YOLO Detection Head 的演進
YOLO 的 head 演進,並不是單純「換個輸出形式」,而是一條降低任務衝突、移除 heuristic、走向 end-to-end 推論的設計路線
後處理路線:從先驗到更乾淨的推論流程
Direct Prediction(YOLOv1)
- 設計特徵
- 以 grid cell 為單位直接預測 bbox 與類別機率
- 每個 cell 只負責其中心落在該區域內的物體
- 不依賴預先定義的尺寸或比例先驗
- 設計優點
- 輸出形式簡單,推論流程直接
- 計算量低,符合早期 real-time 偵測需求
- 核心限制
- 同一 cell 可預測的物體數量有限,密集場景容易漏檢
- 對尺度變化不敏感,小物體與極端比例物體回歸困難
- bbox 完全從零學習,訓練穩定性較差
問題
Direct prediction 的問題本質是缺乏形狀與尺度先驗,讓回歸難度過高。
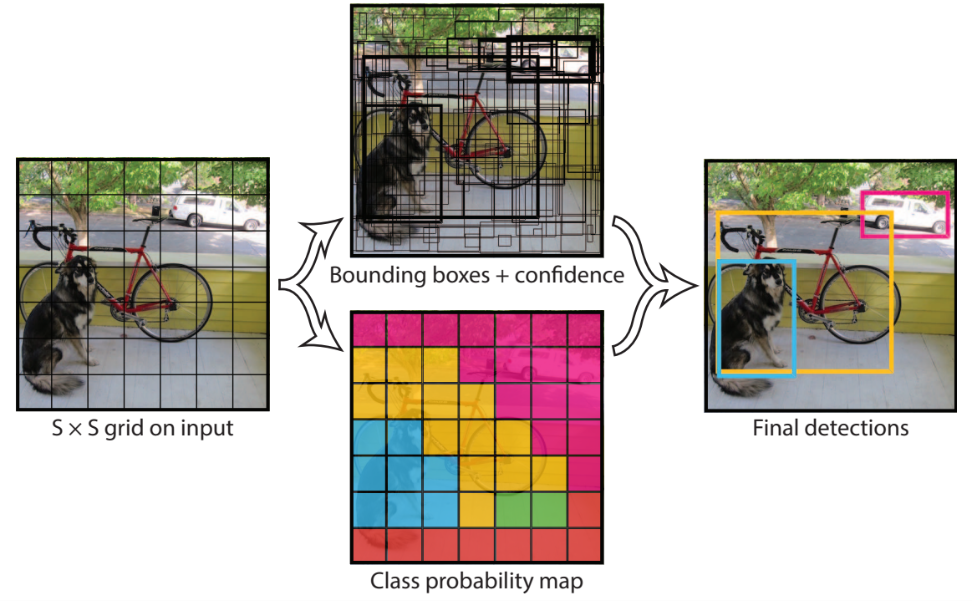
計算流程
- Grid 分區(左圖)
- 將影像劃分為 S × S cells
- 每個 cell 負責其中心落在該區域內的物體
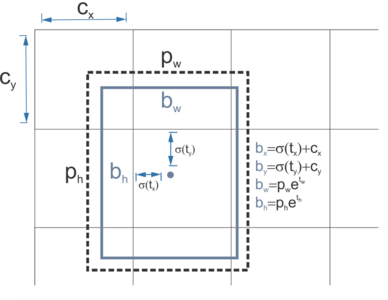
- Bounding box 預測(中上)
- 每個 cell 輸出:
- B 個 bounding boxes(x, y, w, h)
- 每個 box 的 confidence(是否包含物體 × IoU)
- 每個 cell 輸出:
- 類別機率預測(中下)
- 每個 cell 同時預測:
- 一組 class probabilities
- 表示該 cell 內物體屬於各類別的機率分佈
- 每個 cell 同時預測:
- 分數融合與篩選(右圖)
- 最終分數 = confidence × class probability
- 移除低分框,並使用 NMS 得到最終偵測結果
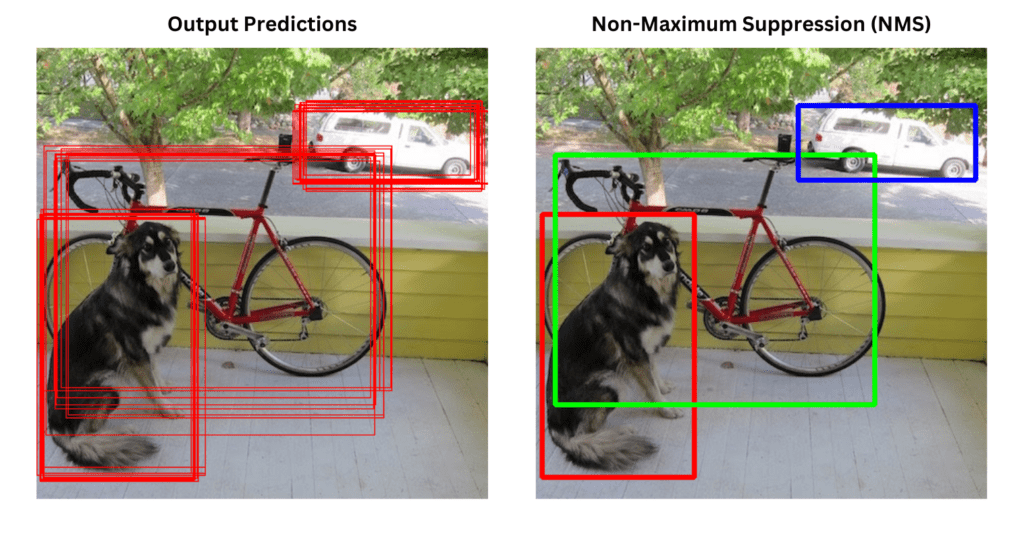
NMS(Non-Maximum Suppression)
- 設計目的
- Dense prediction 會產生大量重疊 bounding boxes
- 同一物體可能被多個位置或 anchor 重複預測
- 需要保留最可靠的結果,移除冗餘框
- 核心機制
- 過濾低分框
- 移除 confidence 低於閾值的候選框(如 0.25)
- 分數排序
- 依照 confidence score 由高到低排序
- 逐一抑制重疊框
- 取目前最高分框作為保留框
- 計算其與其他框的 IoU
- 移除 IoU 大於閾值的框(如 IoU > 0.5)
- 重複處理
- 對剩餘框重複步驟 3
- 直到沒有候選框為止
- 過濾低分框
- 設計影響
- 有效降低重複預測,提高結果品質
