自注意力機制 (Self-attention)
設計動機:處理長度不一的向量序列
傳統的網路架構(如全連接網路或 CNN)通常假設輸入是固定長度的向量,但在現實中,許多問題的輸入是一排長度會改變的向量序列 (Sequence of Vectors)。
- 文字處理:一個句子由多個詞彙組成,每個詞彙可表示為一個向量(如 One-hot Encoding 或具備語義資訊的 Word Embedding),而句子的長度各不相同。
- 語音處理:一段聲音訊號可切分為多個 Window(稱為 Frame),一秒鐘的聲音通常包含約 100 個向量。
- 圖形結構 (Graph):社交網絡中的節點(人)或分子結構中的原子,都可以看作是一堆向量組成的圖形。
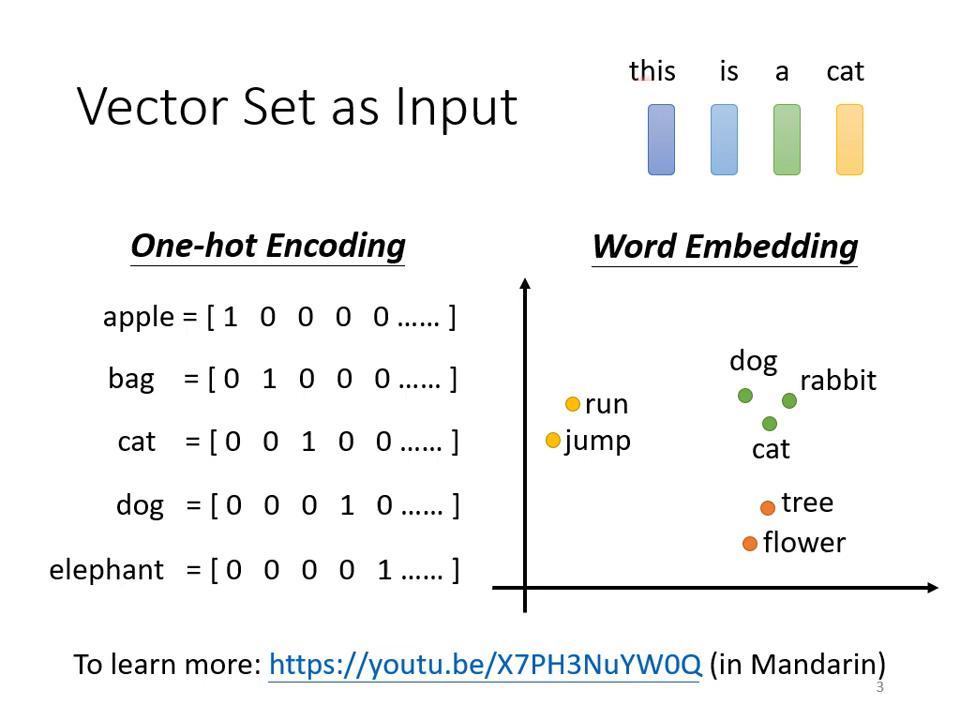 | 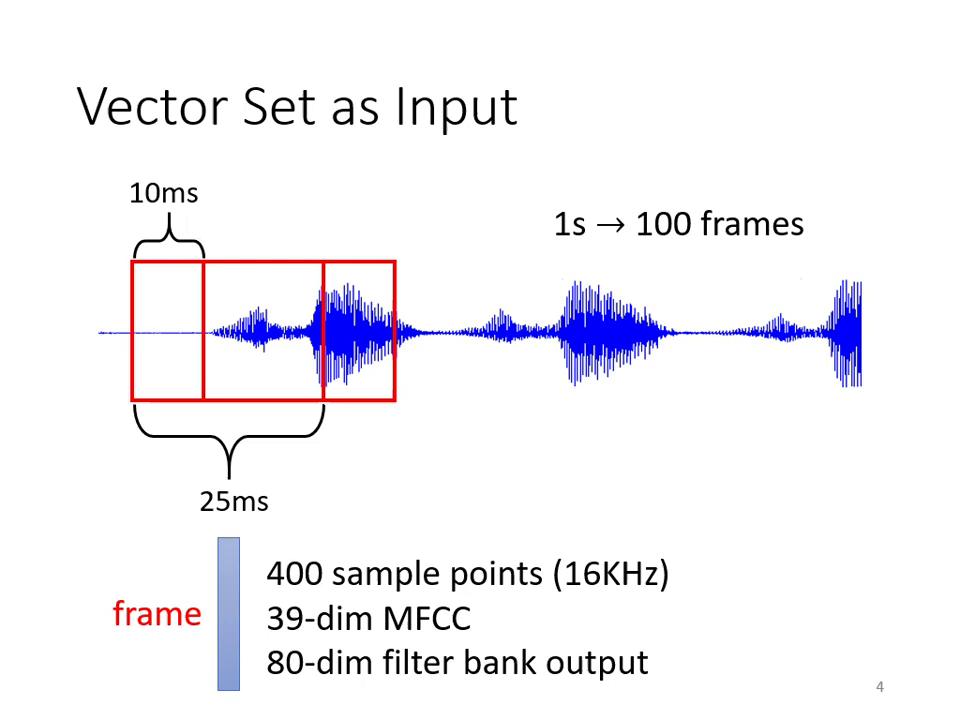 |
|---|---|
| 文字處理 | 語音處理 |
 | 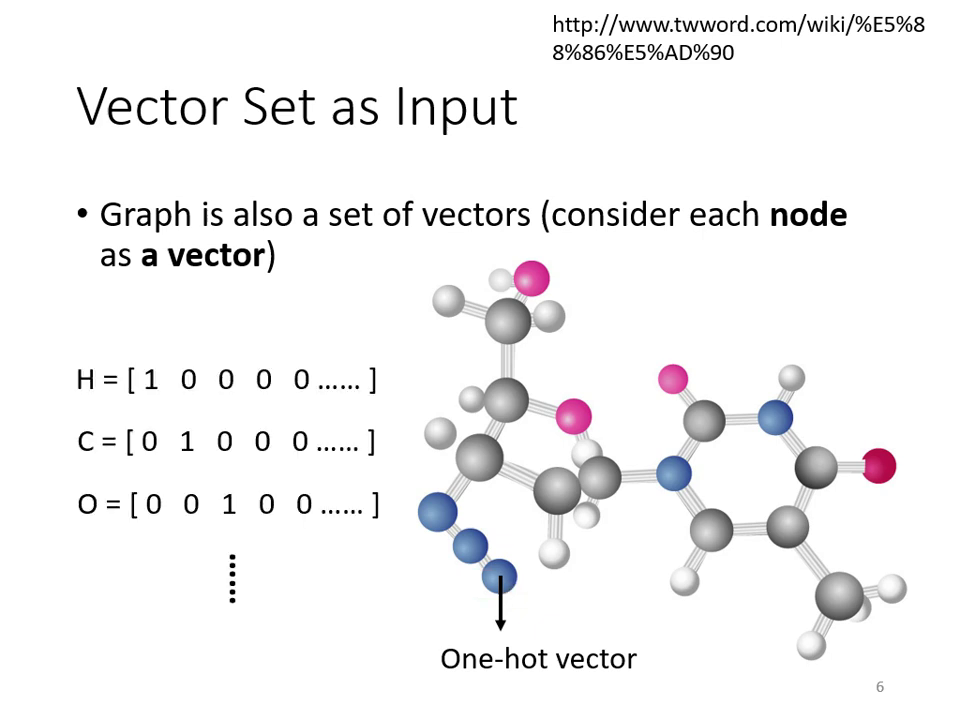 |
|---|---|
| 社交網絡 | 分子結構 |
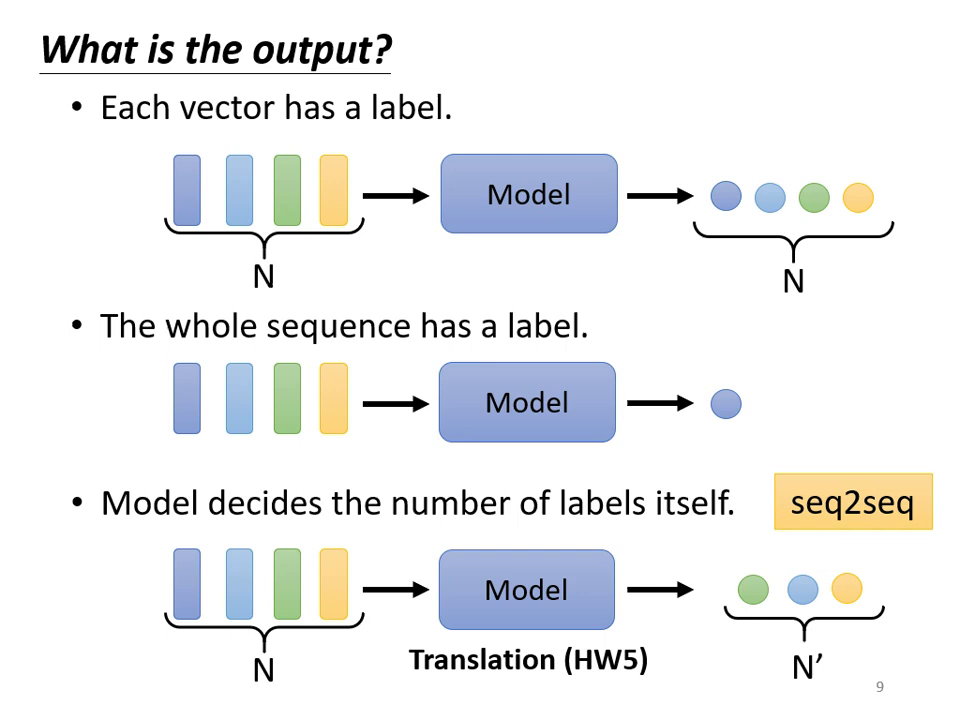
輸出類型的三種可能性
根據任務需求,Self-attention 的輸出可分為:
