Resources - Metrics Server
什麼是 Metrics Server?
Metrics Server 是 Kubernetes 官方的輕量級聚合器,用於收集和提供集群中資源使用情況的指標數據。 它從各個節點的 Kubelet 中獲取資源數據(如 CPU 和記憶體使用率),並將這些數據提供給 Kubernetes 的 Horizontal Pod Autoscaler (HPA)、Vertical Pod Autoscaler (VPA) 和其他工具使用。
主要功能
- 資源監控:收集 Pod 和 Node 的即時資源使用數據,例如 CPU 和記憶體。
- 支援自動擴縮:提供數據給 HPA 和 VPA,以便動態調整工作負載的資源分配。
- 即時數據查詢:透過
kubectl top命令,輕鬆檢視集群的即時資源使用情況。
Metrics Server 的原理

Metrics Server 是 Kubernetes 的核心組件之一,用於即時收集、聚合並提供節點與 Pod 的資源使用指標(如 CPU 和記憶體),支援 Kubernetes 的資源調度與自動化功能(如 HPA 和 kubectl top)。
- 資料收集
- Kubelet:Metrics Server 通過 Kubernetes API Server 與各節點的 Kubelet 通訊,從
/metrics/resource/v1alpha1端點獲取即時的節點與 Pod 資源使用指標。 - cAdvisor:Kubelet 內部整合了 cAdvisor,負責從容器層面收集 CPU、記憶體等資源使用數據,這些數據經由 Kubelet 提供給 Metrics Server。
- Kubelet:Metrics Server 通過 Kubernetes API Server 與各節點的 Kubelet 通訊,從
- 數據聚合
- Metrics Server 以固定的時間間隔(預設 60 秒)從所有節點的 Kubelet 收集資源使用數據,並進行處理與聚合,形成整個集群的即時資源快照。
- 指標提供
- Metrics Server 將聚合後的資源數據通過
/apis/metrics.k8s.io/v1beta1端點提供給 Kubernetes 組件,支援如 HPA 和kubectl top等工具查詢。