- 但屬於後處理步驟(non-differentiable)
- 增加推論延遲與部署複雜度,成為後續 NMS-free / End-to-End 設計的優化目標
Anchor-based(YOLOv2-v5、YOLOv7)
- 設計動機
- bbox 直接回歸難度高,特別是寬高變化大時收斂不穩定
- anchors 提供 尺寸與比例先驗,模型只需學習 offset
- 結合 anchors + multi-scale head 提升小物體與大物體的偵測能力
- 核心機制
- 每個 feature map 位置對應 多個 anchors
- 模型預測:
- box offset(相對於 anchor)
- objectness score
- class probabilities
- 訓練時:依 IoU matching 將 GT 分配給對應 anchor
- 推論時:使用 confidence threshold + NMS 篩選結果
- 代價
- anchor 尺寸與比例需要設計或透過 clustering 設定
- 正負樣本嚴重不平衡(大量 anchors 為負樣本)
- 需要設定多項閾值(IoU、confidence、NMS)
- 對資料分佈敏感,不同任務常需要重新調整
關鍵
Anchor-based 的本質是「用形狀先驗換訓練穩定」。
問題
Anchor-based 需要設計 anchor、匹配策略與多項閾值,且產生大量冗餘預測並依賴 NMS,導致 pipeline 複雜且對資料分佈敏感。
各個版本的優化
- YOLOv2:引入 Anchor-based
- 使用 anchor boxes,改為預測相對於 anchor 的 box offset
- 透過 k-means 產生符合資料分佈的尺寸
- 引入 Sigmoid 函數限制中心點,確保中心點落在網格內
- YOLOv3:建立多尺度 Anchor 預測
- 在 3 個尺度進行偵測(multi-scale head)
- 不同尺度對應不同大小的 anchors
- YOLOv4:改進訓練與匹配策略
- 引入 CIoU / DIoU loss,提升 anchor 回歸品質
- 消除網格敏感度,使邊界中心點更容易預測
- 引入跨網格匹配,增加正樣本數量
- YOLOv5:自動化 Anchor 設計
- 提供 AutoAnchor 機制
- 自動檢查 anchor 是否適合資料分佈
- 必要時重新以 k-means + 遺傳演算法優化
- 從「人工設計」走向「資料驅動」
- 提供 AutoAnchor 機制
- YOLOv7:優化正樣本分配(Dynamic Assignment)
- 採用 SimOTA / dynamic label assignment
- 讓正樣本數量依據預測品質動態調整
- 引入 Coarse-to-fine 的引導式分配,結合輔助頭提升分配穩定性
 |
|---|