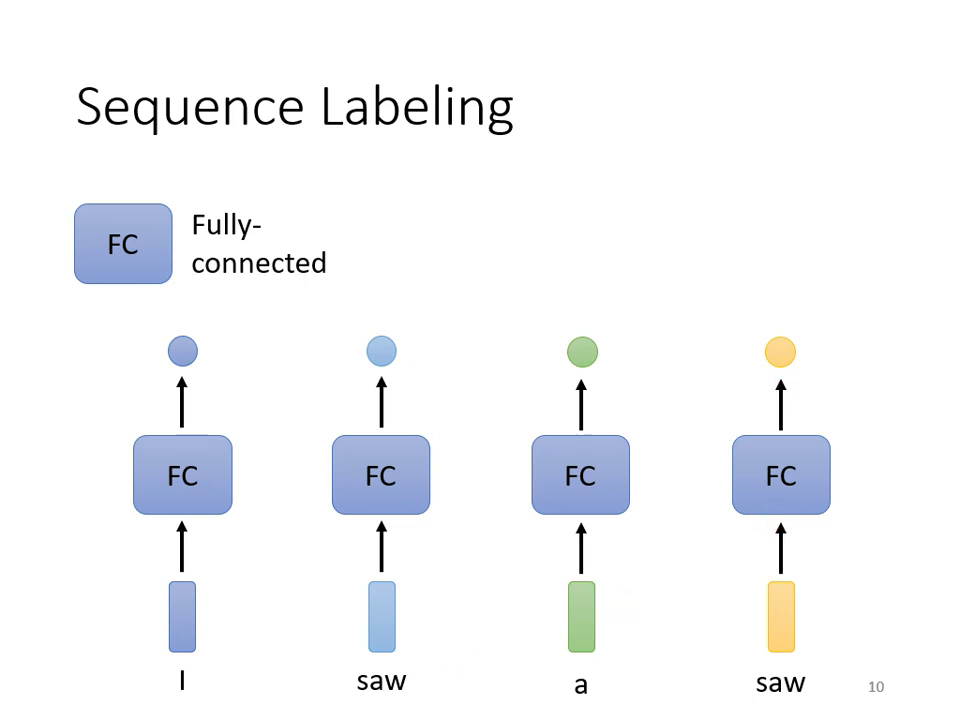
- 每個向量對應一個 Label:又稱 Sequence Labeling(如詞性標注 POS Tagging),輸入 個向量則輸出 個標籤。
- 一整個 Sequence 輸出一個 Label:如情感分析 (Sentiment Analysis) 或語者辨認。
- 機器自行決定輸出長度:又稱 Sequence to Sequence 任務(如機器翻譯、語音辨識)。
為什麼需要 Self-attention? (對比全連接層)
- FC 的瑕疵:全連接網路 (Fully-Connected Network) 在處理序列時,會將每個向量視為獨立個體。這導致在詞性標注時,無法分辨同一個詞(如 "saw")在不同上下文中的詞性(動詞或名詞)。
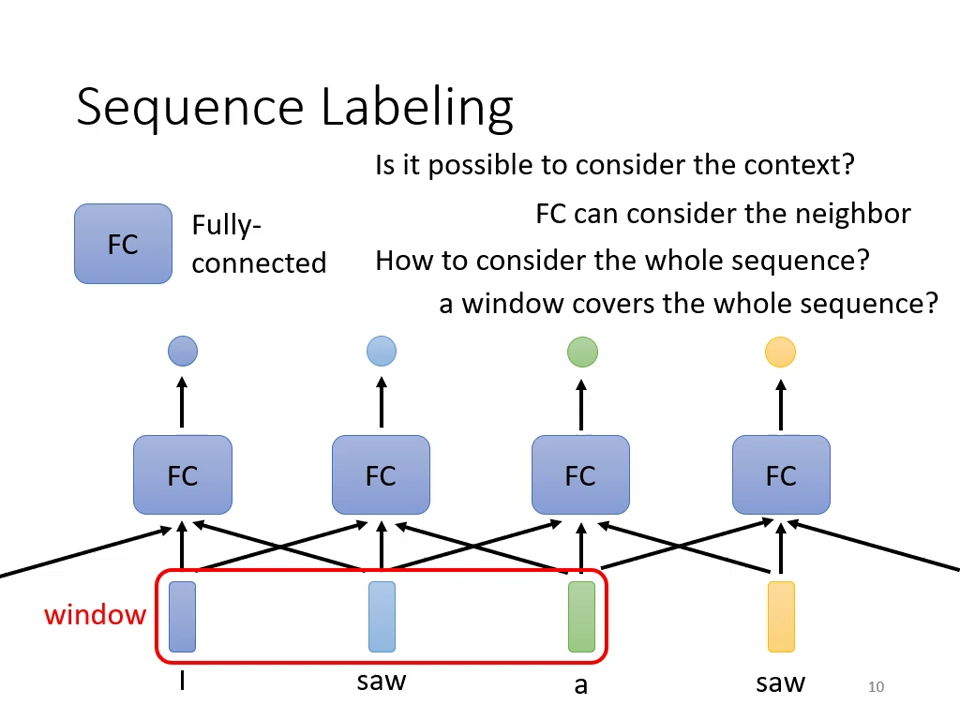
- Window 的極限:雖然可以用滑動視窗 (Window) 考慮上下文,但若需考慮整個 Sequence 的資訊,Window 會變得過大,導致參數量暴增且容易 Overfitting。
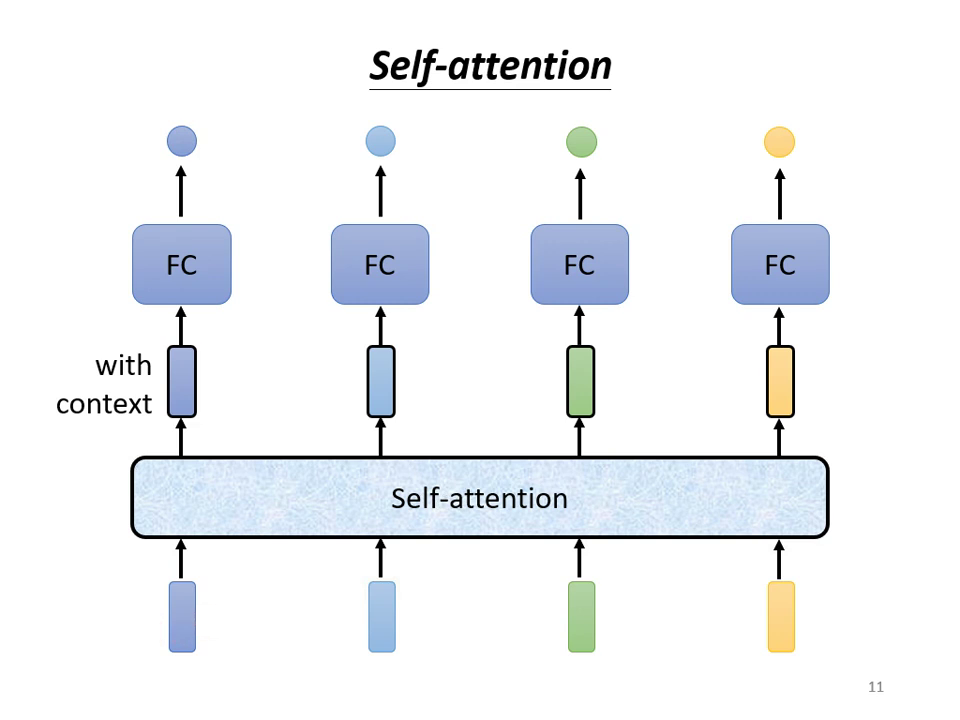
