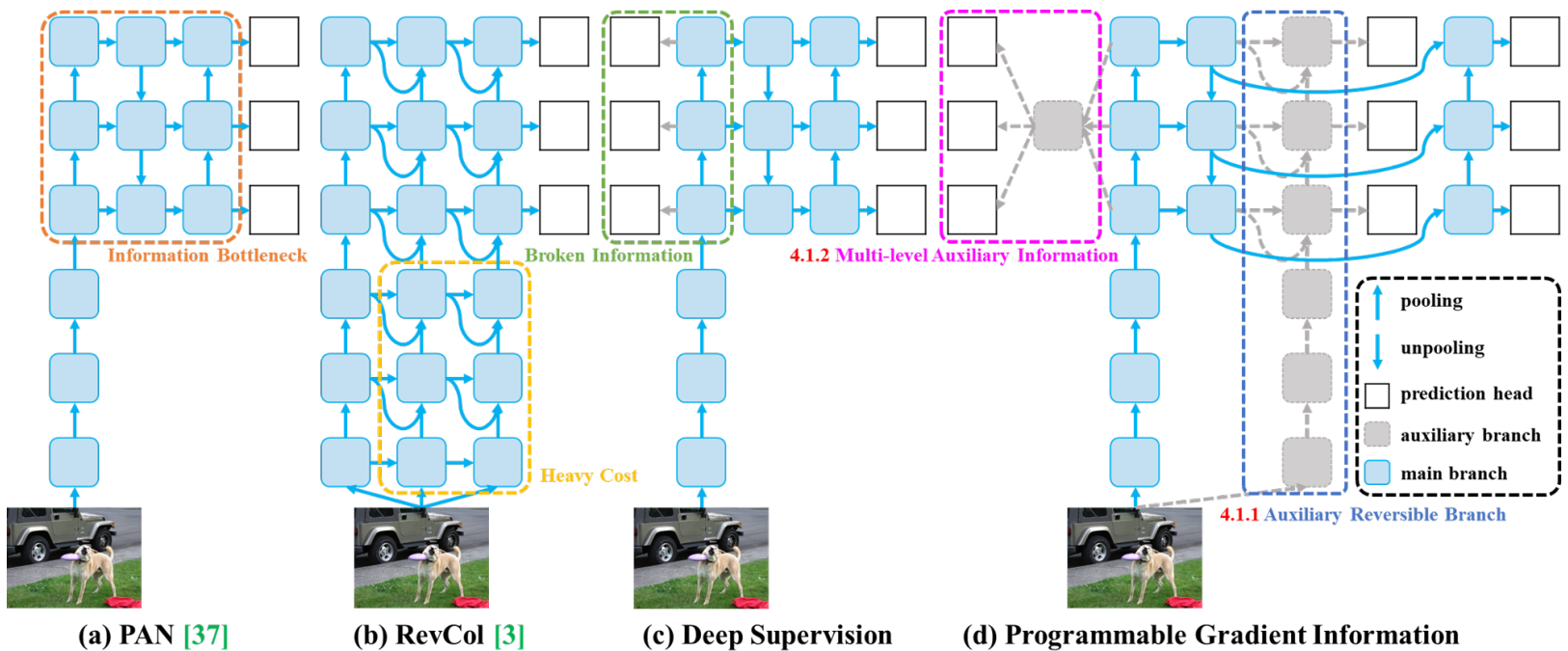
Dual Label Assignment(YOLOv9)
- 設計動機
- 極深網路中容易出現 資訊與梯度衰減
- 配合 PGI(Programmable Gradient Information),透過多路徑監督補充有效梯度,提升訓練穩定性
- 雙分支分配策略
組件 監督角色 分配策略 (Label Assignment) 目的 Main Branch Primary 使用 TAL(Task-Aligned Assignment) 選取 Top-k 正樣本。 作為最終輸出,學習高品質任務對齊特徵。 Aux Branch Gradient Support 使用相同的 TAL,形成額外 supervision。 提供輔助梯度,強化早期與中間層特徵學習。 - 核心特性
- 一致分配 (Consistent Assignment)
- Main 與 Aux 使用相同的 TAL,確保學習目標一致
- 梯度路徑優化 (PGI)
- 透過雙分支 loss 提供多路徑梯度回傳,減少資訊與梯度衰減
- 零推論成本 (Inference-Free)
- Aux Branch 僅於訓練使用,推論時移除
- 一致分配 (Consistent Assignment)
- 效果
- 提升深層模型的訓練穩定性與收斂效率
- 在不增加推論成本下提升檢測性能
關鍵
核心是透過雙分支提供 多路徑梯度(PGI),改善深層網路的訓練穩定性。
端到端匹配(End-to-End)
Consistent Dual Assignments(YOLOv10)
- 設計動機
- 傳統檢測依賴 NMS 去除重複框,增加推論延遲並影響端到端性
- 若同一物體對應多個預測,即使模型準確仍會產生重複檢測
- 目標是在訓練中學習 唯一匹配關係,實現 NMS-free 推論
- Consistent Dual Assignments
- 訓練階段同時使用兩種匹配策略:
分配方式 角色 目的 One-to-Many Optimization 為每個 GT 提供�多個正樣本,加速收斂並提升訓練穩定性 One-to-One Inference-aligned 為每個 GT 僅匹配唯一最佳預測,學習一對一對應關係 - 兩種分配在同一模型中 共同訓練(consistent training)。
- 訓練階段同時使用兩種匹配策略:
- 推論階段
- 僅保留 one-to-one head
- 每個物體對應唯一預測
- 直接輸出結果,無需 NMS
- 核心特性
- End-to-End Detection
- 訓練與推論目標一致,避免後處理依賴
- Consistent Optimization
- One-to-many 提供充分監督
- One-to-one 對齊推論需求
- NMS-Free
- 降低延遲並簡化推論流程
- End-to-End Detection
- 效果
- 在保持精度的同時提升推論速度
- 減少後處理帶來的不穩定性
- 適用於即時與端到端部署場景
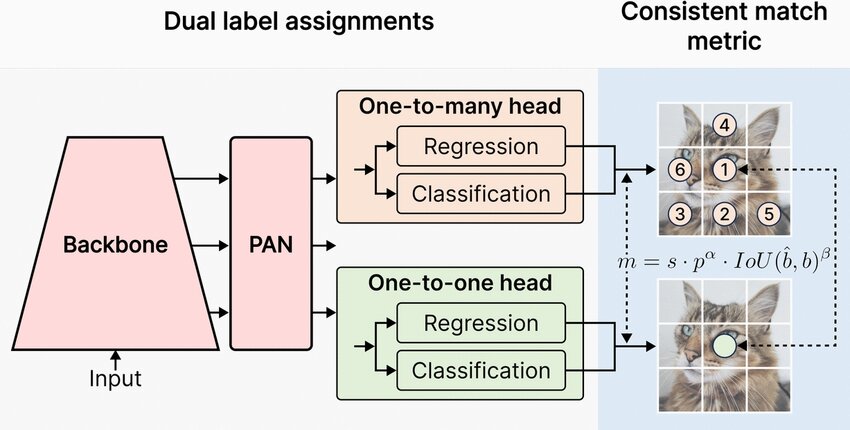
關鍵
NMS-free 的本質 = 在訓練中學會唯一匹配