Transformer
Transformer 與 Seq2seq 模型概論
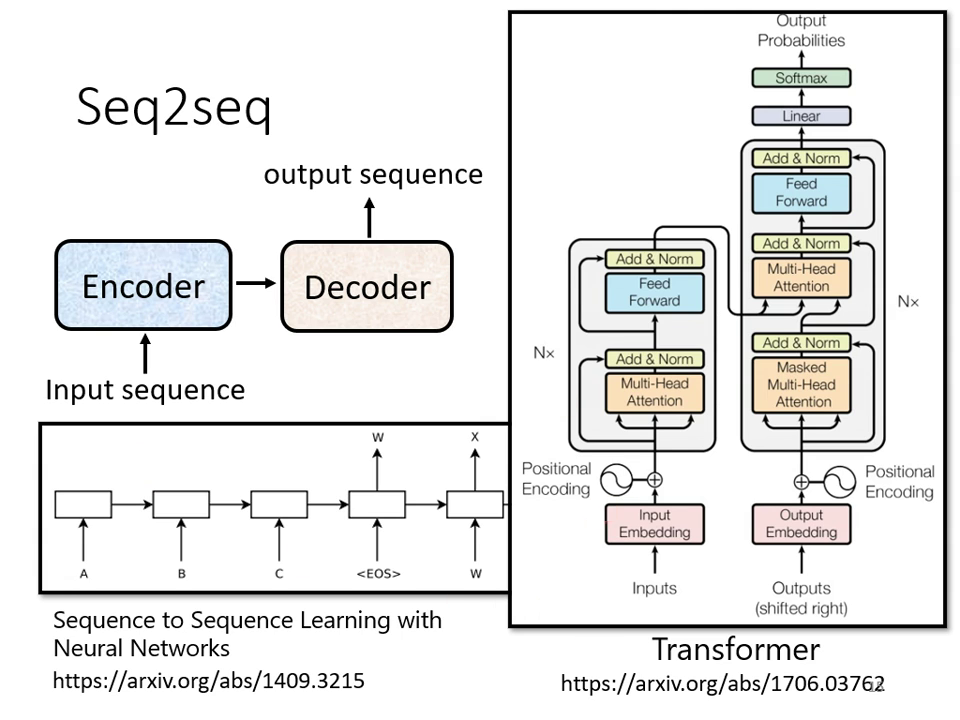
Transformer 本質上是一個 Sequence-to-sequence (Seq2seq) 模型,它與 BERT 有著強烈的關係。
什麼是 Seq2seq?
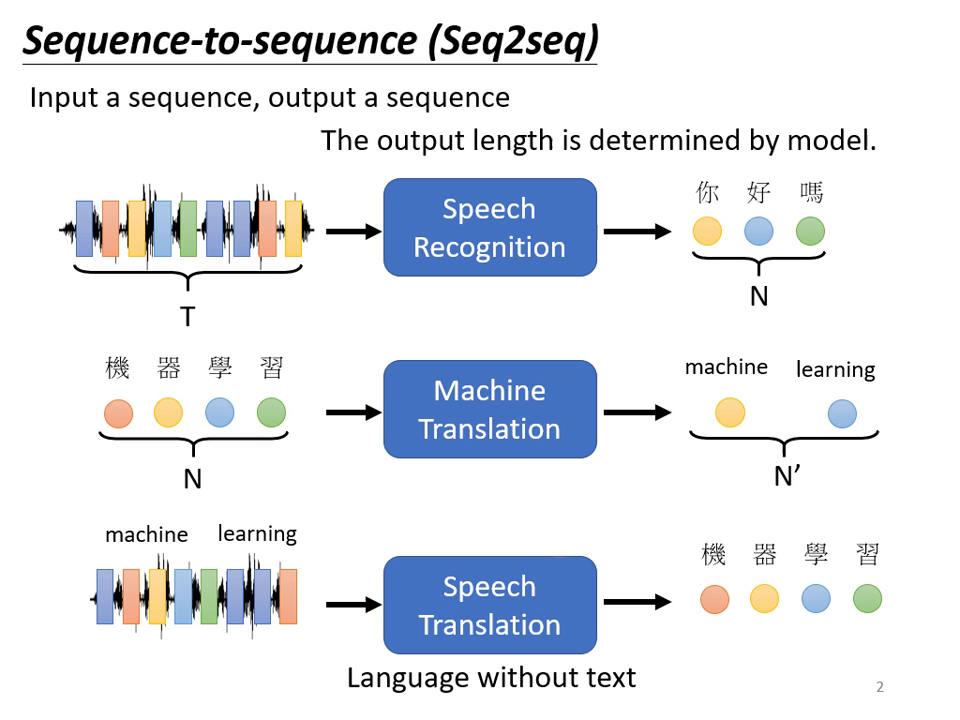
- 基本定義:輸入是一個序列 (Sequence),輸出也是一個序列,但輸出長度由機器自行決定。
- 核心組件:一般的 Seq2seq 模型分為 Encoder (編碼器) 與 Decoder (解碼器) 兩大部分。Encoder 負責處理輸入序列,並將結果交給 Decoder 決定最終輸出的序列。
Seq2seq 的多元應用
Seq2seq 是一個非常強大的模型,其應用範圍極廣:
- 語音辨識:輸入聲音訊號(向量序列),輸出對應文字,長度由機器決定。
- 機器翻譯:輸入一種語言的句子,輸出另一種語言。
- 語音翻譯:直接將聲音訊號翻譯為另一種語言的文字,這對於「沒有文字」的語言(如部分台語應用場景)特別有用。
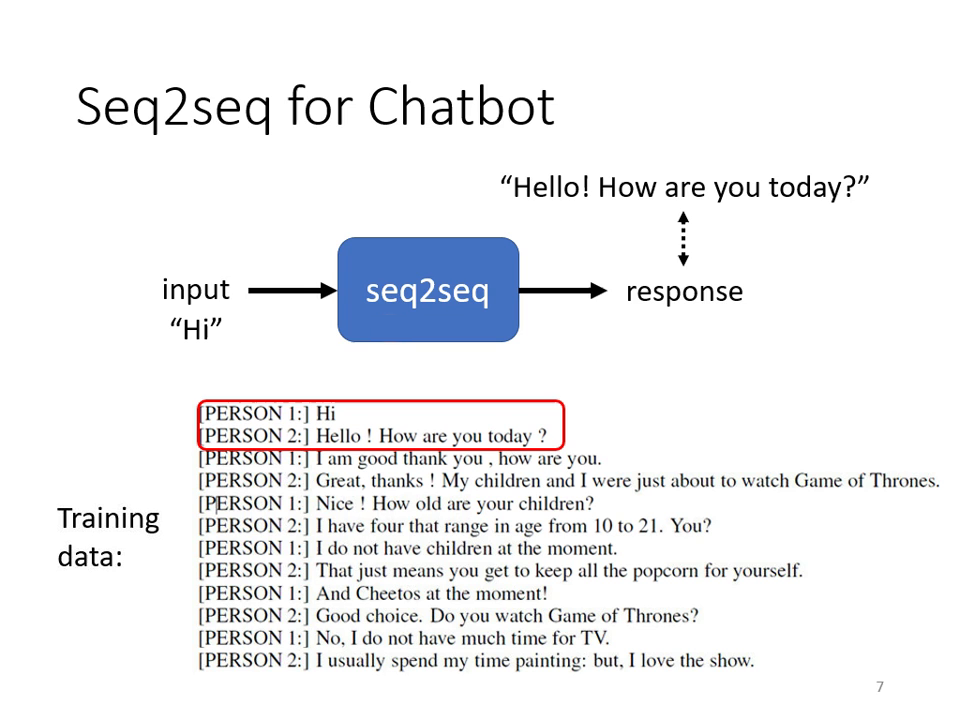
- 聊天機器人:輸入對話文字,輸出回應文字。