- Self-attention 的優勢:它能「吃」進整個 Sequence 的資訊,Input 幾個向量就 Output 幾個向量,且每一個輸出的向量都考慮了整個 Sequence 的上下文資訊。
 |  |
|---|---|
| FC 無上下文感知,無法判別同詞異義 | 大型 Window 導致參數膨脹與過擬合 |
 |  |
|---|---|
| Self-Attention:全序列上下文感知 | Self-attention 內部架構 |
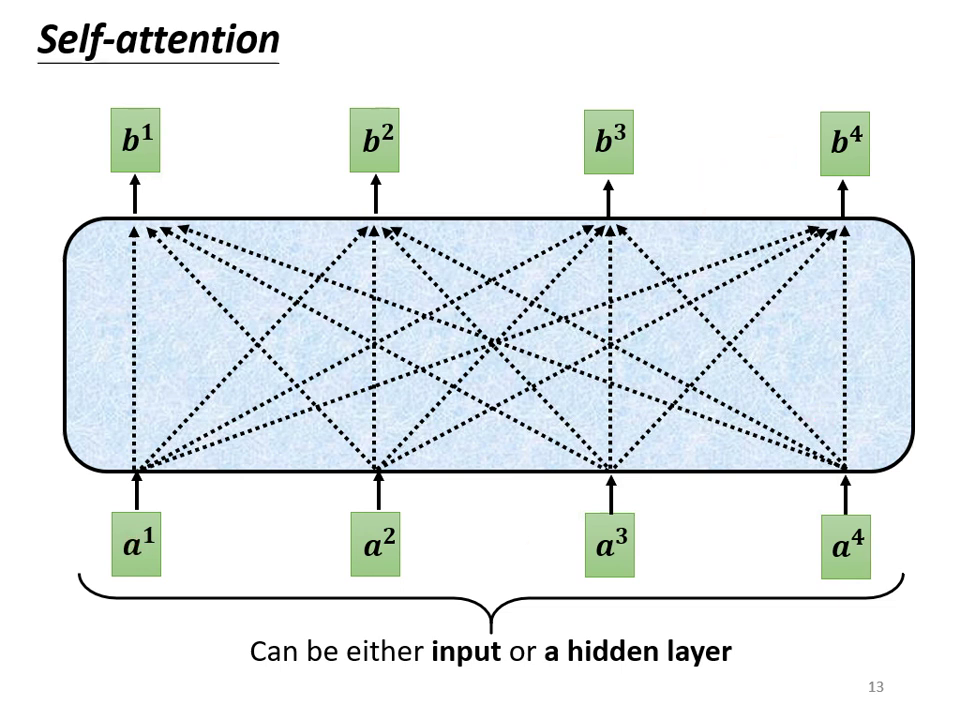
Self-attention 運作原理:具體步驟
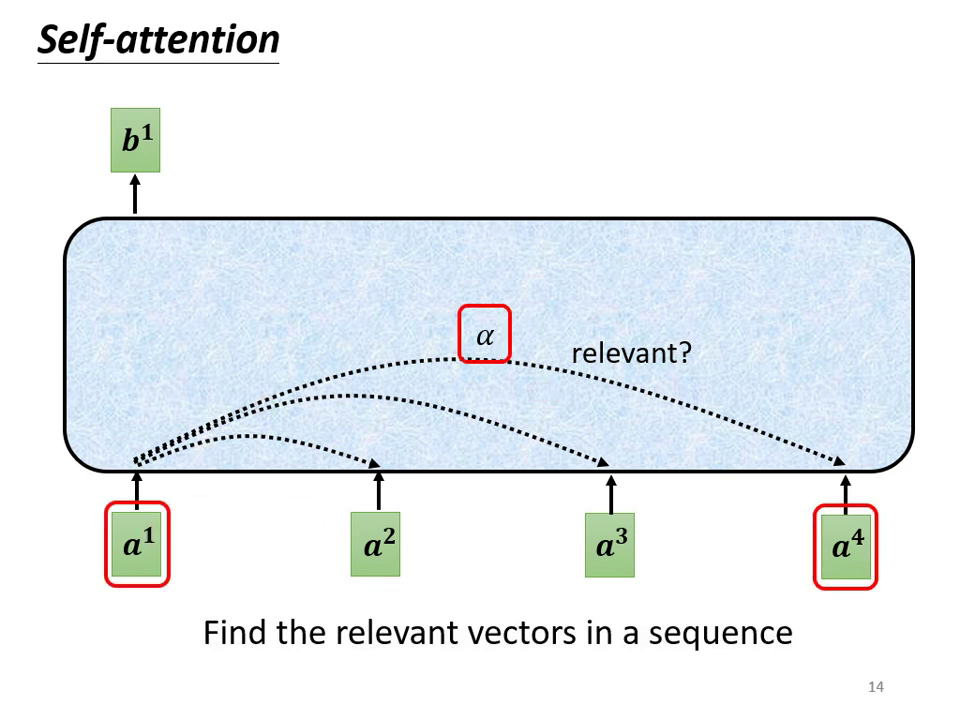
Self-attention 的目標是讓輸出向量考慮整個序列的資訊。以下以產生第一個輸出向量 為例:
-
尋找相關程度 : 根據 找出序列中與其相關的其他向量。每一個向量與 的關聯程度用數值 (Attention Score,注意力分數) 來表示。
-
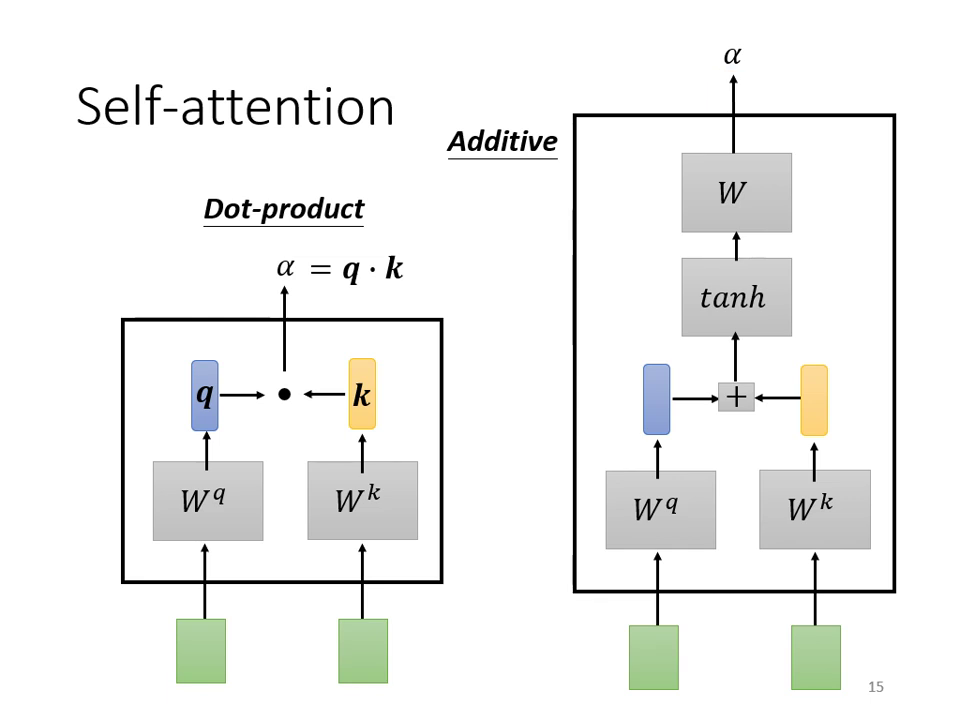
計算 Attention 的模組: 透過以下兩種方式計算 (Query,搜尋關鍵字)與 (Key,被搜尋的索引)的關聯性:
- Dot-product(最常用): 將輸入向量分別乘上矩陣 與 得到向量 與 。將 與 做點積(逐元素相乘後加總),得到標量 。這是 Transformer 所採用的方法。
