深度學習中的優化技巧 - 自動調整學習速率 (Adaptive Learning Rate)
為什麼需要客製化的學習速率?
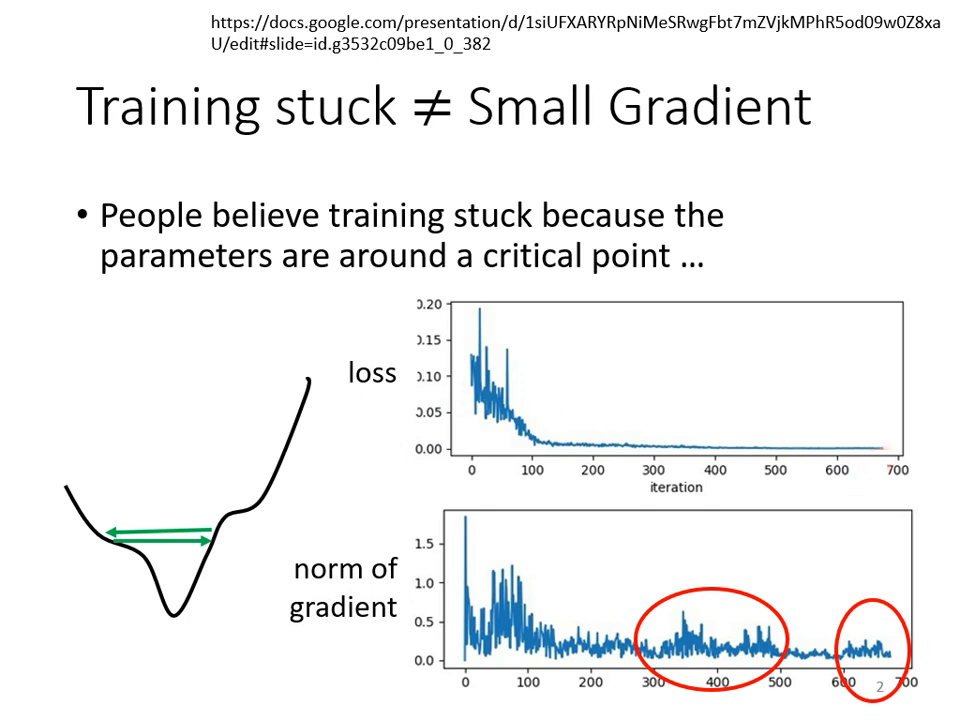
在優化過程中,Training Loss 不再下降並不代表走到了臨界點(Critical Point)。有時 Gradient 依然很大,但 Loss 卻卡住或震盪,這通常是因為 Error Surface 的形狀複雜所致。
- 峽谷地貌的問題: 在某些參數方向上(如橢圓長軸)坡度非常平滑,梯度極小;而在另一個方向(如短軸)坡度卻非常陡峭,梯度變化極大。
- 傳統方法(Gradient Descent)的困境:
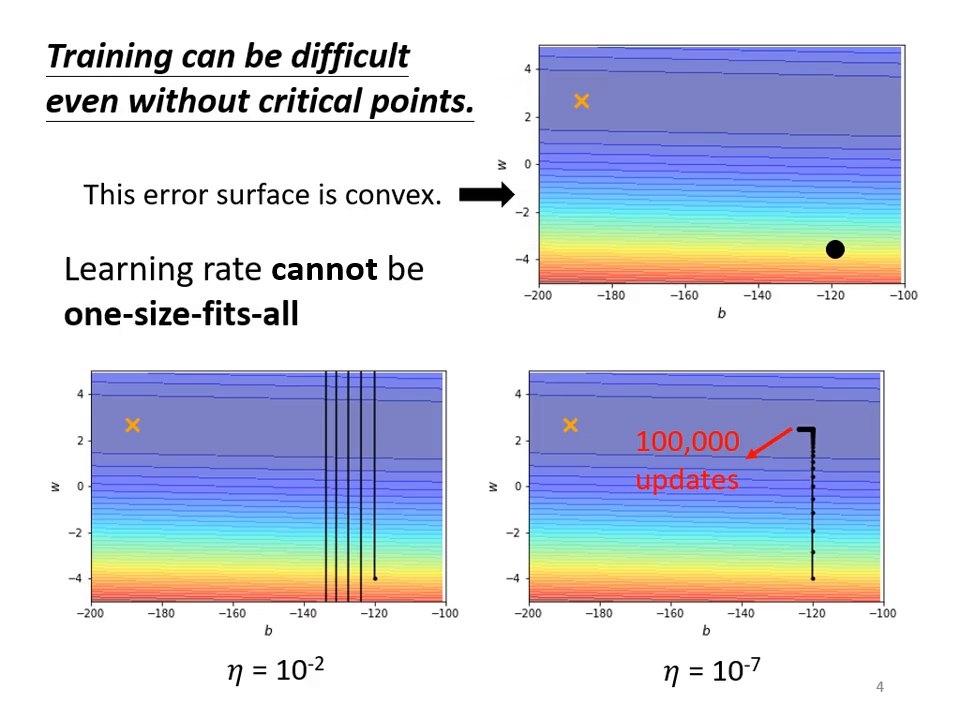
- 若 Learning Rate 設太大,參數會在峽谷兩端山壁間震盪,Loss 掉不下去。
- 若 Learning Rate 設太小,雖然能停止震盪,但在平滑區域前進速度極慢,永遠走不到終點。
- 核心原則: 學習速率應該為每一個參數「客製化」。在坡度平坦時調大 Learning Rate,在坡度陡峭時��則調小。
 |  |
|---|---|
