YOLO Loss 演進
L1 / L2 Loss(YOLOv1-YOLOv3)
- 設計方式
- 對預測與真值直接做數值誤差最小化
- 位置:
- 尺寸:
- 置信度與分類也使用平方誤差
- YOLOv1 使用 Sum of Squared Error(L2 Loss) 作為整體 loss
- 對預測與真值直接做數值誤差最小化
- 設計動機
- 將 detection 視為 回歸問題
- 結構簡單、易於實作與訓練
- 計算成本低,符合 early real-time 設計目標
- 核心特性
- 直接最��小化座標距離:
- 與影像尺度直接相關(非尺度不變)
- 主要問題
- 與評估指標不一致
- 訓練優化座標距離,評估使用 IoU
- 尺度敏感
- 大框與小框相同誤差影響不同
- 幾何關係未建模
- 相同的座標距離誤差,可能對應截然不同的重疊狀態(與 IoU 脫鉤)。
- 易受異常值主導
- L2 對極端偏離的預測過度敏感,容易拉偏整體訓練方向。
- 高 IoU 區域梯度不足
- 難以進行精細定位 → 影響 AP75 / AP90
- 與評估指標不一致
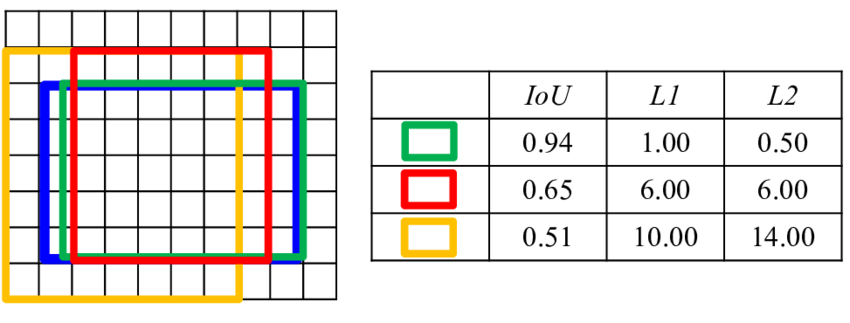 |
|---|
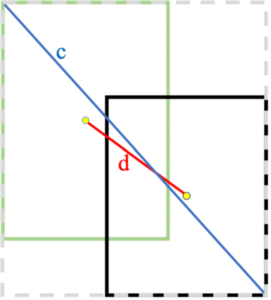
| L2 在近端(綠框)穩定,但易受異常值(黃框)主導 Loss,且距離無法反映真實 IoU。 |
問題
L1/L2 只優化座標差距,無法反映邊界重疊品質,導致訓練目標與 IoU 評估不一致。
YOLOv1:統一的 L2 Loss
- Loss 類型
- 全部任務使用 Sum of Squared Error(L2)
- 包含:
- Bounding box(x, y, w, h)
- Confidence
- Classification
- Loss 結構
- 設計特性
- :強化定位學習
- :降低負樣本影響
- 使用 :降低大框權重
- 每個 GT 由 IoU 最大的 predictor 負責
- 主要問題
- L2 與 IoU 評估指標不一致
- 對尺度敏感
- 高 IoU 區域梯度不足

問題
L2 只優化座標差距,無法反映邊界重疊品質。
YOLOv2:Anchor-based + 穩定化回歸
- Loss 類型
- Bounding box:仍為 座標回歸誤差(L2)
- Objectness:
- Classification:conditional class probability
- YOLOv2 沒有更換 loss 類型,改進重點在於:讓回歸更容易學、讓訓練更穩定
- 關鍵改變
- 引入 Anchor boxes(尺寸先驗)