- Additive: 同樣先得到 與 ,但將其 串接(Concatenate) 後過一個激活函數(如 ),再通過一次轉換得到 。
-
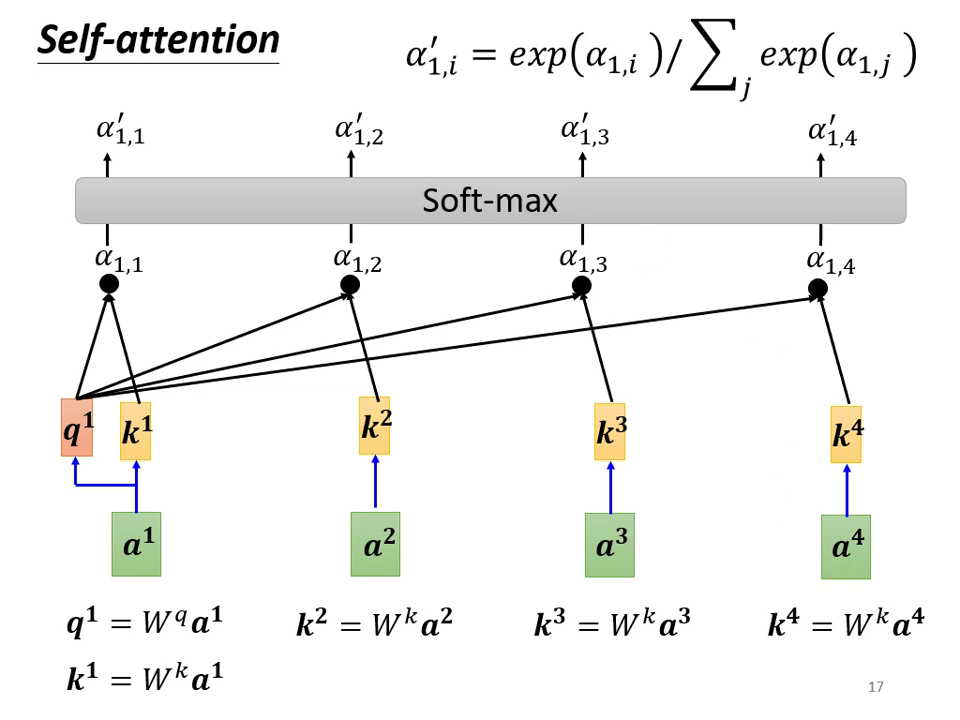
數值正規化: 計算 與所有向量(包含自己)的 後,將其通過 Softmax 函數得到 。
- 註:此處不一定要用 Softmax,亦可使用 ReLU 等其他激活函數,有時效果甚至更好。
-
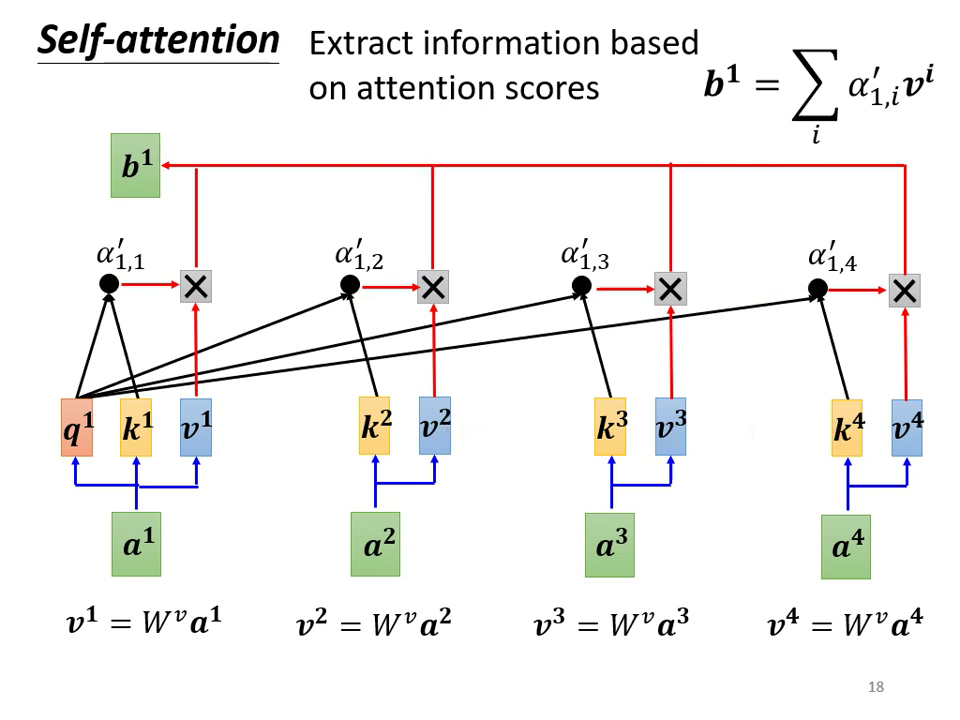
抽取資訊(加權權總和): 將 到 乘上矩陣 得到新的向量 到 (代表實際內容資訊),再將這些向量與對應的 相乘後加總,得到 。
- 邏輯:若 與 相關性極高( 很大),則 的內容會被 主導(Dominant)。
- 注意:在實際運算中, 到 是透過矩陣運算同時被計算出來的。
矩陣的角度 (Matrix View)
從矩陣運算的視角,可以更高效地描述上述過程:
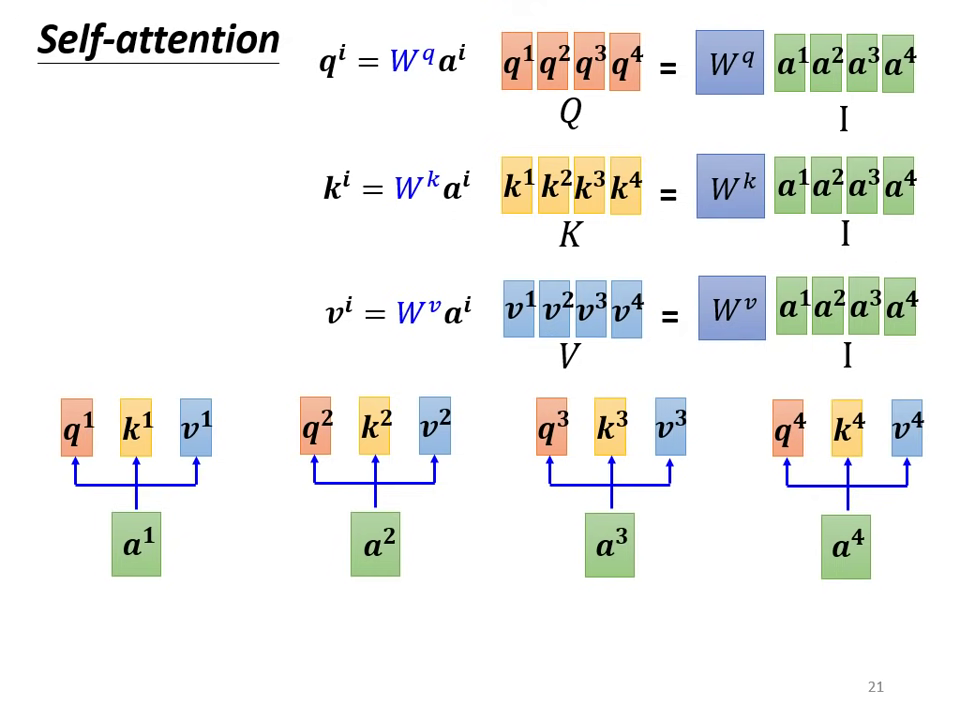
- 生成 Q, K, V:
將輸入向量組成矩陣 ,分別乘上三個需要學習的矩陣參數 ,得到矩陣 (Query)、 (Key) 與 (Value)。
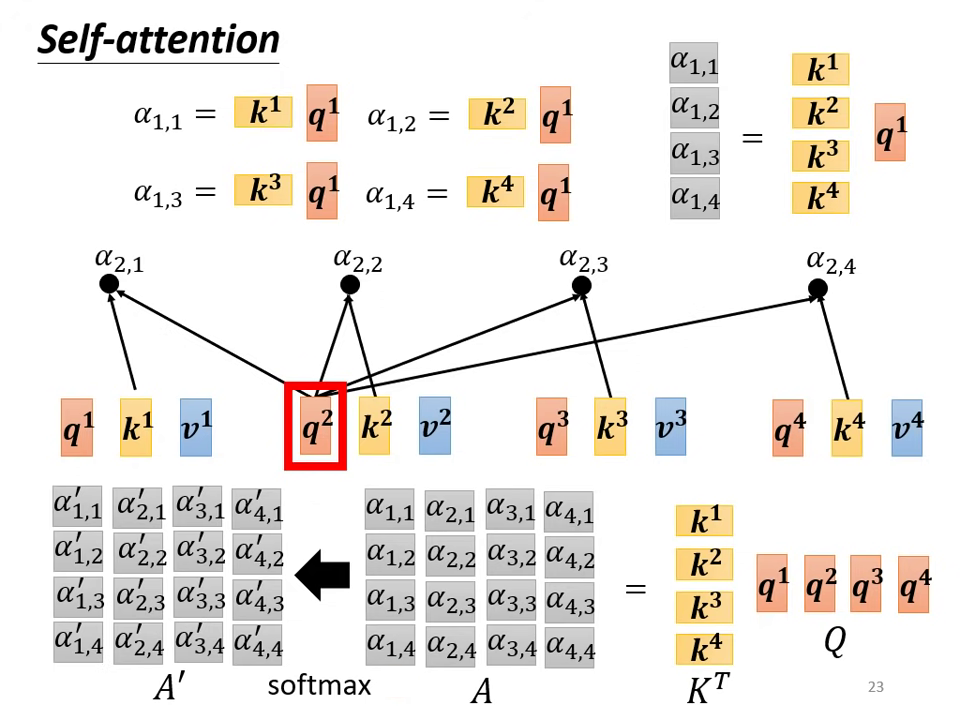