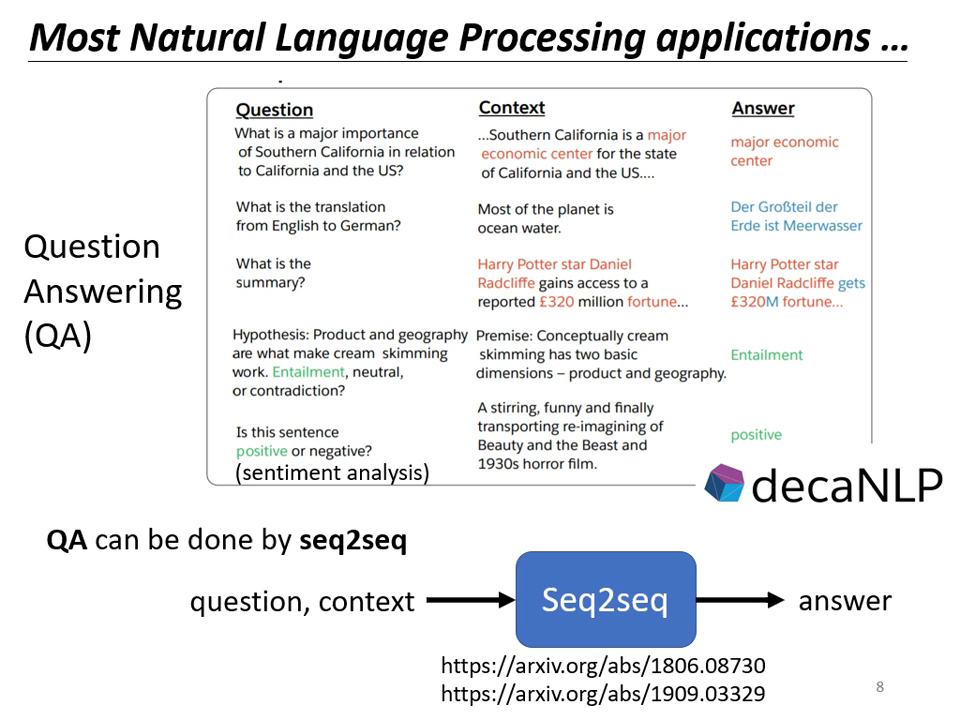
- NLP 任務轉 QA:許多自然語言處理任務(如摘要、情感分析)都可以看作是「問答問題」,進而使用 Seq2seq 求解。
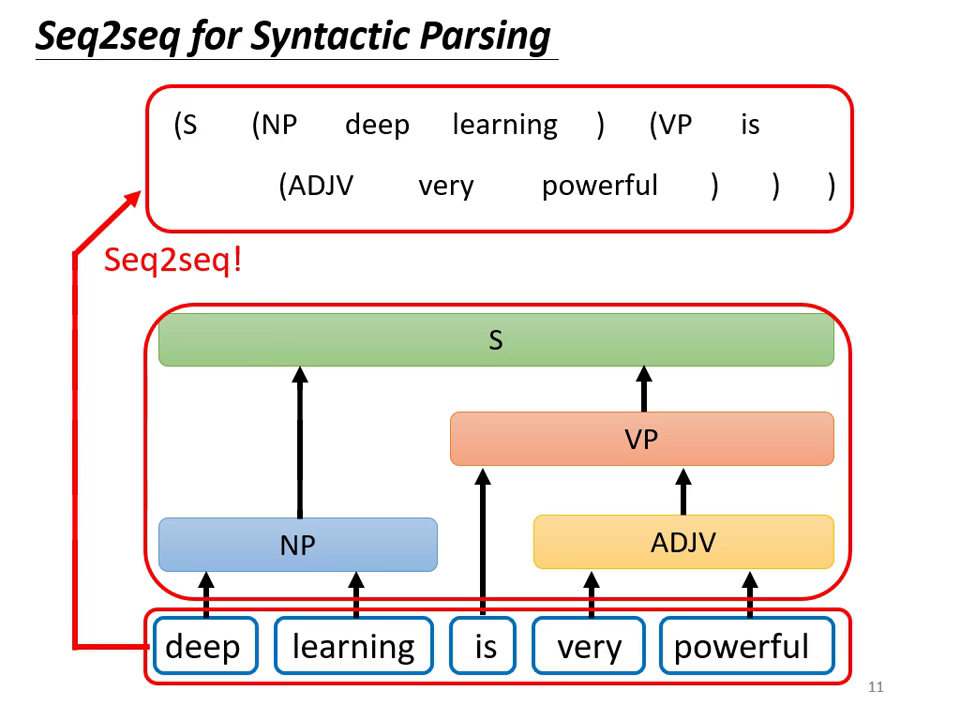
- 文法剖析 (Syntactic Parsing):將樹狀結構轉化為序列後,可用 Seq2seq 硬解。
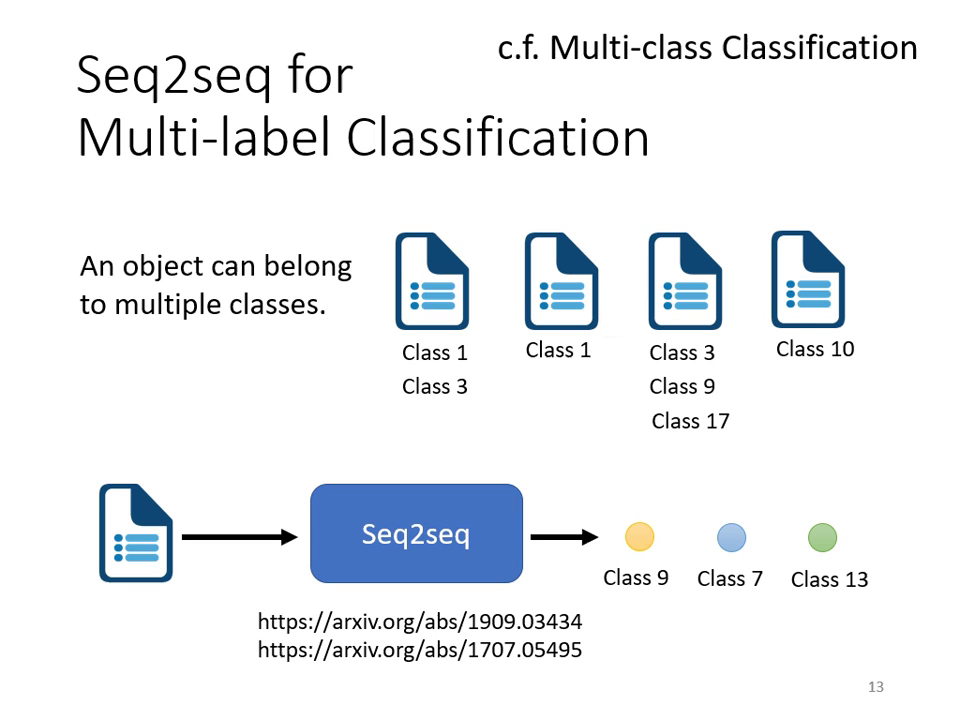
- 多標籤分類 (Multi-label Classification):機器能自行決定一篇文章屬於多少個類別,解決傳統分類難以決定門檻值的問題。
- 物件偵測 (Object Detection):雖然看似不相關,但亦可使用 Seq2seq 的邏輯硬解。
注意:雖然 Seq2seq 像「瑞士刀」般萬用,但在特定任務(如語音辨識)中,客製化模型(如 RNN Transducer)往往能表現得更好。
 |  |  |
|---|---|---|
| 語音辨識、機器翻譯、語音翻譯 | 語音合成 | 聊天機器人 |
 |  |  |
|---|---|---|
| NLP 任務轉 QA | 文法剖析 | 多標籤分類 |
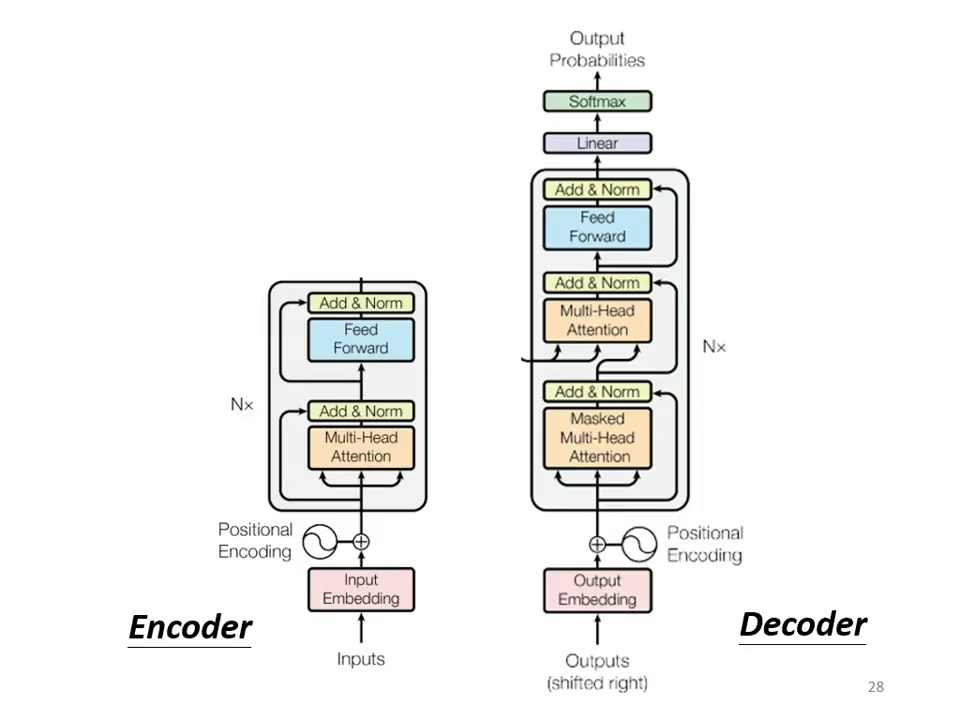