- Metrics Server 將聚合後的資源數據通過
Metrics Server 架構

常見使用場景
-
Horizontal Pod Autoscaler (HPA) Metrics Server 提供 Pod 的即時資源使用數據,幫助 HPA 根據負載動態調整副本數量。
-
資源使用監控 運維人員可使用
kubectl top指令快速了解集群中 Pod 和 Node 的資源使用情況。 -
診斷與排查 Metrics Server 幫助識別資源瓶頸,例如某些 Pod 或 Node 的 CPU 或記憶體過度使用。
限制與注意事項
- Metrics Server 不儲存歷史數據,僅提供即時的資源使用快照。
- 需要確保集群中的 Kubelet 啟用了
--enable-metrics標誌,否則可能無法獲取數據。 - 無法直接用於長期資源監控(建議結合 Prometheus 等工具)。
實作一個 Metrics Server
安裝 Metrics Server
- 首先我們我先下載官方的 yaml 設定檔,因為後續需要做修改
Invoke-WebRequest -Uri "https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml" -OutFile "components.yaml"
- 因為我們是在測試環境,不需要設定憑證,因此在大概 136 行的地方,要加上
--kubelet-insecure-tls,修改後存檔。
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=10250
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
# 加上這個下面這行,因為我們在測試環境,因此不需要做CA憑證
- --kubelet-insecure-tls
image: registry.k8s.io/metrics-server/metrics-server:v0.7.2
imagePullPolicy: IfNotPresent
- 接下來就可以透過指令將他跑起來。
kubectl.exe apply -f components.yaml
---
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