- 計算 Attention Matrix:
將 乘上 的轉置矩陣 得到關聯矩陣 。將 經過激活函數(如 Softmax 或 ReLU)處理,得到 (Attention Matrix)。
- 核心目的:生成 就是為了與 匹配以獲得 Attention Score。
- 核心目的:生成 就是為了與 匹配以獲得 Attention Score。
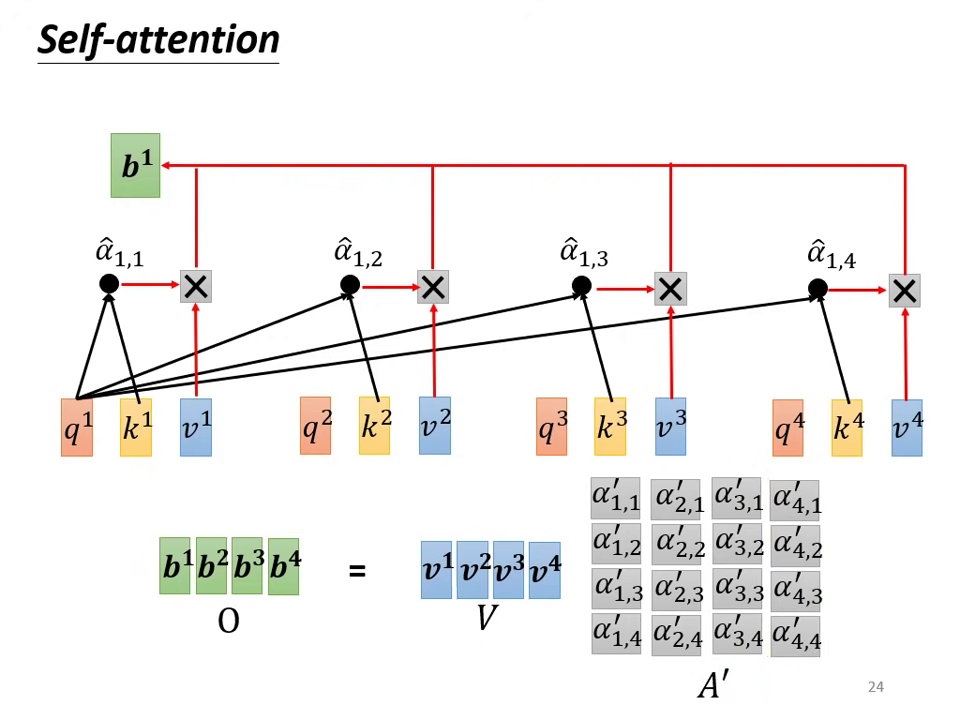
- 輸出結果:
將 乘上 ,得到最終輸出矩陣 (即所有 向量的集合)。

Multi-head Self-attention
Multi-head 機制在翻譯與語音識別等任務中表現優異,Head 的數量是一個需要調整的超參數 (Hyperparameter)。
- 原因: 在使用 尋找 時,向量間的 「相關性」可能存在多種形式(例如語義相關、位置相關等�)。多個 Head 可以讓不同的 分別負責偵測不同種類的相關性。
- 步驟:
- 將 轉換為 後,再將 乘上不同矩陣拆分為 (代表多個 Head), 與 亦同。
- 獨立計算:在同一個 Head 的範圍內(如 )獨立進行上述的 Self-attention 計算得到 。
- 合併資訊:將各個 Head 計算出的 進行拼接 (Concatenate),通過一個轉換矩陣 (Transform) 得到最終的 並送到下一層。