- 預測 offset 而非絕對座標
- 使用 IoU-based k-means 產生 anchor priors
- 設計意義
- 降低回歸難度:模型��只需學習 residual
- 提升訓練穩定性:Sigmoid 限制中心點在 cell 內
- 改善收斂速度:dimension prior 讓初始預測更接近 GT
關鍵
YOLOv2 的進步在於「回歸表示方式」,而不是更換 Loss。
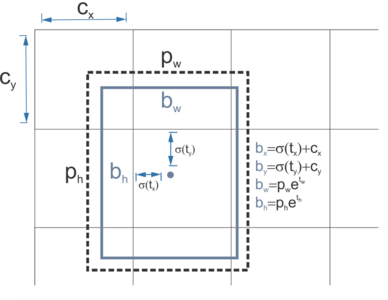
Anchor-based offset prediction
- 不直接預測 bbox 座標,而是預測相對於 anchor 的 offset
- :grid cell 位置
- :anchor 尺寸先驗
- 效果
- 將問題轉為 residual learning
- 降低回歸難度,提升學習效率
中心點 Logistic 約束(訓練穩定關鍵)
- 使用 sigmoid 限制中心位置:
- 設計目的
- 防止預測框中心在 early training 大幅漂移
- 明顯提升訓練初期穩定性
- 加速收斂
Dimension Priors(k-means anchors)
- 使用 IoU-based k-means 從資料中學習 anchor 尺寸
- 設計目的
- 提供更符合資料分佈的尺寸先驗
- 讓初始預測更接近 GT
- 提升 recall 與收斂速度
YOLOv3:BCE + IoU-aware Objectness
- Loss 類型
- bbox:座標回歸(L2)
- objectness:Binary Cross Entropy
- target(label)主要是 0/1 的 objectness
- 並且有 ignore 機制:IoU 高但不是最佳匹配的 prediction 會被忽略、不算負樣本 loss
- classification:改為 Binary Cross Entropy(multi-label)
- 關鍵改變
- 分類改為 Multi-label BCE
- 取代 Softmax,支援多標籤預測
- Objectness 與分類解耦
- 分開判斷「是否有物體」與「屬於哪一類」
- IoU-based Ignore 機制
- 與 GT IoU 高但非最佳匹配的 prediction 不計入負樣本
- 分類改為 Multi-label BCE
- 設計意義
- 分離 objectness 與 classification
- 降低類別不平衡影響
- Multi-label BCE
- 提升在複雜標註場景的適應性
- Ignore IoU threshold