- 接著我們就可以查看是否建立成功,看到 1/1 就代表成功建立了。
kubectl get pods -n kube-system | Select-String "metrics-server"
---
metrics-server-598746d78d-jld2d 1/1 Running 0 29s
顯示資源使用訊息
- 我們可以透過指令查看資源使用的狀況
kubectl.exe top pods -n kube-system
---
NAME CPU(cores) MEMORY(bytes)
coredns-5d78c9869d-rpqhf 1m 26Mi
coredns-5d78c9869d-sjhtn 1m 25Mi
etcd-docker-desktop 9m 100Mi
kube-apiserver-docker-desktop 12m 326Mi
kube-controller-manager-docker-desktop 7m 73Mi
kube-proxy-8fmdr 1m 27Mi
kube-scheduler-docker-desktop 2m 34Mi
metrics-server-598746d78d-jld2d 2m 26Mi
storage-provisioner 1m 22Mi
vpnkit-controller 1m 17Mi
kubectl.exe top node
---
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
docker-desktop 178m 0% 3080Mi 19%
打造資源監控系統
接著我們可以透過 cAdvisor(Container Advisor) 結合 Prometheus 和 Grafana,實現對 Docker 容器的 CPU、記憶體、磁碟及網路等資源的全面監控。
cAdvisor
cAdvisor(Container Advisor)是一個開源工具,用於實時監控容器的資源使用情況,如 CPU、記憶體、磁碟和網路。它由 Google 開發,與 Kubernetes 深度整合,能夠收集容器的性能指標並提供可視化的監控數據。
- 首先我們測試 docker 是否可以使用,正確的話會顯示出版本。
docker --version
---