 |  |
|---|---|
| 從同一個 head 裡的 計算 | 將各 head 輸出串接並轉換為 |
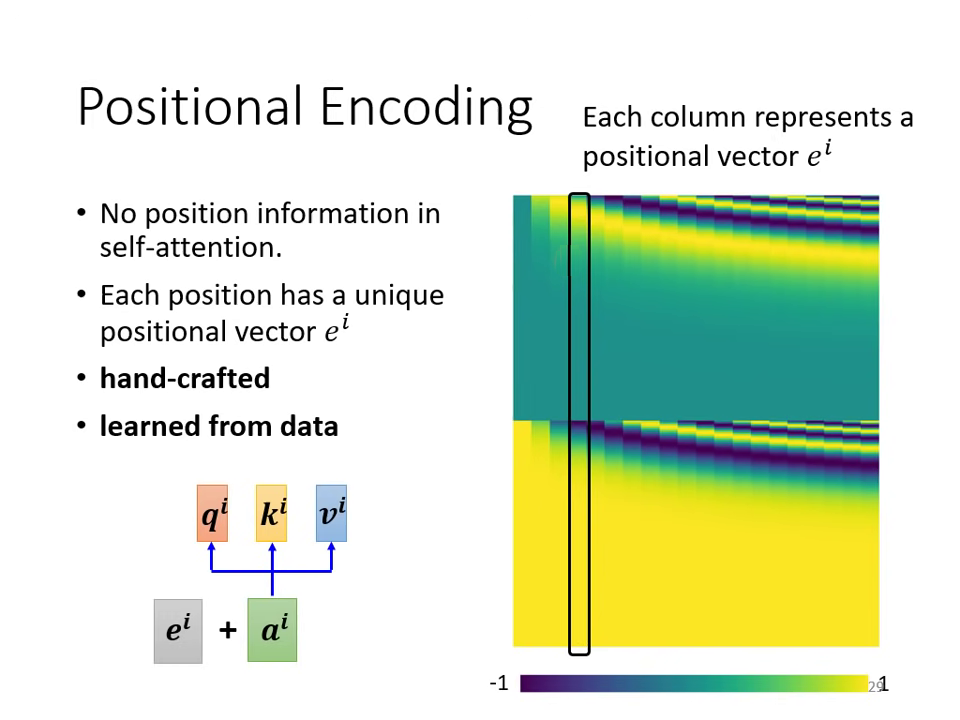
位置編碼 (Positional Encoding)
Self-attention 的原生操作中不包含位置資訊(對模型來說,輸入序列的順序不影響計算結果),但在許多任務中位置非常重要。
- 範例:在 詞性標註 (POS Tagging) 任務中,動詞較少出現在句首。若缺乏位置資訊,模型無法利用「句首詞彙較不可能是動詞」這一規律。
- 解決方法: 為每個位置設定一個獨特的向量 ,代表該位置在序列中的序號,並將其直接加到原始輸入向量 中。
- 現狀: 產生 的方法多元,包含人工設置(如透過固定公式產生的正餘弦函數)或讓模型自資料中學習。目前尚無定論哪種方法最優,仍是研究熱點。
Self-attention 的對比分析
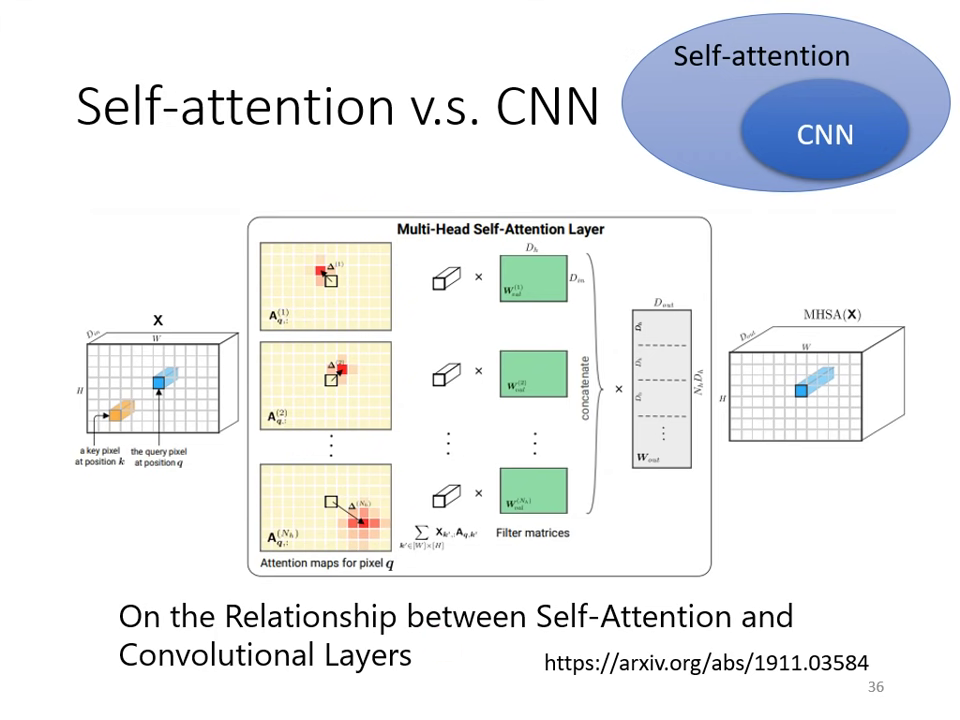
與卷積神經網路 (CNN) 的關係
- CNN 是簡化版的 Self-attention:CNN 透過人工劃定 感受野 (Receptive Field) 來限制神經元只考慮局部資訊;而 Self-attention 的感受野是透過機器自動學出來的,能考慮全圖資訊。