- 穩定訓練、避免過多負樣本懲罰
- 評分更接近定位品質
- 高 IoU 的 anchor 才成為正樣本
- 分離 objectness 與 classification
關鍵
YOLOv3 開始讓評分與 IoU 對齊,但 bbox regression 本身仍不是 IoU-based。
Bounding box(仍為座標回歸)
- 預測參數化形式:
- 回歸損失(L2):
- 特點:仍非 IoU-based regression
Objectness(重要改變)
- 使用 Binary Cross Entropy
- 標籤定義:
- 其中 為 IoU threshold(e.g., )
- 設計重點
- 每個 GT 在每個尺度只匹配 一個最佳 anchor
- 高 IoU 但非最佳者 不計算 loss
- 降低負樣本數量,提升訓練穩定性
Classification(重要改變)
- 使用 Binary Cross Entropy(multi-label)
- 特點
- 不使用 Softmax
- 每個類別獨立預測
- 支援多標籤情境
IoU-based Loss(YOLOv4 之後主流)
為什麼 L1 / L2 不適合 Detection?
- 優化目標與任務不一致
- L1 / L2:最小化座標誤差
- Detection:最大化 IoU(重疊程度)
- 最小座標誤差 ≠ 最大 IoU
- 對尺度敏感
- 相同座標偏移:
- 小物體 → IoU 下降明顯
- 大物體 → IoU 變化較小
- 學習穩定性較差
- 相同座標偏移:
- 無法直接優化重疊品質
- 當兩框不重疊時:
- L1 / L2 仍只反映數值距離
- 無法指導如何增加重疊
- 缺乏幾何關係建模
- 無法反映:
- 框的重疊品質
- 中心距離
- 長寬比例差異
- 無法反映:
IoU-based Loss 的設計動機
- 核心思想
- 讓 Bounding Box Regression 直接優化 IoU
- 優點
- 優化目標與評估指標一致
- 對不同尺度更穩定
- 收斂更符合 detection 任務
- 定位精度更高
- 常見形式
- IoU Loss
- GIoU(Generalized IoU)
- DIoU(Distance IoU)
- CIoU(Complete IoU)
關鍵
Loss 從「座標距離」轉向「幾何關係」。
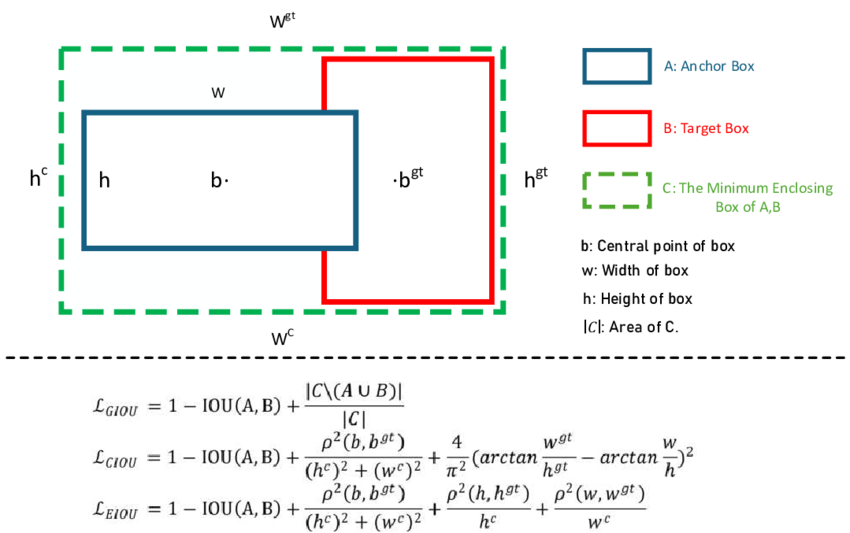
IoU Loss(基本形式)
- 定義:
- 其中:
- 特性
- 與評估指標一致
- 對尺度不敏感
- 直接優化重疊品質
- 限制
- 當兩框不重疊時:
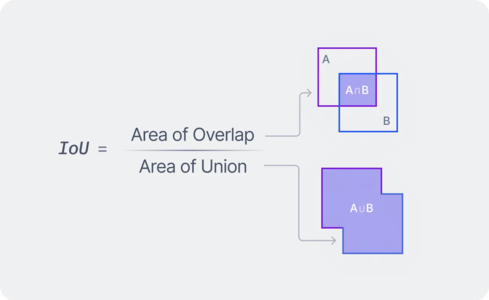
問題
無重疊時梯度為 0,模型無法學習如何靠近 GT。
GIoU(Generalized IoU)
- 為解決「無重疊無梯度」問題:
- 其中:
- :包住兩框的最小外接矩形
- 效果
- 無重疊時仍有梯度
- 推動預測框向 GT 靠近
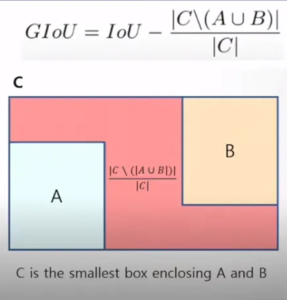
問題
僅利用外接框約束,收斂速度較慢,對中心對齊不敏感。
DIoU(Distance IoU)
- 進一步考慮中心距離:
- 其中:
- :兩框中心距離
- :外接框對角線長度
- 效果
- 加速收斂
- 更快對齊中心位置
問題
未考慮長寬比例差異,形狀對齊能力有限。
CIoU(Complete IoU,YOLOv4-v11)
- 在 DIoU 基礎上加入長寬比一致性:
- 其中:
- CIoU 同時優化
- 重疊程度(IoU)
- 中心距離(DIoU)
- 長寬比例一致性
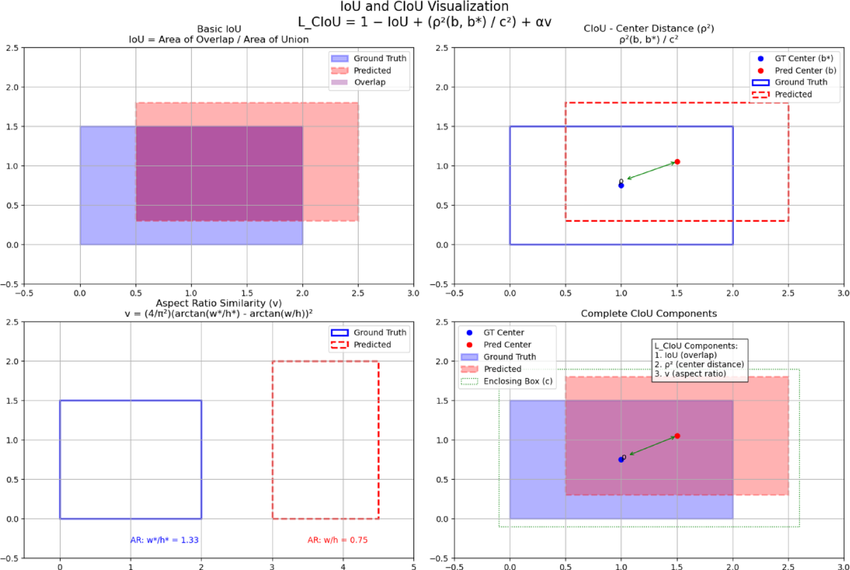
關鍵
同時對齊位置與形狀,定位精度與穩定性最佳。
EIoU(Efficient IoU,YOLOv7)
- 為改善 CIoU 中長寬比項(aspect ratio)收斂較慢的問題,EIoU 將尺寸誤差直接分離為 寬/高 的回歸項:
- 其中:
- :預測框與 GT 框的中心距離
- :包住兩框的最小外接框對角線長度
- :最小外接框的寬與高
- 效果
- 將尺寸誤差()解耦為獨立監督
- 寬高收斂更快、訓練更穩定
- 對尺寸不匹配的情況提供更直接的梯度訊號
關鍵
EIoU 以寬/高解耦的方式提供更直接的尺寸梯度,通常比 CIoU 更快完成尺度對齊。
SIoU(Shape-aware IoU,YOLOv7)
- SIoU 將回歸誤差分解為:
- IoU cost
- Distance cost
- Shape cost
- Angle cost(核心)
- 最終形式:
- 幾何量定義
- 預測框:中心點 ,寬高為
- 真實框:中心點 ,寬高為
- 兩中心點的水平/垂直距離(圖中綠色虛線框的寬與高):
- 中心距離(圖中的 ):
- 方向角(圖中的 ):
- 包住兩框的最小外接矩形(圖中黑色虛線框的寬與高):
- Angle cost(角度成本)
- 當偏移接近水平/垂直( 或 )
- 當偏移接近對角()
- Distance cost(距離成本)
- 角度成本在此轉化為距離權重 :
- 距離懲罰項(直接使用圖中的 與外接框 計算):
- Shape cost(形狀成本)
- 直接對應雙方的寬高 :
- 設計意義
- 角度成本()引導預測框優先沿最近的 X 或 Y 軸對齊。