Docker version 24.0.6, build ed223bc
- 接著我們需要把 cAdvisor 的 image pull 下來。
docker pull google/cadvisor
---
Using default tag: latest
latest: Pulling from google/cadvisor
Digest: sha256:815386ebbe9a3490f38785ab11bda34ec8dacf4634af77b8912832d4f85dca04
Status: Image is up to date for google/cadvisor:latest
docker.io/google/cadvisor:latest
- 接著我們試著把 cadvisor 跑起來,透過 docker 指令。
docker run `
--volume=/:/rootfs:ro `
--volume=/var/run:/var/run:rw `
--volume=/sys:/sys:ro `
--volume=/var/lib/docker:/var/lib/docker:ro `
--publish=8884:8080 `
--detach=true `
--name=cadvisor `
google/cadvisor:latest
- 透過網站http://localhost:8884/containers/,如果可以查看目前的所有電腦狀態,就代表我們成功了。

- 接著我們將他關閉,後續我們會用 docker-compose 一起把他跑起來。
docker rm -f cadvisor
---
cadvisor
Prometheus + Grafana
Prometheus 是一個開源的監控系統和時序數據庫,專注於收集和存儲指標數據,並提供強大的查詢語言(PromQL)進行數據分析。它支援多種數據抓取方式,與容器化環境(如 Kubernetes)高度兼容,常用於系統和應用性能監控。
Grafana 是一款開源的數據可視化和監控工具,廣泛應用於分析和展示來自各種數據源(如 Prometheus、Elasticsearch、InfluxDB 等)的時間序列數據。它提供直觀的儀表板和強大的圖表功能,使用者可以輕鬆創建動態儀表板來監控系統性能、應用狀態以及業務指標。Grafana 支援即時數據更新,並提供豐富的插件擴展選項,讓使用者根據需求定制監控界面。