Transformer Encoder 架構解析
Encoder 的主要任務是:給入一排向量,輸出另外一排同樣長度的向量。在 Transformer 中,Encoder 由多個 Block 重複堆疊而成,每個 Block 並非單一層的神經網路,而是包含多個層級的複雜結構。
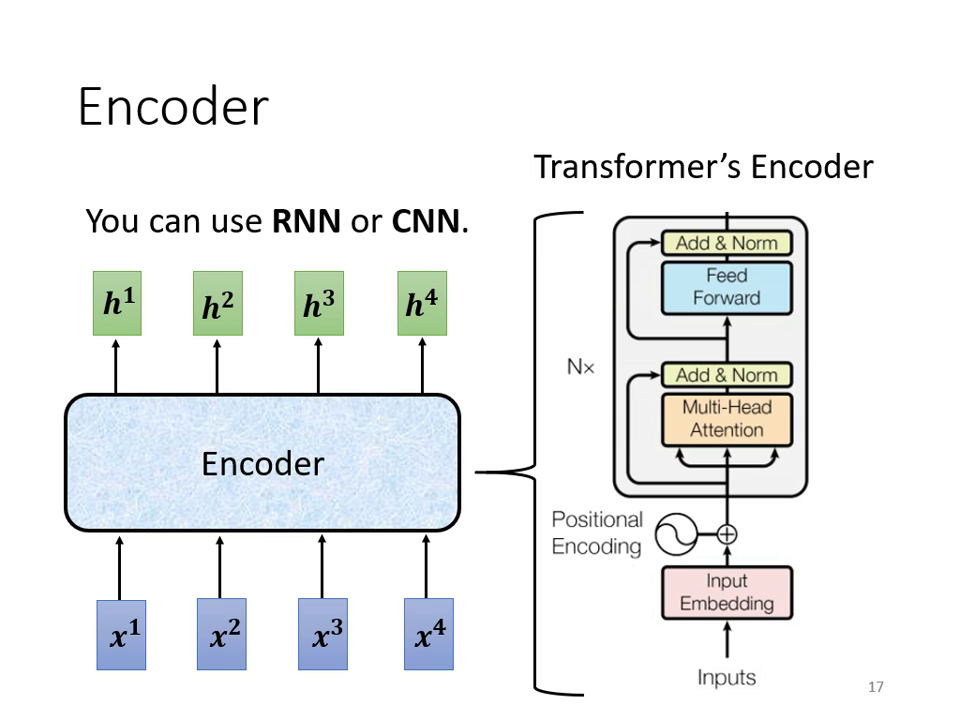
Encoder Block 的組成元素
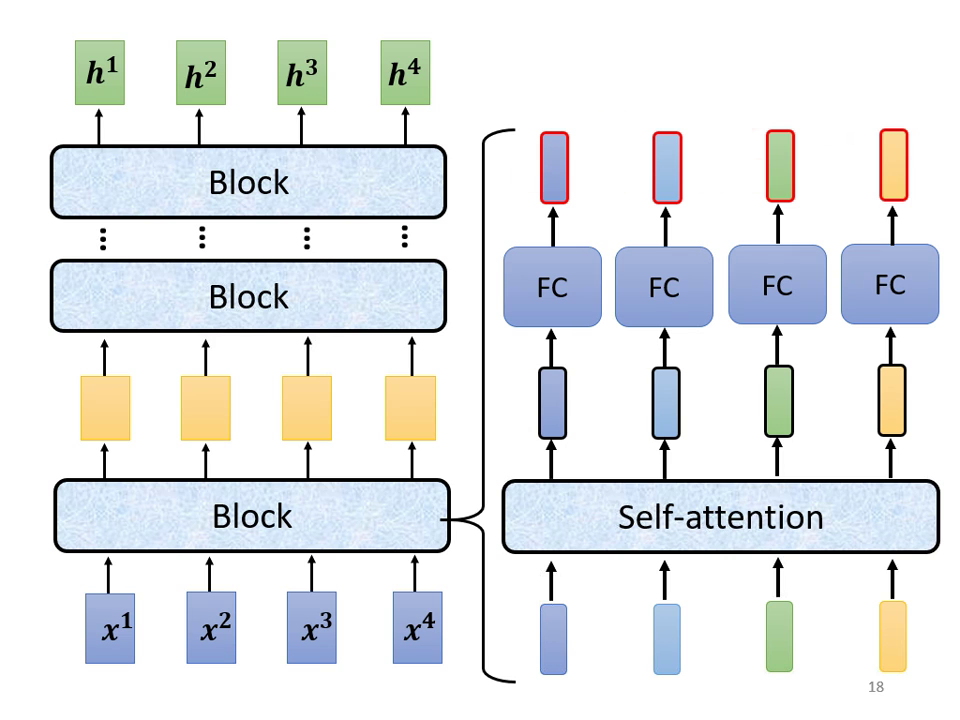
每一個 Block 內部主要執行以下步驟:
- 多頭自注意力 (Multi-Head Self-attention):考慮整個序列的資訊,輸出處理後的向量。
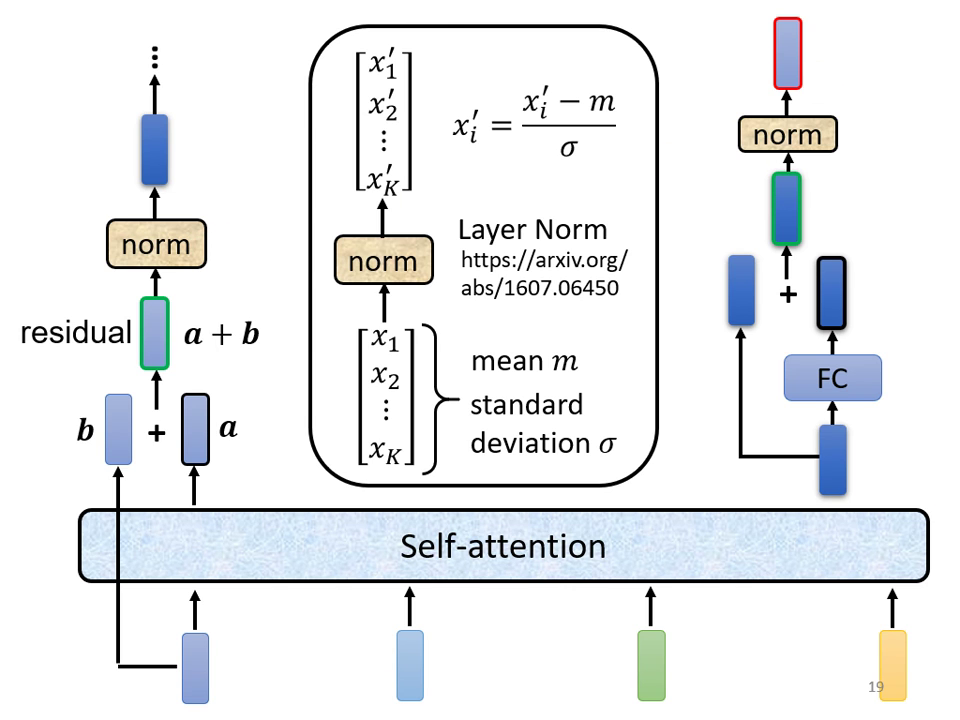
- 殘差連接 (Residual Connection):將 Self-attention 的輸出與原始輸入相加,得到新的結果。
- 層正規化 (Layer Normalization):
- 與 Batch Normalization 不同,Layer Norm 不需要考慮 Batch 資訊。
- 它是針對「同一個 example、同一個 feature」中不同的維度 (Dimension) 計算平均值 (Mean) 與標準差 (Standard Deviation)。