- 靈活性與資料量:
- Self-attention:模型彈性大(更 Flexible),但在資料量少時容易 Overfitting。
- CNN:模型彈性小且受限,適合在小型資料集(如 1000 萬張圖以下)發揮;當資料量達到 3 億張圖時,Self-attention 的表現會超越 CNN。
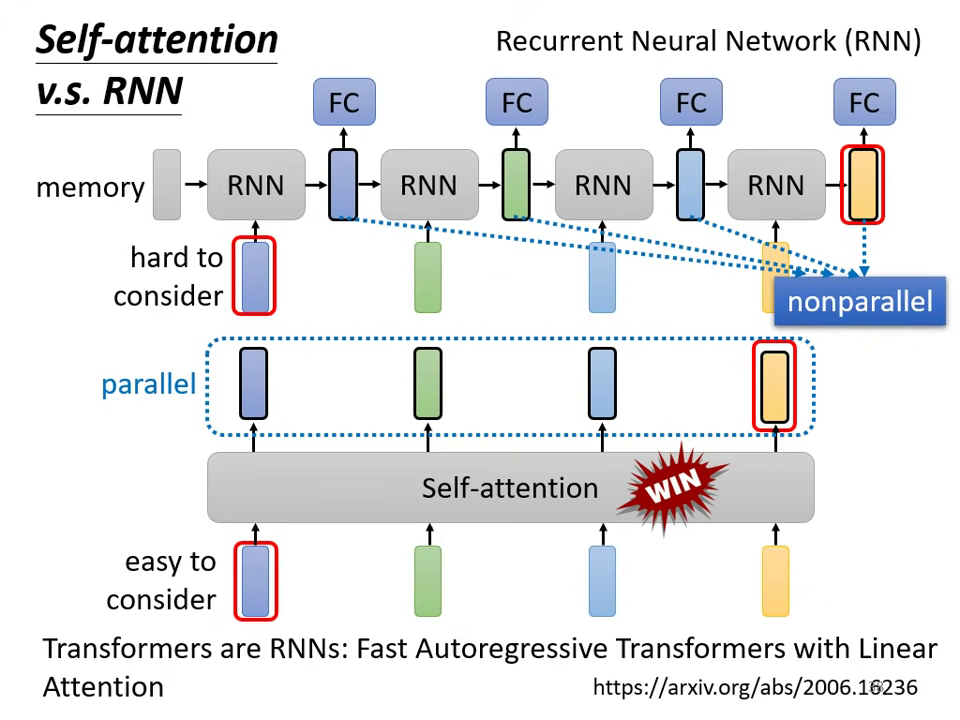
與循環神經網路 (RNN) 的關係
- 長距離處理能力:RNN 若要考慮序列最左邊的資訊,必須仰賴 memory 一路帶到最後,容易遺忘;Self-attention 則能輕易地從極遠的向量中抽取資訊。
- 運算效率(平行化):RNN 的輸出必須依序產生,無法平行化運算;Self-attention 的輸出向量則是同時產生,運算速度更有效率。
多領域應用與挑戰
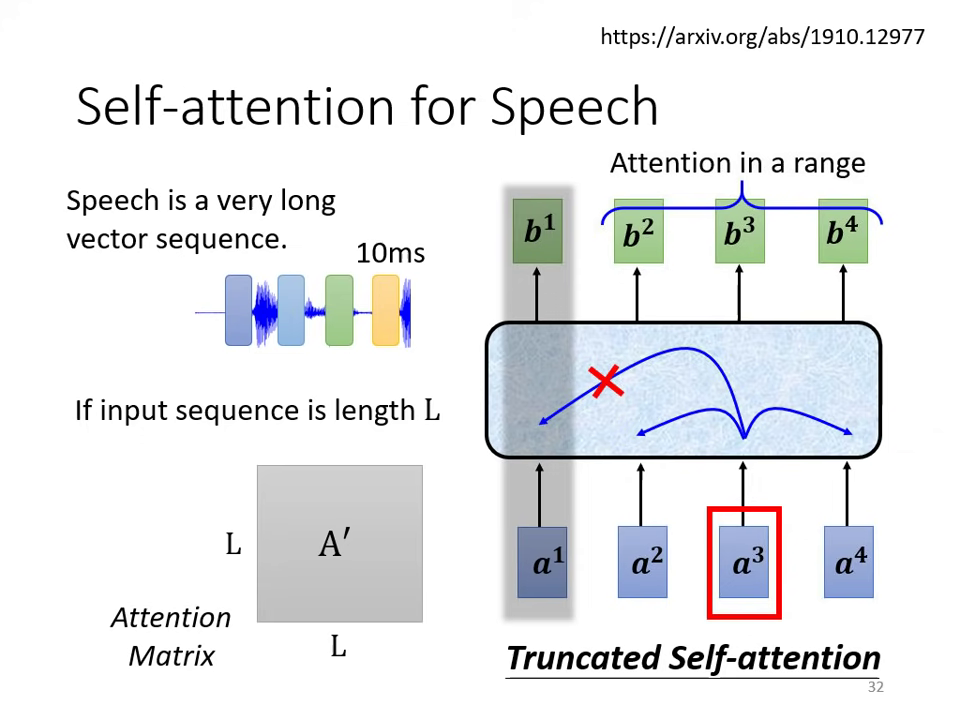
語音處理 (Speech)
- 挑戰:語音序列極長(1 秒約有 100 個向量),Self-attention 的計算複雜度是長度的平方 (),會消耗巨大運算量與記憶體。
- 解決方案:截斷式自注意力 (Truncated Self-attention),即只考慮當前位置前後的一定範圍,而非整句。