- 檢查 docker-compose 指令,出現版本代表正常。
docker-compose --version
----
Docker Compose version v2.21.0-desktop.1
- 接著我們撰寫所有需要的 container,包含監控系統數據庫 prometheus、可視化監控工具 grafana、實時監控容器的資源 cadvisor。
version: '3.8'
services:
prometheus:
image: prom/prometheus:v2.35.0
container_name: prometheus
volumes:
- ./prometheus-with-cadvisor.yaml:/etc/prometheus/prometheus.yaml
- ./prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yaml'
ports:
- '9090:9090'
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
ports:
- '9100:9100'
renderer:
image: grafana/grafana-image-renderer
environment:
BROWSER_TZ: Asia/Taipei
ports:
- '8082:8081'
grafana:
image: grafana/grafana
container_name: grafana
volumes:
- ./grafana_data:/var/lib/grafana
environment:
GF_SECURITY_ADMIN_PASSWORD: pass
GF_RENDERING_SERVER_URL: http://renderer:8082/render
GF_RENDERING_CALLBACK_URL: http://grafana:3007/
GF_LOG_FILTERS: rendering:debug
depends_on:
- prometheus
- renderer
ports:
- '3007:3000'
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
ports:
- '8884:8080' # cAdvisor 預設埠號
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
restart: unless-stopped
- 另外我們還需要撰寫一個設定檔,告訴 prometheus 有哪些 job 要做,另外也需要告訴他 cAdvisor 和 node-exporter 的資訊。
global:
scrape_interval: 5s # Server 抓取頻率
external_labels:
monitor: 'my-monitor'
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
labels:
instance: 'server' # node-exporter 和 cadvisor 必須相同
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080'] # cAdvisor 的服務位址和埠號
labels:
instance: 'server' # node-exporter 和 cadvisor 必須相同
node-exporter 和 cadvisor 的 labels.instance 名稱必須相同
- 透過 docker-compose 的指令,我們就能將所有的 container 跑起來。
docker-compose -f ./deployment-with-cadvisor.yaml up -d
---
[+] Running 6/6
✔ Network ch24_default Created 0.0s
✔ Container node-exporter Started 0.0s
✔ Container ch24-renderer-1 Started 0.0s
✔ Container prometheus Started 0.1s
✔ Container cadvisor Started 0.0s
✔ Container grafana Started 0.0s
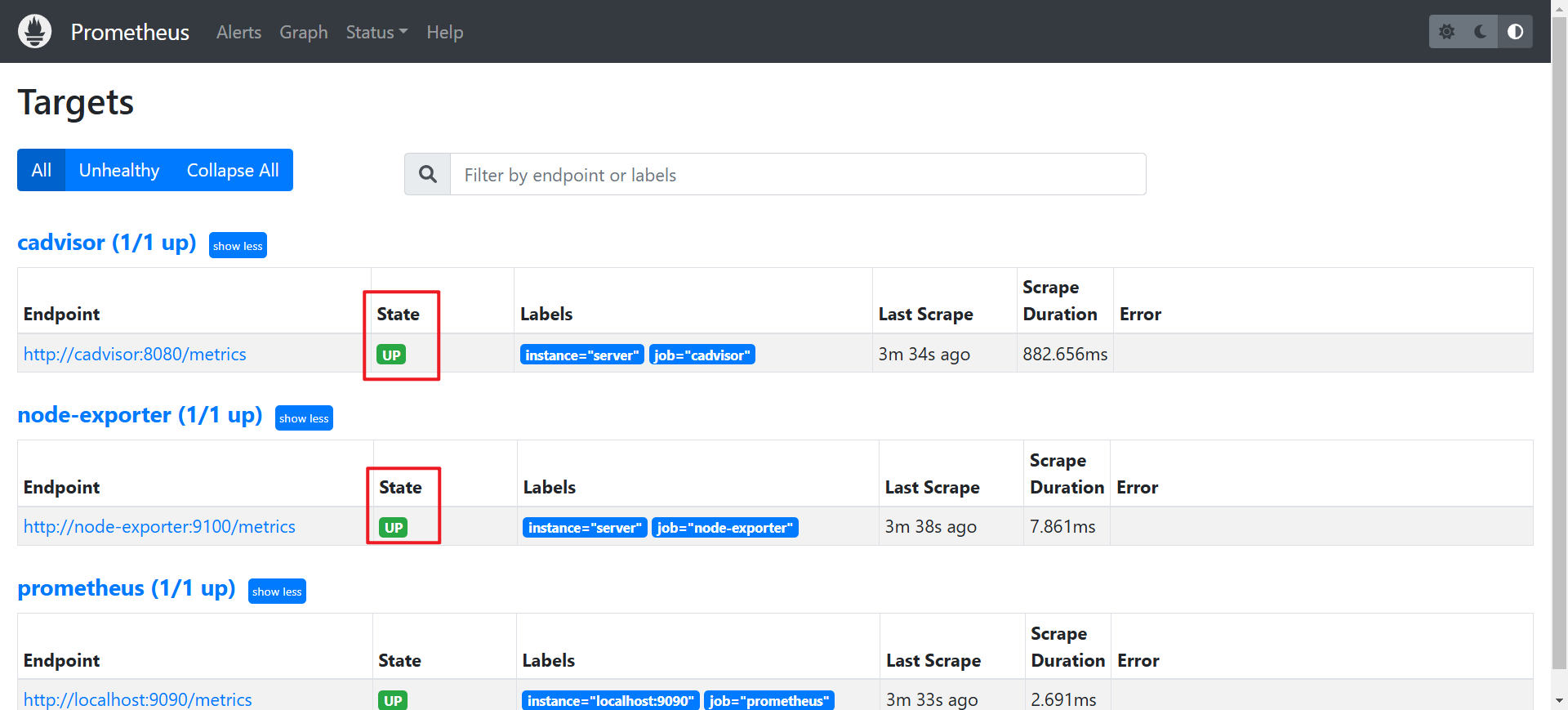