- 前饋神經網路 (Feed Forward Network):通過全連接層 (Fully Connected Network) 進一步處理向量。
- 第二次殘差連接與正規化:將前饋網路的輸入與輸出相加,再次進行 Layer Normalization 後輸出。
 |  |
|---|---|
| 每個 block 以 Self-attention 整合序列後,經 FC 輸出向量 | Self-attention 與 FC 各自搭配 residual connection 與 layer normalization,逐步產生輸出向量 |
Transformer Decoder 架構解析
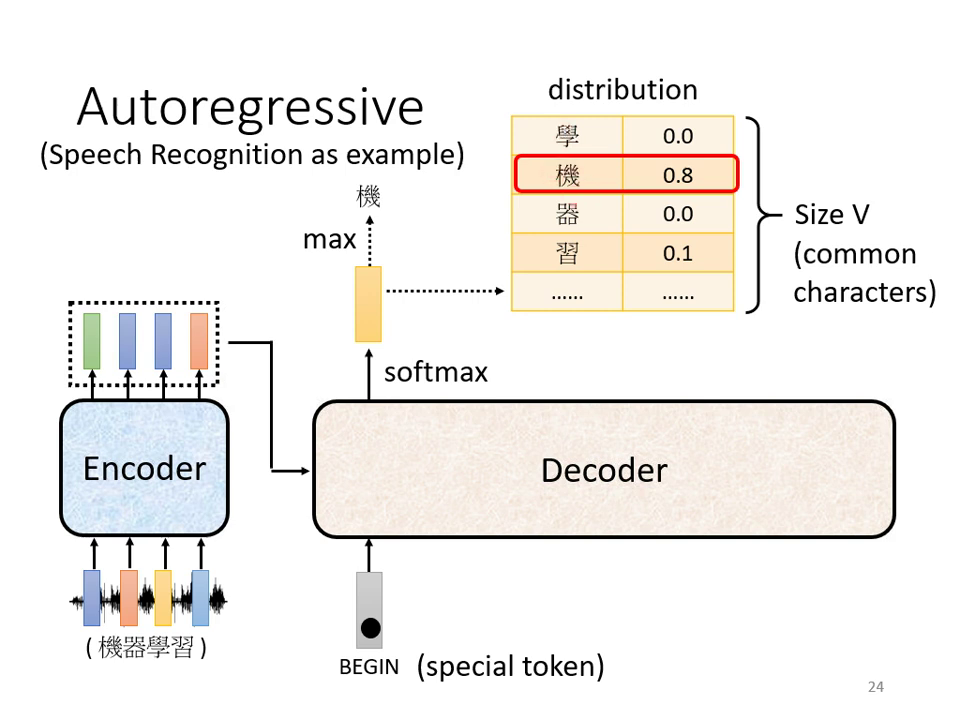
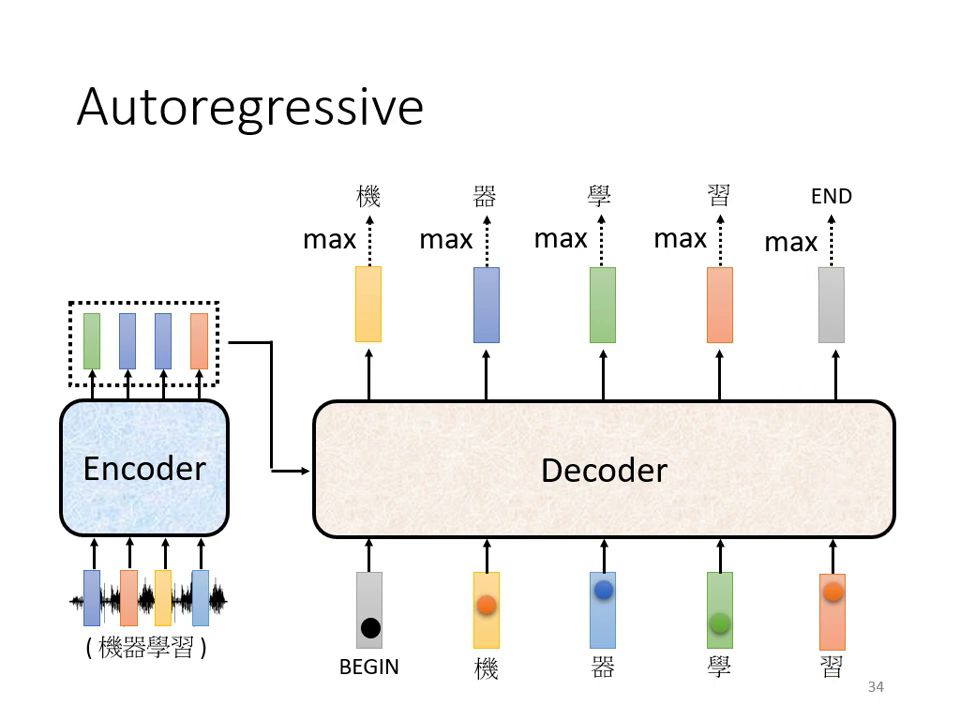
Decoder 的主要任務是根據 Encoder 的輸出抽取出資訊,並產生最終的序列結果。目前最常見的是 Autoregressive (AT) 的運作方式:
- 逐字產生:Decoder 一次只產生一個字(Token),且前一個時間點的輸出會成為下一個時間點的輸入。
- 起始符號 (BOS/BEGIN):開始運作時,需給予一個特殊符號代表「開始」(如 BOS 或 BEGIN),通常以 One-Hot 向量表示。