| 山谷的谷壁間來回走 | Gradient Descent 的困境 |
常見的自動調整演算法
透過將原本的 Learning Rate 改寫為 ,讓學習速率變得與參數()及時間()相關。
-
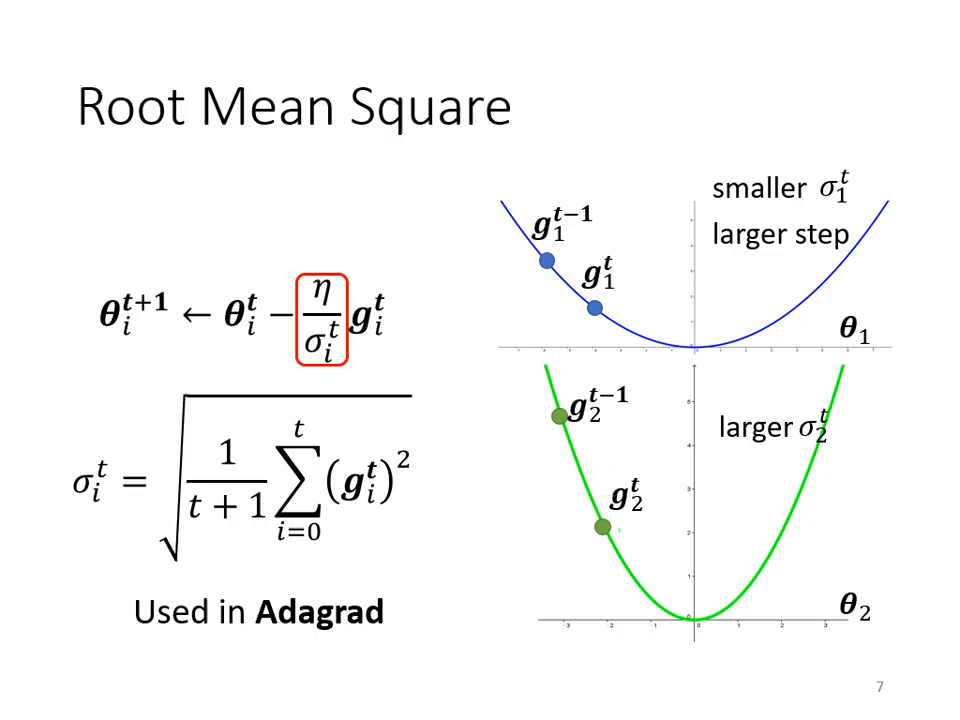
Adagrad (Root Mean Square):
- 原理: 將學習速率除以「過去所有 Gradient 的平方和之平均再開根號」。
- 效果: 梯度小的參數 小,Learning Rate 就會變大;梯度大的參數 大,Learning Rate 就會變小。
-
RMS Prop (動態調整):
- 背景: 即使是同一個參數,在不同訓練階段也需要不同 Learning Rate(如新月形 Error Surface)。
- 做法: 引入超參數 ,讓模型可以自己決定「目前的 Gradient」與「過去 Gradient 的統計值」哪個比較重要。這讓模型能像踩煞車一樣,一遇到陡坡就迅速縮小 Learning Rate。
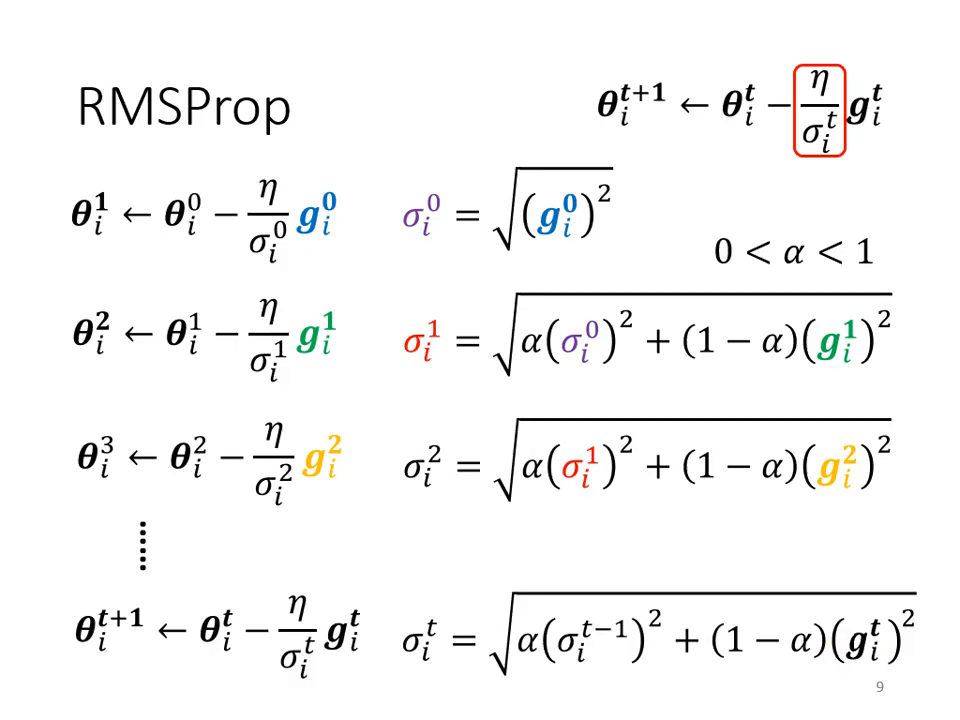
-
Adam (當今主流):
- 定義: RMS Prop + Momentum。