| YOLOv3:建立多尺度 Anchor 預測 |
 |  |
|---|---|
| YOLOv2:引入 Anchor-based 與限制中心點 | YOLOv4:引入 CIoU loss 與跨網格匹配 |
 |  |
|---|---|
| YOLOv5:自動化 Anchor 設計 | YOLOv7:引導式動態標籤分配 |
計算流程
- Anchor 生成(Anchor Generation)
- 在影像或 feature map 上以固定 stride 產生 密集錨點
- 每個錨點生成多個 anchors:
- 多個 尺度(scale)
- 多個 長寬比(aspect ratio)
- 每個位置通常對應 k 個 anchors(如 3~9 個)
- 目標是用先驗框覆蓋各種尺寸與形狀的物體



密集錨點生成 錨點與目標匹配 多尺度與長寬比先驗
- 目標是用先驗框覆蓋各種尺寸與形狀的物體
- Anchor Matching(正負樣本分配)
- 計算每個 anchor 與 GT 的 IoU
- 分配規則:
- IoU 高於閾值 → 正樣本
- IoU 低於閾值 → 負樣本
- 或選擇與 GT IoU 最大的 anchor
- 決定每個 anchor 的學習目標(位置與類別)
- 模型預測(Regression + Classification)
- 對每個 anchor 預測:
- bbox offset(相對於 anchor 的位移與尺度)
- objectness
- class probabilities
- 實際預測框 = anchor + offset
- 對每個 anchor 預測:
- 結果篩選(Inference)
- 將預測框轉回影像座標
- 移除低分框(confidence threshold)
- 使用 NMS 去除重疊框,取得最終結果
Anchor-free(YOLOv6、YOLOv8)
- 核心想法
- 移除預先定義的 anchor boxes
- 每個位置直接預測物體位置,不依賴尺寸與比例先驗
- 通常以 point-based 表示
- 預測到四邊界的距離(l, t, r, b)
- 或直接回歸 bbox
- 設計動機
- Anchor-based 需要設計尺寸、比例與匹配策略,工程複雜
- 大量 anchors 造成正負樣本不平衡與計算負擔
- 希望降低手工先驗,使模型更通用、更易部署
- 核心機制
- 每個 feature map 位置視為一個候選點
- 模型預測:
- bbox(或邊界距離)
- objectness / center score
- class probabilities
- 訓練時:
- 依據 中心區域或距離規則分配正樣本(不再使用 anchor matching)
- 推論時:
- 使用 confidence threshold
- 搭配 NMS 篩選結果
- 限制
- 預測位置完全由模型學習,對正樣本分配策略較敏感