- 輸出機率分佈:Decoder 的輸出會經過 Softmax,得到一個與詞彙表(Vocabulary)等長的向量,代表每個字出現的機率。機率最高者即為該時間點的輸出。
- 終止符號 (END):為了讓機器知道何時停止,詞彙表中需加入一個特殊符號(如 END 或 斷)。當機器輸出此符號時,便結束生成過程。
 |  |
|---|---|
Decoder 以 Encoder 輸出與 <BOS> 為起點,逐步生成 token | 逐步輸出 vocabulary 分佈,選擇最高機率的 token,重複直到產生 <EOS> |
Decoder 內部結構
Decoder 的結構與 Encoder 類似,同樣包含 Residual Connection 與 Layer Normalization,但有兩個關鍵差異:
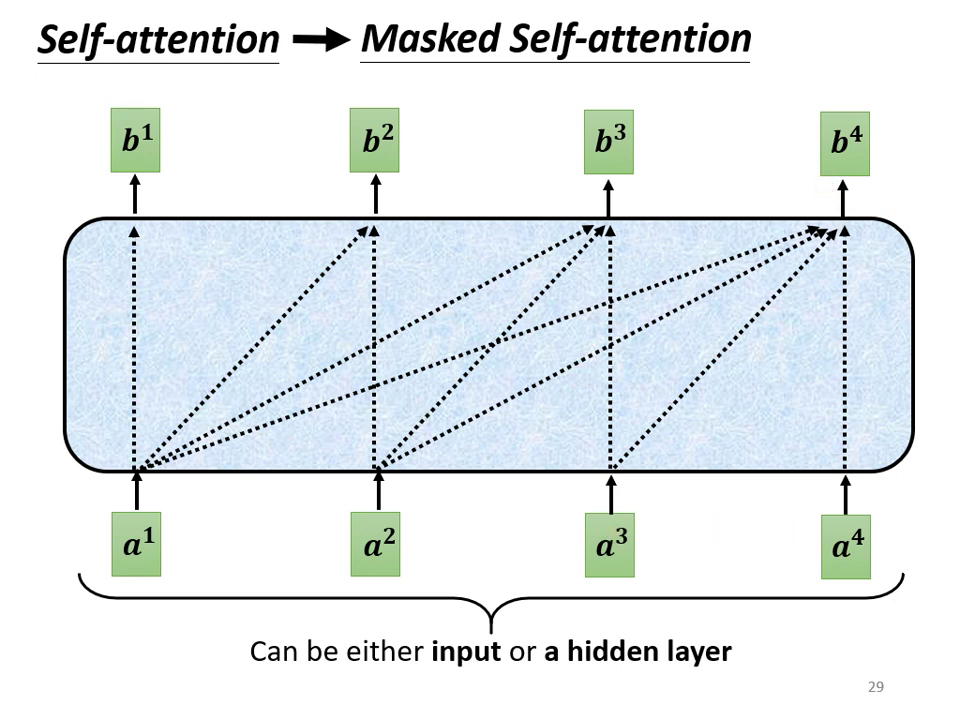
- Masked Self-Attention:
- 定義:這是一種特殊的自注意力機制,在產生輸出時,模型只能考慮左側(已產生)的資訊,不能看到右側(未產生)的資訊。
- 原因:在實際產生序列時,未來的字尚未出現,因此無法被考慮。
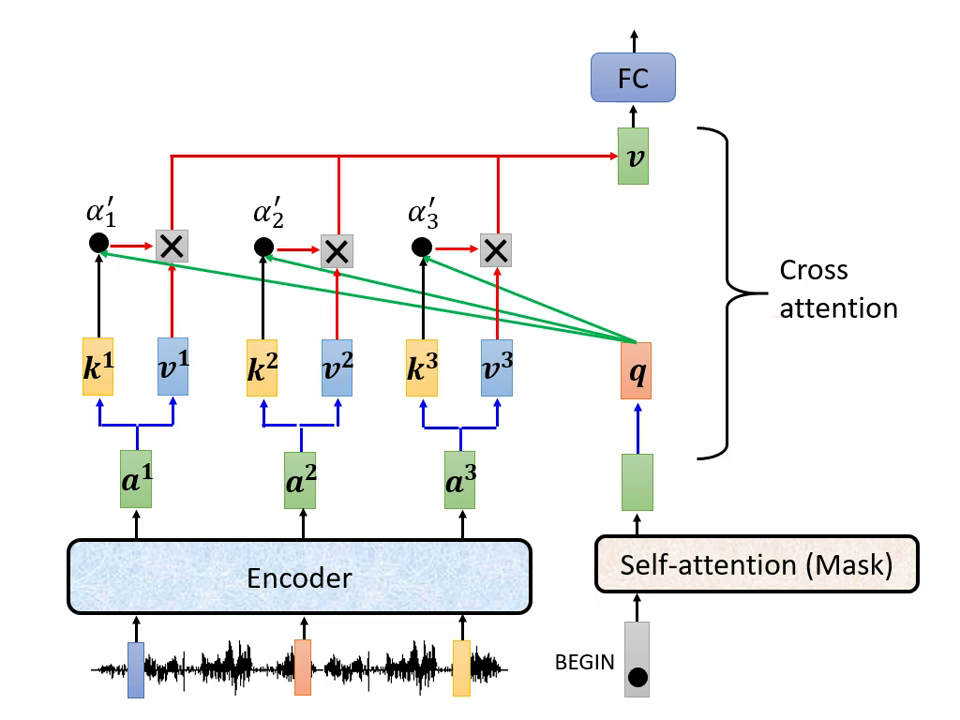