- 接著我們進到 prometheus 的 GUI 介面http://localhost:9090/targets,查看一下是否有抓到 cAdvisor 的數據、並且還有 node-exporter 的數據。
設定 Grafana 的 Data Source
- 接著我們需要將 prometheus 的數據傳給 grafana 做顯示,因此我們首先需要選擇到 data source 的頁面。
- 接下來我們新增一個 prometheus 的 datasource。
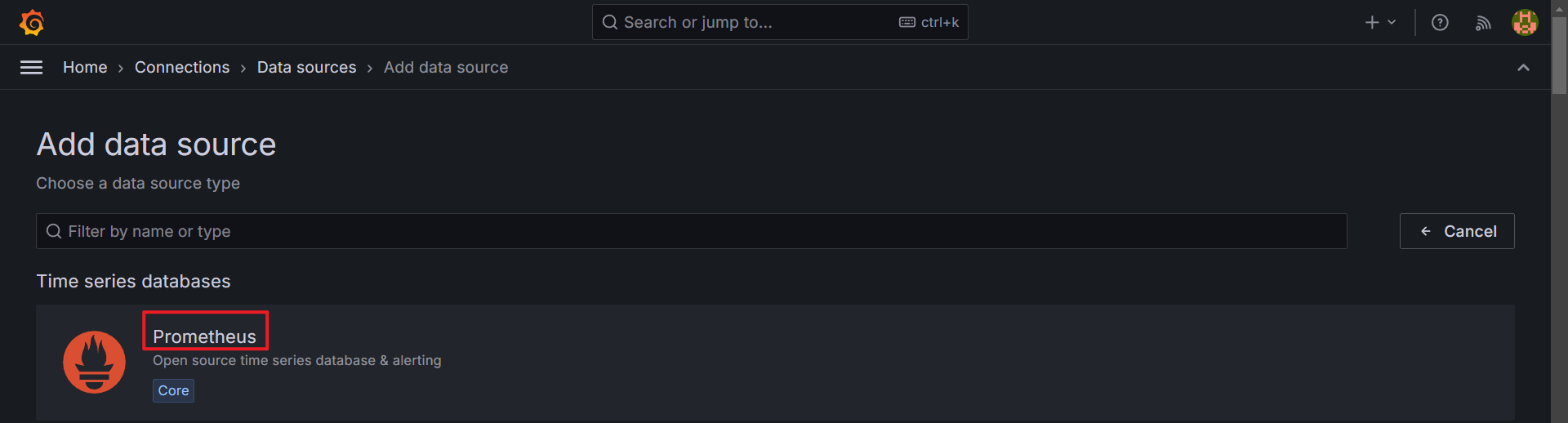
- 在網址的地方我們填寫
http://prometheus:9090/。

- 接著我們存檔並測試,出現綠色的框框就代表測試 OK 囉,就可以下一步創立 dashboard。

設定 Grafana 模板
Grafana 提供了強大的數據可視化功能,我們可以��從網路上下載並使用適合的儀表板模板。
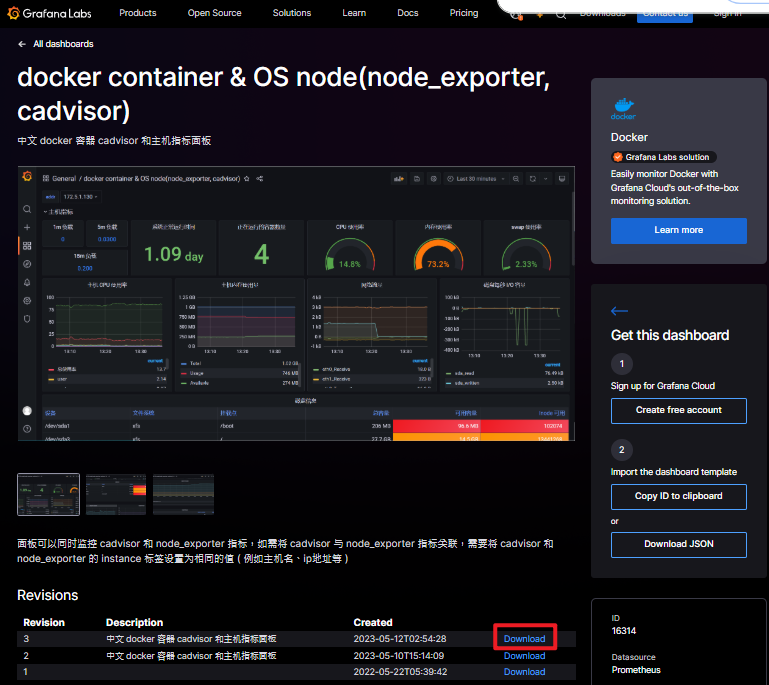
- 因為我們要結合 cAdvisor,因此我們使用 docker container & OS node(node_exporter, cadvisor) 這個模板,進到網站後點選下載 json。
- 我們可以進到網站http://localhost:3007/login,因為我們是做實驗,因此 grafana 的帳號預設為 admin,密碼則是 pass,要修改可以在上面 docker-compose 定義的 yaml 中修改。
- 接著選到 dashboard 的分頁,並且新增選擇 import,將剛剛的 json 檔拖拉到 upload 的地方即可,並且 datasource 選擇剛剛建立的 prometheus。
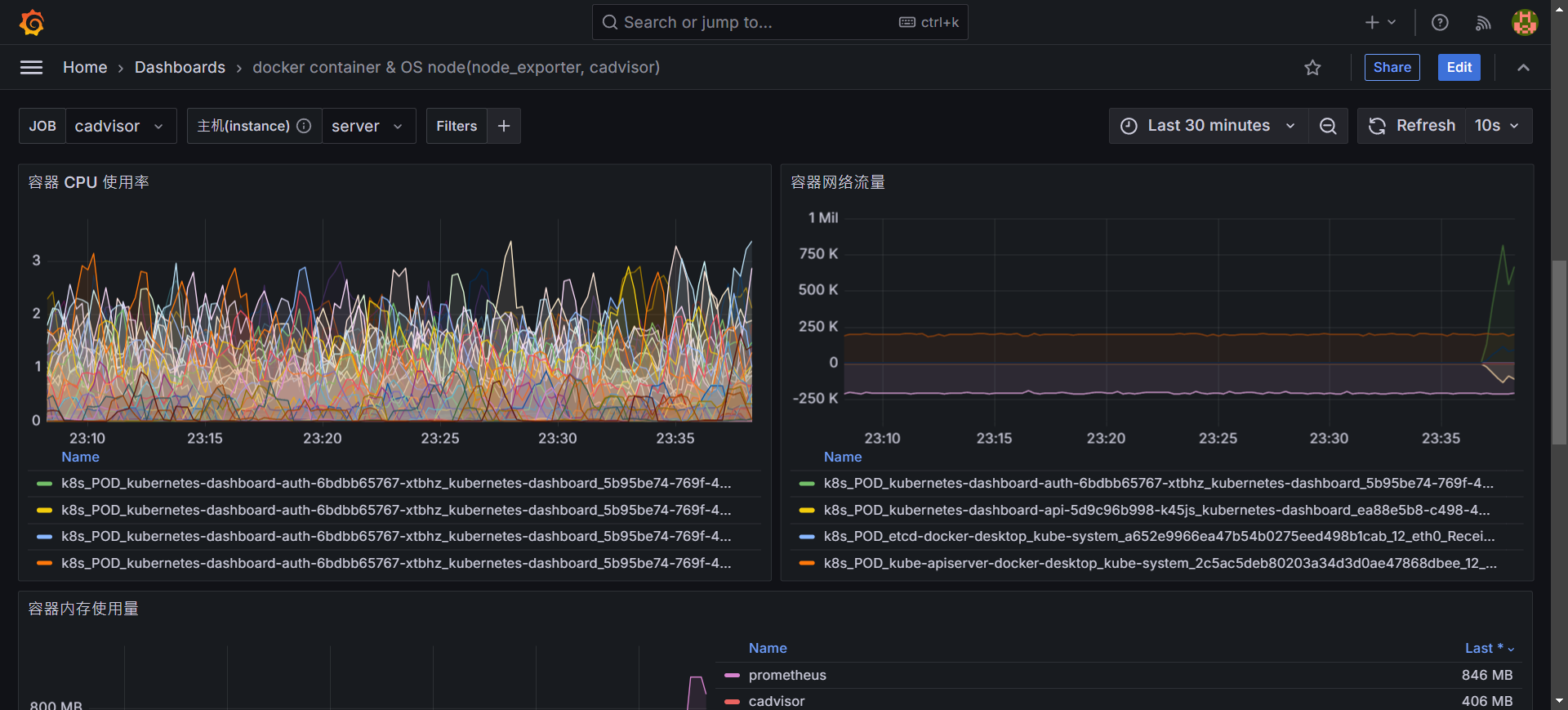
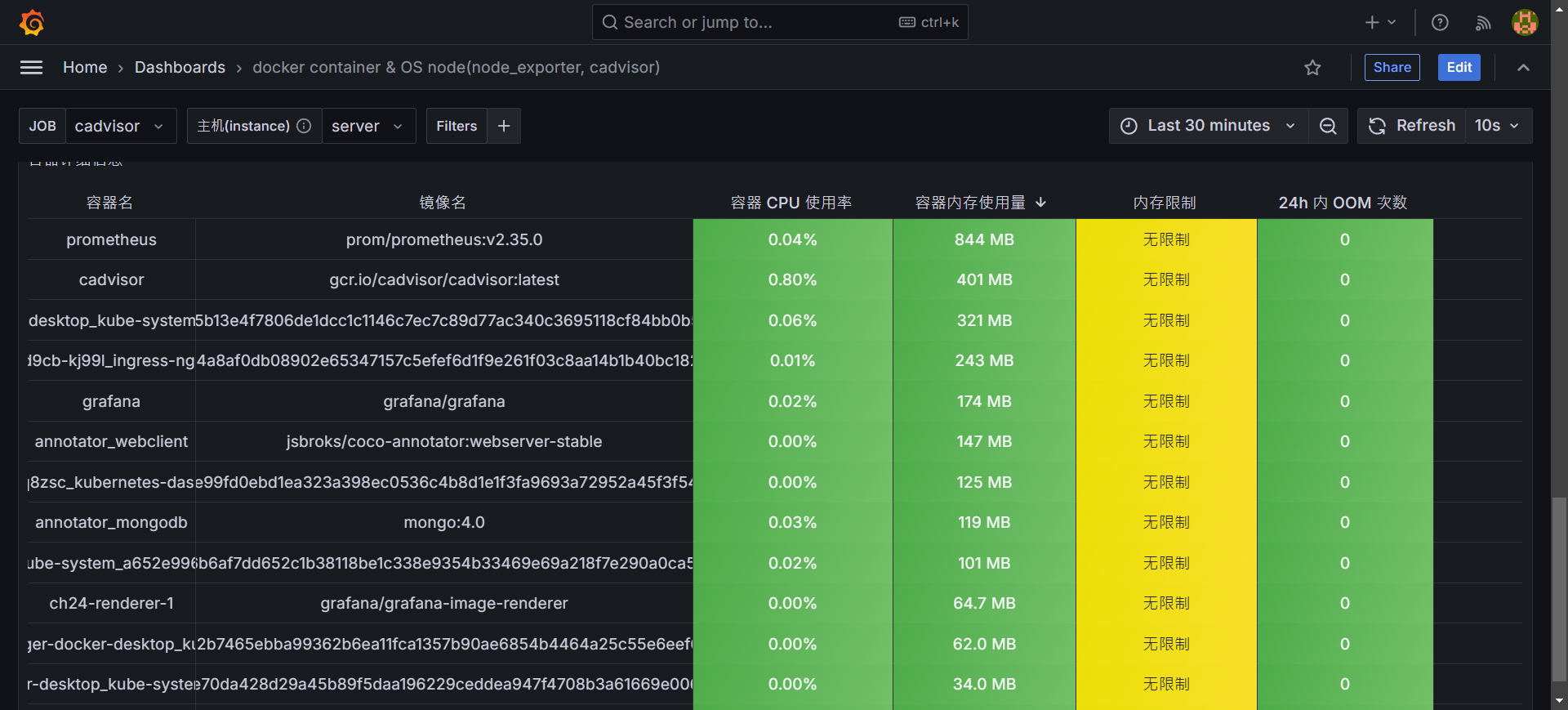
視覺化監控系統展示
- 上半部提供 node 的本身的 CPU 使用率、Memory 使用狀況、網路狀況、硬碟使用狀況等等資訊。
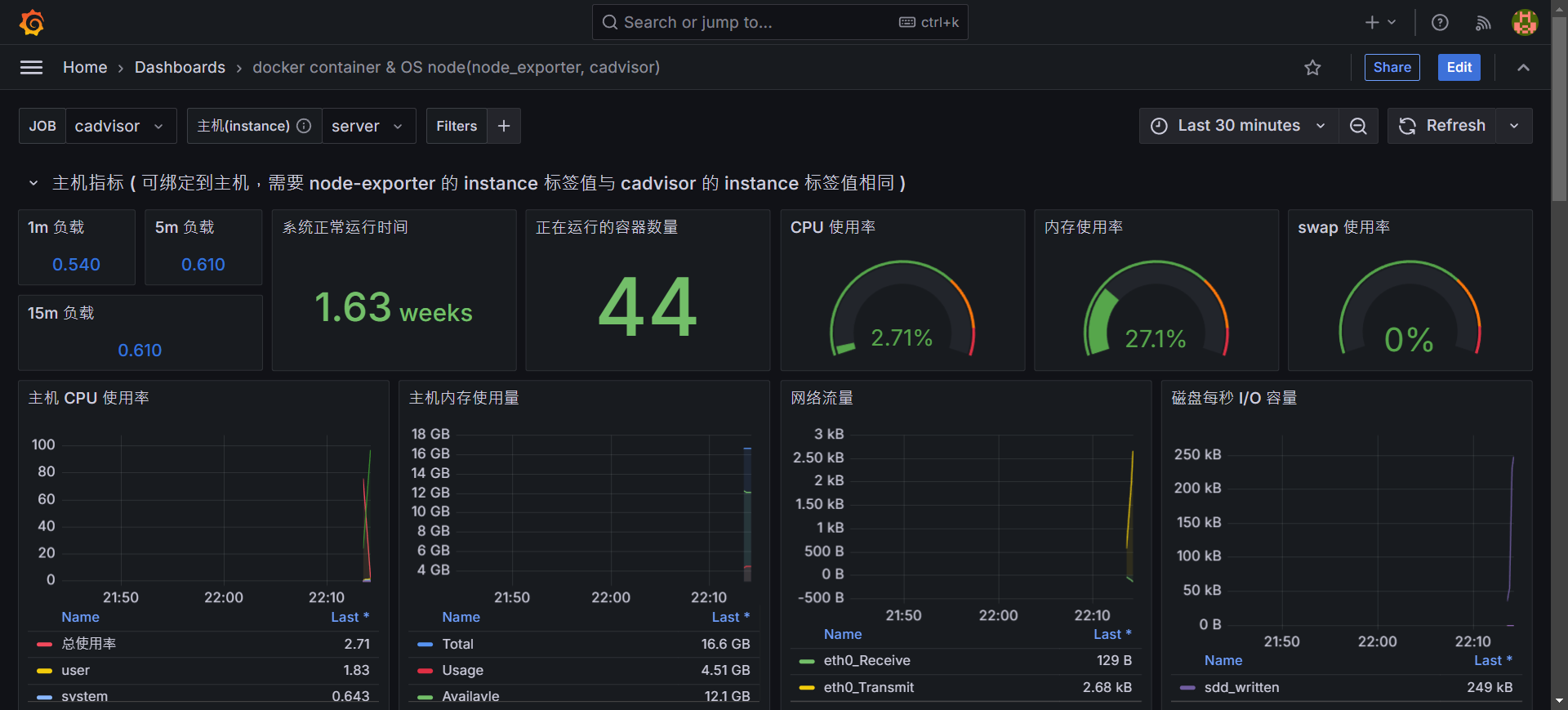
- 下半部提供各個 container 使用的狀況,另外也提供詳細訊息,可以快速找尋有問題的 container。