- Dense prediction 仍會產生大量重疊框,推論階段仍需 NMS
 |  |
|---|---|
| YOLOv6 Reg 分支直接預測特徵點到目標邊界的距離 | YOLOv8 移除 Objectness 分支,以 TAL 動態匹配取代傳統的 IoU |
關鍵
Anchor-free 並非單純「拿掉 anchors」,其核心改變在於:正樣本定義與回歸方式的重新設計。
問題
即使 anchor-free,很多 YOLO 系列仍會依賴 NMS 做後處理,所以「anchor-free ≠ end-to-end」,只是把「anchors 這個先驗」先移除。
FCOS(Fully Convolutional One-Stage)
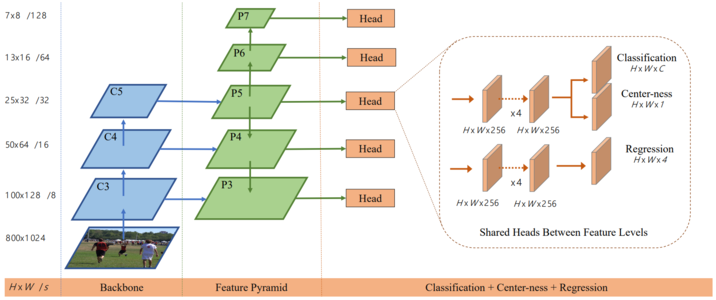
Point-based 正樣本定義
- 每個 feature map 位置視為一個候選點
- 若該點落在某個 GT box 內,則可成為正樣本
- 不再進行:
- anchor matching
- IoU-based anchor assignment
- 關鍵差異
- Anchor-based:先選 anchor,再學 offset
- Anchor-free:直接由位置決定是否學習該物體
邊界距離回歸
- FCOS 使用距離形式表示 bounding box:
- 預測:
- 到 bounding box 四邊的距離
- 實際框由:
- 優點
- 無需 anchor 尺寸先驗
- 回歸空間更穩定(始終為正值)
- 預測:

Centerness
- FCOS 引入 centerness:
- 衡量該位置距離物體中心的程度
- 中心位置 → 高分
- 邊緣位置 → 低分
- 推論分數:
- 目的
- 抑制邊界位置產生的大量低品質框
- 降低 NMS 負擔
Loss Function
- FCOS 總損失為:
- :Focal Loss
- :IoU Loss
- :正樣本數量
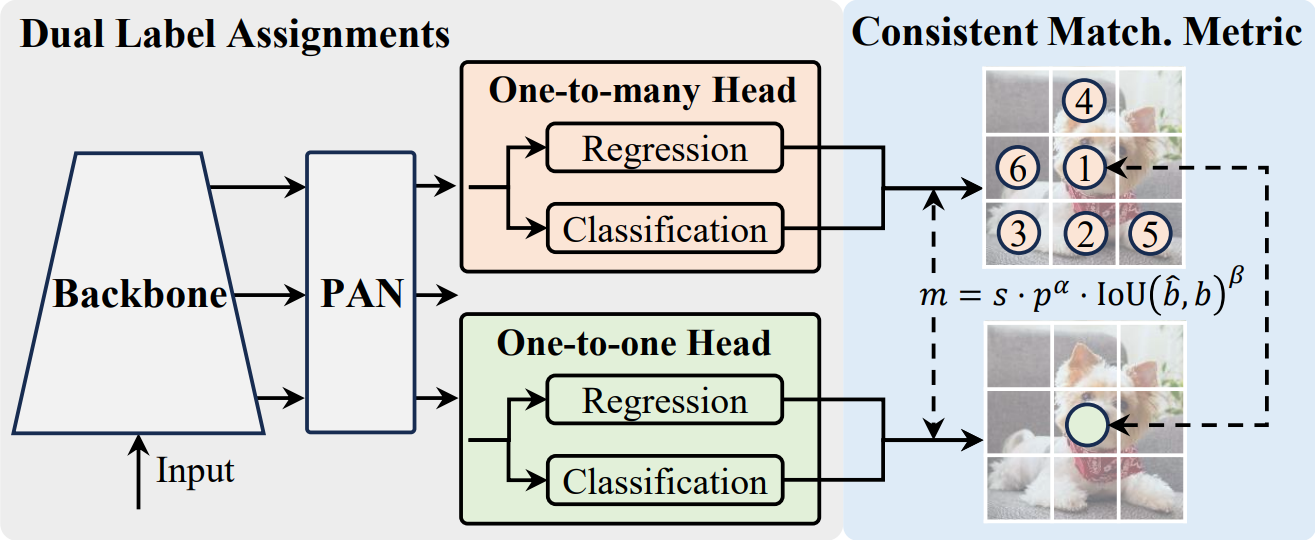
NMS-free / End-to-End(YOLOv10)
- 設計動機
- 傳統 YOLO 依賴 NMS 作為後處理,會帶來:
- 額外推論延遲
- 無法真正端到端訓練
- 部署流程複雜
- Dense prediction 產生大量重疊框,使 NMS 成為效能瓶頸
- 傳統 YOLO 依賴 NMS 作為後處理,會帶來:
- 核心想法
- 讓模型直接輸出少量且高品質的預測
- 將「去重與選擇」能力,從後處理(NMS)移到 label assignment + 訓練機制
- 目標:推論時不再需要 NMS
- 關鍵機制:Consistent Dual Assignments
- 訓練階段使用雙重分配策略
- One-to-many assignment