- Cross Attention (交叉注意力):這是連接 Encoder 與 Decoder 的橋樑
- 運作邏輯:Decoder 產生一個 Query (),去 Encoder 輸出的 Key () 與 Value () 中抽取資訊。
- 多層互動:在原始論文中,Decoder 的每一層都會去讀取 Encoder 最後一層的輸出,但研究指出這並非唯一連接方式。
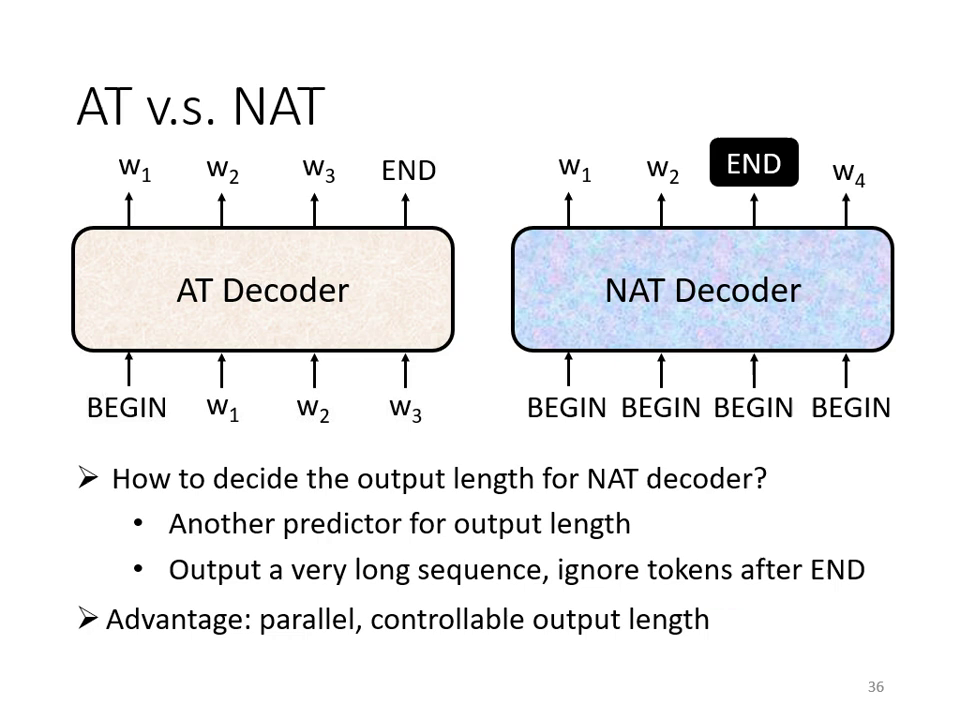
非自迴歸解碼器 (Non-Autoregressive, NAT)
相對於 AT,NAT 一次產生整個序列:
- 優勢:平行化運算速度極快,且較能精準控制輸出長度(例如語音合成時的語速調整)。
- 挑戰:效能通常不如 AT,且需要複雜的技巧(如處理 Multi-modality 問題)才能逼近 AT 的表現。
- 長度預測:由於是一次產生,通常需另一個分類器來預測輸出的長度。
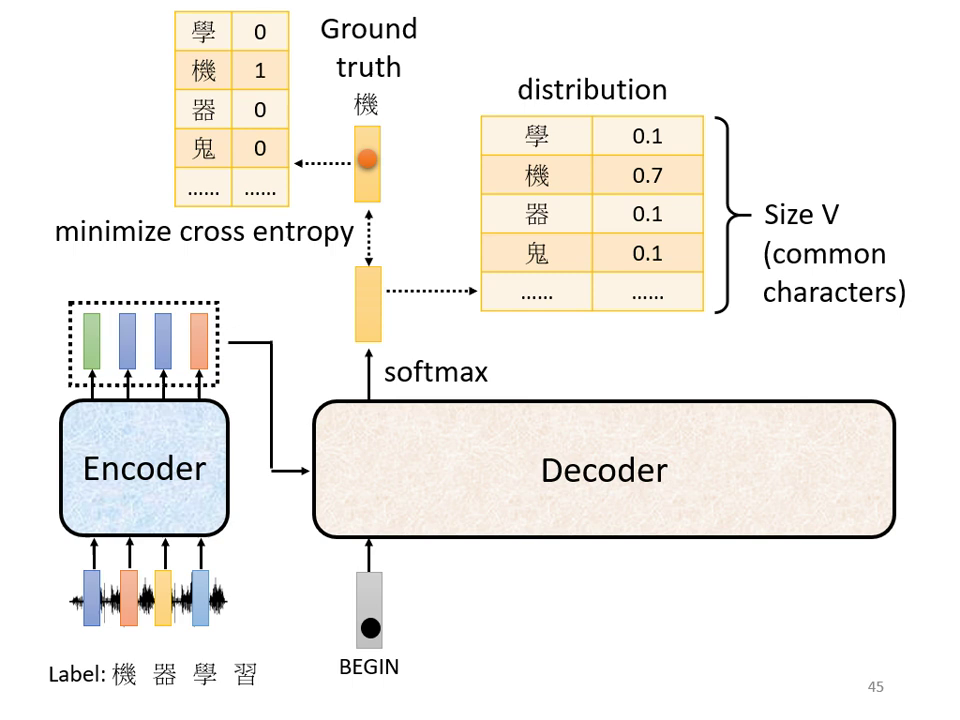
Transformer 訓練過程
- 訓練資料:
- 需要大量的成對資料,例如「一段音頻」與其對應的「正確文字」(如工讀生聽打的結果)。
- 文字會被表示成 One-hot encoding 的向量,其中正確字所在的維度為 1,其餘為 0。.