- 距離成本以外接框尺度()正規化,避免尺度敏感,並以角度決定懲罰力度(角度越平齊,距離懲罰越強)。
- 形狀成本直接約束寬高對齊,提升收斂速度與穩定性。
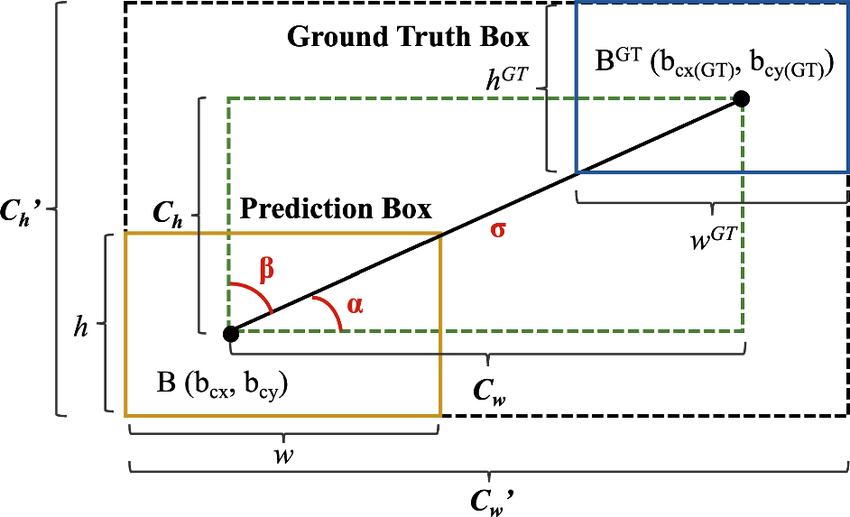
關鍵
SIoU 引入「角度」作為動態權重,核心策略是「先對齊 X/Y 軸,再拉近距離」。這種路徑規劃能減少訓練初期的盲目震盪,大幅加快收斂速度。
Multi-scale Loss Re-weighting(YOLOv5)
- 設計動機
- 不同 detection layer(P3 / P4 / P5)對應不同尺度物體,其樣本數量與學習難度存在差異
- 若某一尺度的 loss 長期較大,該層將主導梯度更新,導致多尺度學習失衡
- YOLOv5 引入 auto-balance,在訓練過程中動態調整各層權重,使不同尺度的梯度貢獻更為均衡
- 核心機制
- 對各層的 objectness loss 進行加權:
- 訓練過程中,根據各層的學習情況,以 指數移動平均(EMA) 方式更新權重: 其中 為較小的更新係數(如 )
- 設計效果
- loss 較大的尺度 → 權重逐漸降低
- loss 較小的尺度 → 權重逐漸提升
- 使不同尺度的梯度影響趨於平衡,避免單一尺度主導訓練
關鍵
Auto-balance 透過動態權重調整,使多尺度的梯度貢獻保持平衡,提升訓練穩定性與整體檢測性能。
Distribution-based Regression(YOLOv8)
- 設計動機
- 傳統回歸等同於學習單點(Dirac delta),監督訊號有限
- 將座標回歸轉為 分佈學習
- 提供更密集且平滑的學習訊號,提升定位精度與穩定性
- 設計方式
- 不直接回歸單一座標值
- 將每個邊界距離表示為離散機率分佈:
- 左、上、右、下:
- 每個邊界預測 K 個 bins 的機率(通常 K=16)
- 使用期望值計算最終位置:
- 訓練時使用 Distribution Focal Loss(DFL)
- 核心特性
- Bounding Box Regression:
- 單點回歸 → 分佈建模
- 鄰近 bins 共同提供梯度,優化更平滑
- 與 IoU-based Loss(如 CIoU)搭配:
- Bounding Box Regression:
- 主要優勢
- 提升高精度定位能力(改善 AP75 / AP90)
- 對小物體與邊界更敏感
- 學習訊號更密集,對噪聲更具魯棒性
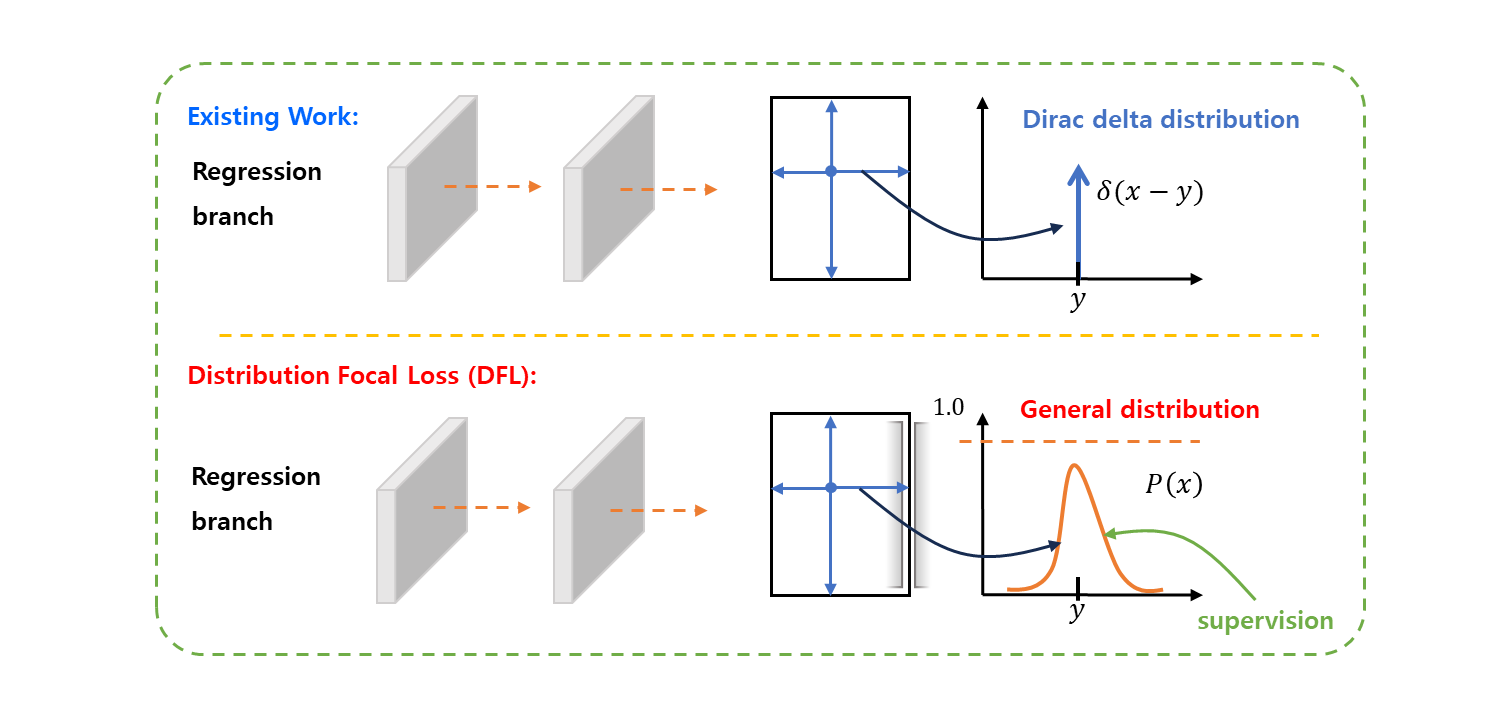
關鍵
DFL 將邊界回歸從單點預測轉為分佈學習,提供更密集的梯度訊號,顯著提升定位精度。