- 每個 GT 對應多個正樣本
- 提升訓練穩定性與收斂速度
- One-to-one assignment
- 每個 GT 僅對應一個預測
- 學習「唯一匹配」
- One-to-many assignment
- 推論階段使用 one-to-one head
- 每個物體只輸出一個主要預測,大幅減少重疊框
- 直接輸出最終結果(無需 NMS)
- 訓練階段使用雙重分配策略
關鍵
Anchor-free 是「移除形狀先驗」,NMS-free / End-to-End 是「移除後處理依賴」,通常需要 head/assignment 更強的結構性設計,才能把 NMS 的工作「學進模型裡」。
後處理路線:降低任務衝突
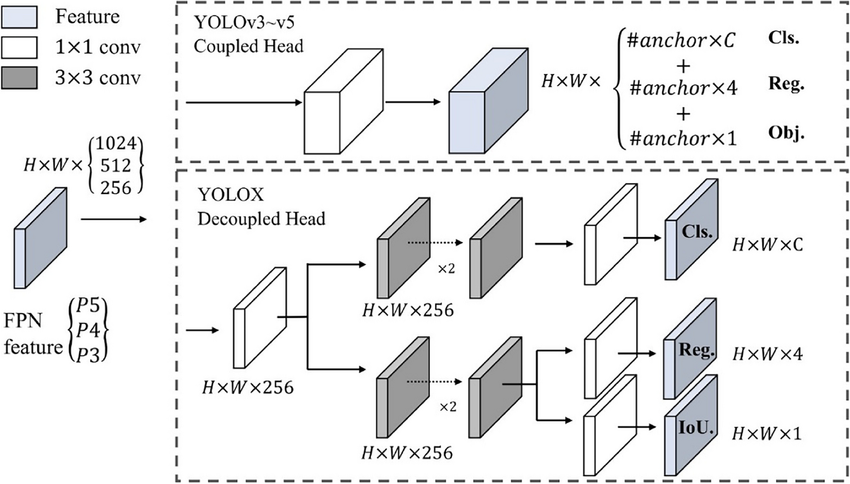
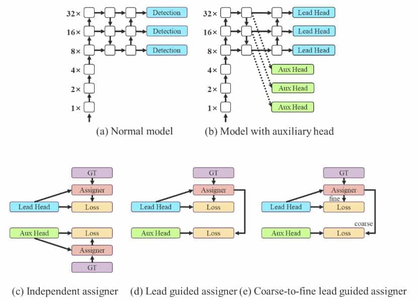
Coupled Head(YOLOv1–YOLOv5)
- 設計特徵
- Classification / Objectness / Box regression 共享同一特徵分支
- 常見形式:
- 同一卷積輸出
(cls + obj + box) - 或僅最後一層分開,其餘高度共享
- 同一卷積輸出
- 優點:結構簡單、計算量低、推論快
- 主要問題
- Task conflict
- Classification:需要語意與類別可分性
- Regression:需要空間定位與邊界精度
- 共享特徵會導致:
- 梯度互相干擾
- 收斂變慢
- 精度上限受限(在強 backbone/neck 下更明顯)
- Task conflict
- 適用背景
- 早期 YOLO 以 real-time 與輕量化為優先
- 任務衝突問題在小模型中不明顯
問題
當 backbone / neck 持續變強時,共享 head 會造成分類與定位的梯度目標不一致,導致收斂不穩與精度上限受限。
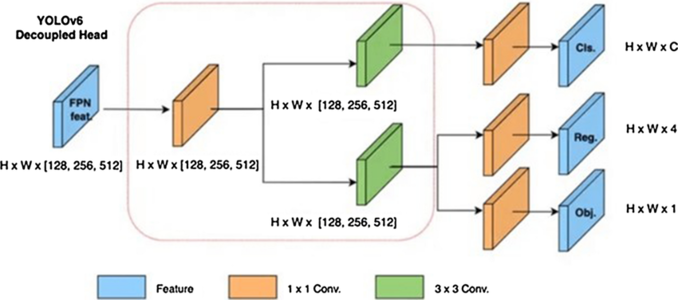
Decoupled Head(YOLOv6-YOLOv11)
關鍵概念來自 FCOS / RetinaNet / YOLOX
- 設計特徵
- Head 分為兩條獨立分支:
- Classification branch
- Regression branch(通常含 objectness)
- Head 分為兩條獨立分支:
- 設計動機
- 降低 classification 與 localization 的梯度干擾
- 讓兩個任務學習不同的特徵空間
- 提升訓練穩定性與最終精度
- 效果
- 收斂更快
- AP 提升(YOLOX、YOLOv6 均有實驗證明)
- 已成為現代 one-stage detector 的標準設計
關鍵
Coupled → Decoupled 的主軸是把「分類 vs 定位」的衝突從結構上拆開。