- 訓練目標與流程:
- 輸出分布:Decoder 的輸出會經過 Softmax 轉換成機率分佈(Distribution),其總和為 1。
- 損失函數:每一次 Decoder 產生輸出時,就是在做一次分類問題。我們會計算輸出的機率分布與 Ground Truth 之間的 Cross Entropy。
- 優化優化:透過最小化序列中所有位置(包含最終的「斷」符號)的 Cross Entropy 總和,實現梯度的優化,使模型輸出越接近正確答案越好。
- 學習停頓:訓練時必須教導模型在正確位置輸出特殊符號「斷」(END),代表語音辨識或翻譯任務已經結束。
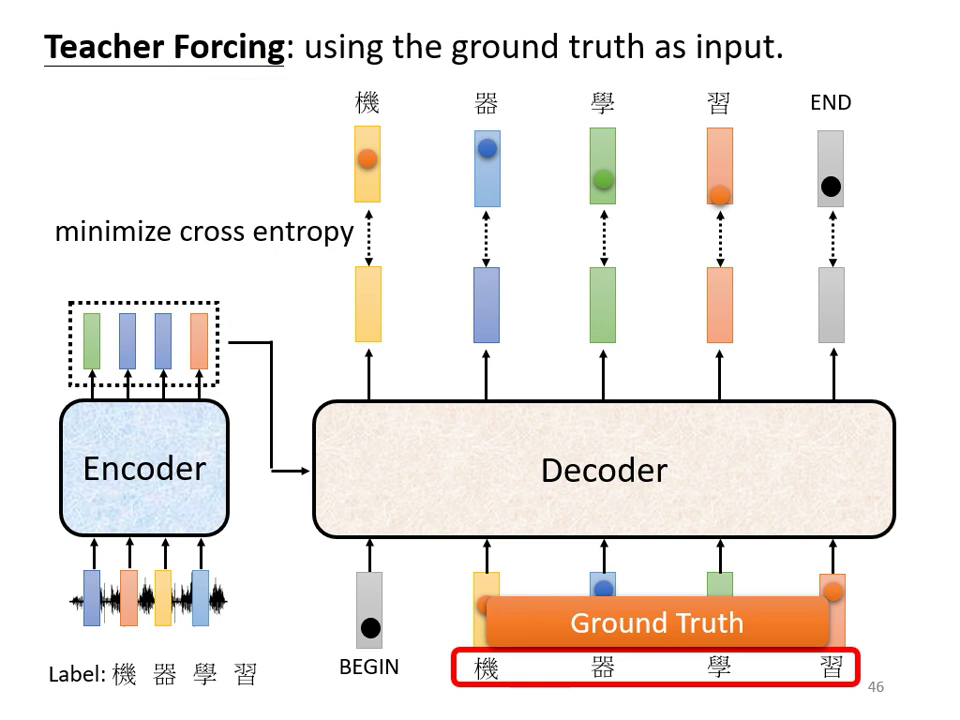
訓練核心挑戰與對策
- Teacher Forcing: 在訓練 Decoder 時,輸入的是正確答案(Ground Truth)而不是前一個時間點自己產生的答案。這能讓模型在學習初期更有效地對準正確目標。
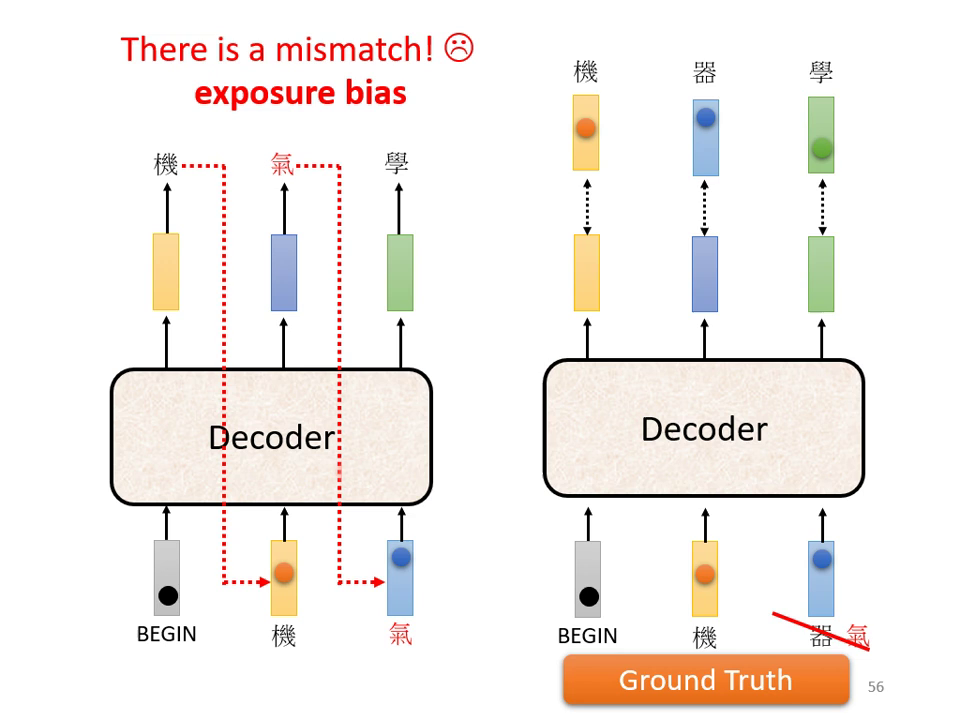
- 暴露偏差 (Exposure Bias): Teacher Forcing 導致訓練與測試(Inference)不一致。測試時 Decoder 看到的是自己產生的錯誤輸入,這可能導致「一步錯,步步錯」。
- 解決方案 (Scheduled Sampling): 為了修正此問題,可以在訓練中適度混入錯誤的答案(Scheduled Sampling),讓模型學習如何應對非正確的輸入,增加強健性。