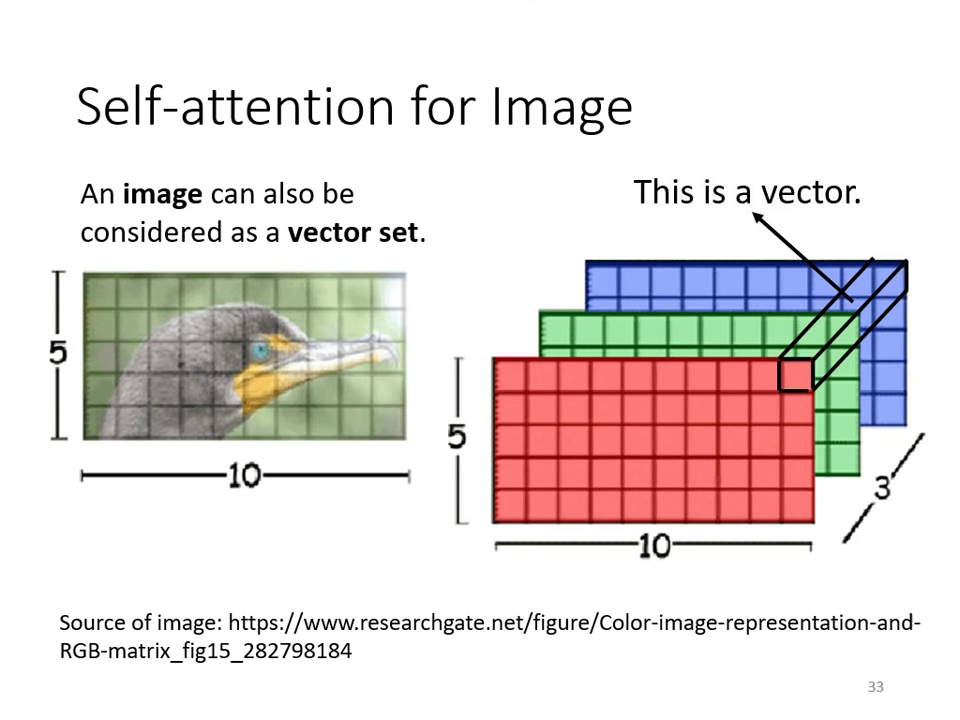
影像處理 (Image)
- 觀點轉換:一張圖片(如 像素)可看作是一個向量集合,每個像素點就是一個 3D 向量 (RGB)。
- 代表作:Google 的 ViT (An Image is Worth 16x16 Words) 將圖片切成多個 Patch 當作詞彙輸入 Self-attention。
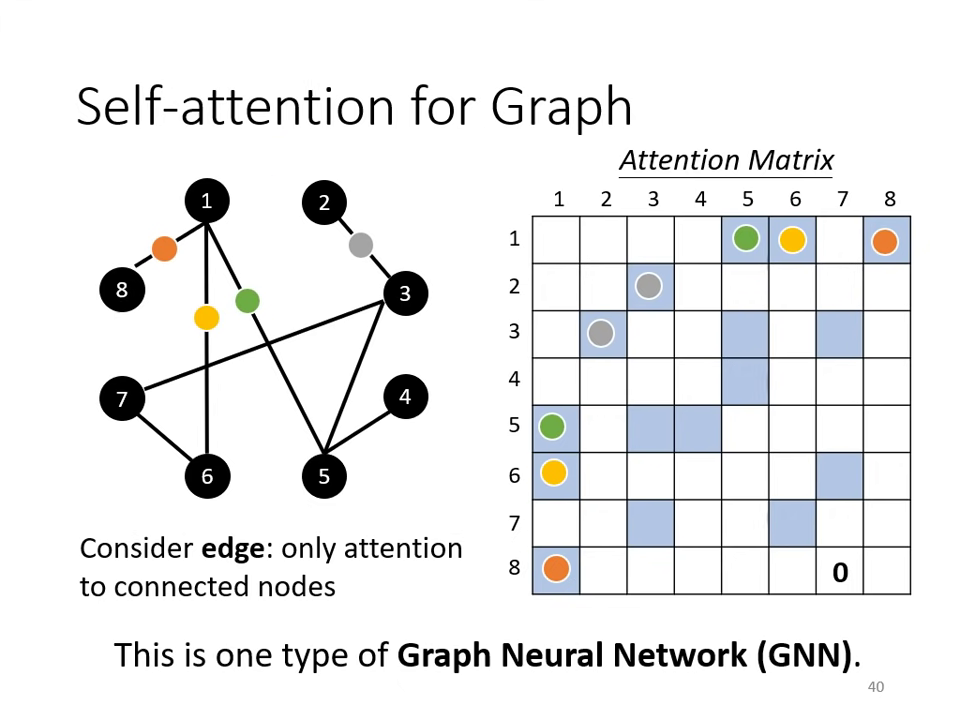
圖形結構 (Graph)
- GNN 的本質:將 Self-attention 用在 Graph 上時,可利用 Edge 資訊來限制計算。例如只計算有相連 node 間的 Attention 分數,沒相連的部分則設為 0。
- 優勢:結合 Domain Knowledge,不需由機器盲目學習所有關聯性。
進階與效率優化 (xxformer)
為了克服 Self-attention 運算量過大的問題,出現了許多變體(統稱為 xxformer):
- 目標:減少運算量以提升速度。
- 代表模型:Linformer、Performer、Reformer 等。
- 權衡 (Trade-off):通常運算速度愈快的模型,效能 (Performance) 會稍差一些,如何兼顧速度與準確度仍是尚待研究的問題。