- 特性: 同時考慮了方向(動量)與大小(自動調整速率),是目前最常用的 Optimizer。

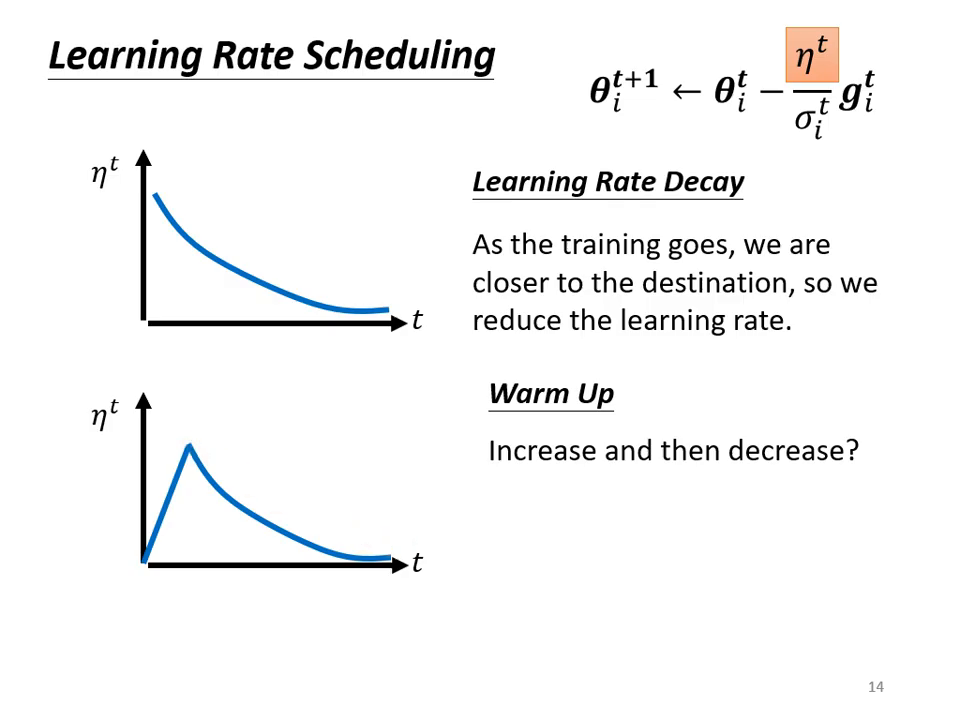
學習速率排程 (Learning Rate Scheduling)
除了根據梯度調整 ,我們也可以透過改變分子項 來優化訓練過程。
- Learning Rate Decay (學習率衰減):
- 隨著更新次數增加,讓 越來越小。
- 理由: 訓練初期離終點遠,步伐可大;後期接近終點時應減速,確保平順收斂。
- Warm Up (預熱):
- 做法: 學習率先變大後變小。
- 解釋: 訓練初期 的統計數據還不夠精準,不應讓參數跑離初始點太遠。先用小 Learning Rate 探索並收集 Error Surface 的情報(統計 ),等精準後再加速。這是一項常用於 BERT 或 Transformer 等大型網路的關鍵技術。
總結:優化器的完整版本
一個現代化的優化器通常包含以下三個元素:
- Momentum (動量): 考慮過去所有梯度方向的總和(帶正負號)。
- (Root Mean Square): 考慮過去所有梯度的大小(平方後不計方向),用來縮放學習率。
- Scheduling: 隨時間動態調整整體學習率的基準。