 |  |
|---|---|
| Teacher Forcing | Scheduled Sampling |
訓練技巧
複製機制 (Copy Mechanism)
- 對於聊天機器人或摘要任務,模型不需「創造」新詞,而是從輸入中直接複製特定詞彙(如人名)。

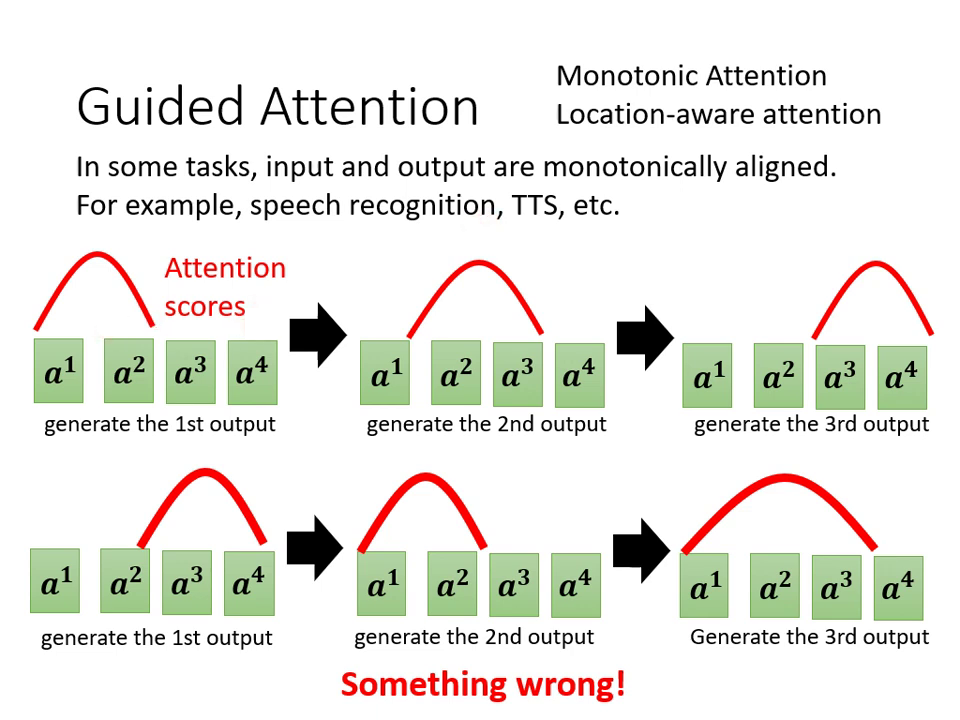
導引式注意力 (Guided Attention)
- 在語音合成或辨識中,要求 Attention 必須呈現固定的由左向右線性關係,避免漏字或重複。
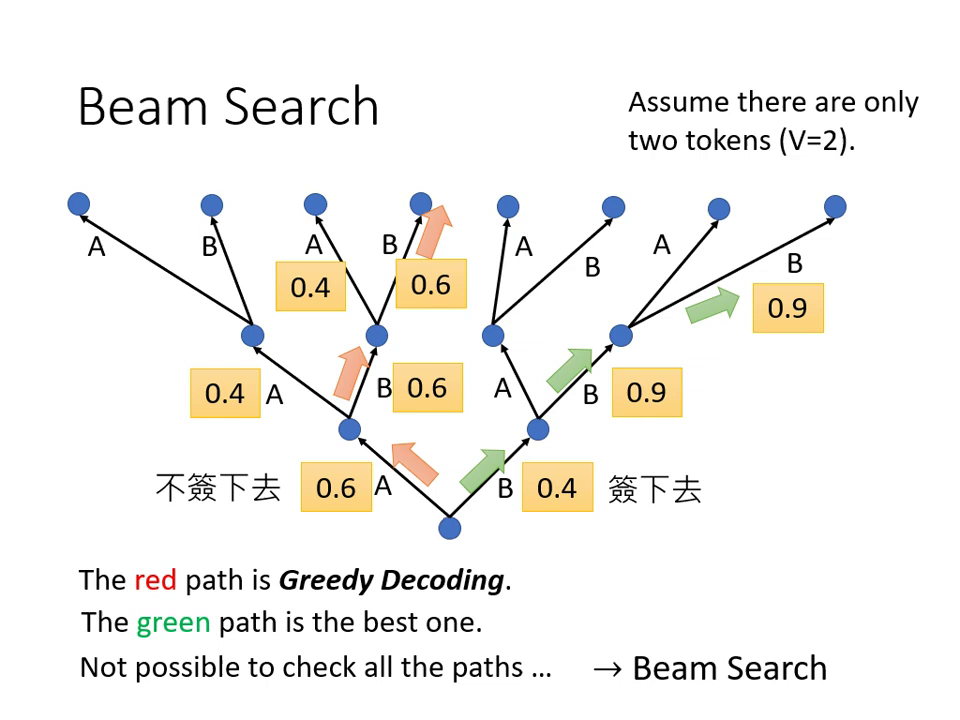
束搜尋 (Beam Search)
- Greedy Decoding 每次只找機率最高的字,但不一定能得到全局最優序列。
- Beam Search 會保留數條機率較高的路徑進行搜尋。
- 注意:在需要創造力的任務(如故事生成)或語音合成中,有時加入隨機性 (Noise) 反而比尋找最高分路徑效果更好。
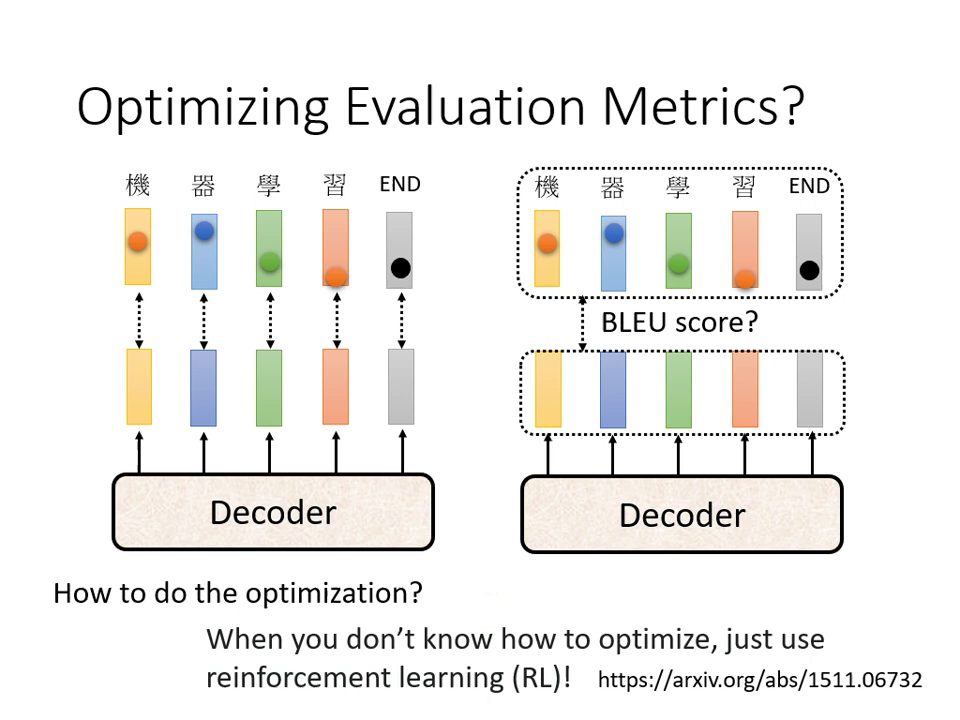
優化目標:Cross Entropy vs. BLEU Score
- 訓練時通常最小化 Cross Entropy(逐字計算),但評估標準通常是 BLEU Score(整句比較)。
- 由於 BLEU Score 無法微分,若要直接優化 BLEU Score,通常需要使用強化學習 (RL) 技術。